






大纲
1.动机
2.贝叶斯理论
3.MAP-/ML假设
4.优化的贝叶斯分类器
5.幼稚的贝叶斯分类器
6.例子
7.贝叶斯网络
8.EM算法
9.总结
动机
什么是贝叶斯学习
他是一种统计学习方法,他具有以下的特点:
1.结合已有的信息(前验概率)和观察到的信息
2.通过贝叶斯可以获得对应观察的假设,以及这个假设成立对应的概率
(Hypothesen können mit einer Wahrscheinlichkeit angegeben werden)
3.每个例子都可以提高或者降低一个存在的例子的可靠性(无一例外)
(Jedes Beispiel kann die Glaubwürdigkeit einer bestehenden Hypothese erhöhen oder verringen:
→
kein Ausschluss bestehender Hypothesen)
4.可以通过同时评价多个可能的假设,来获得更加精确的结果
动机
1.他是一种很好得学习方法
2.他也可以作为其他学习方法的组成部分
实际应用时可能的难点
1.需要很多初始知识(像前验概率啊什么的)
(Initiales Wissen über viele Wahrscheinlichkeiten notwendig.
Aber:oft Schätzung basierend auf Hintergrundwissen, vorhandenen Daten, etc. möglich)
2.优化的贝叶斯假设的计算量很大
(Erheblicher Rechenaufwand für optimale Bayes’sche Hypothese im allgemienen Fall
Linear mit Anzahl der möglichen Hypothesen
Aber:In speziellen Fällen deutliche Reduzierung des Rechenaufwand möglich)
贝叶斯理论
一般概率理论
针对互斥的事件 A1,...,An,∑ni=1P(Ai)=1 有:
贝叶斯理论
P(h)表示先验概率(或叫边缘概率),他与观察无关,表示假设空间中选中假设h的概率
P(D | h)表示条件概率,指当h成立时观察到D的概率
P(D)表示观察到事件D的概率,他与假设无关。根据求和定理,他是所有P(D|h)的和
P(h|D)表示后验概率
例子:医学诊断
被略
MAP(Maximum a posteriore Hypothese)假设与ML(Maximum Likelihood)假设
目标:根据观察到的事件D,从假设空间H中选出概率最大的假设。
如果上式中每个假设出现的概率是相同的,那么我们就得到了相应的ML假设:
例子:医学诊断
已知关于癌症的知识有:
根据MAP: hMAP=argmaxh∈HP(D|h)P(h) 对于一个检验报告为+的新的病人我们可以得到下面的结果:
可以看出整个假设空间一共有两个假设,分别是1.患有癌症 2.没有癌症。根据MAP假设二是我们要得结果。(好吧,原来检测结构为正,也不能说明得了癌症的啊)
学习方法
暴力美学
1.计算每一个假设的后验概率
2.选出其中使后验概率最大的那个假设
//这就是计算而已啊,为什么叫学习呢??是我弄错了吗??学习的目的就是找出最优假设
概念学习(Konzeptlernen)
//这课件真得是一个人编的吗???
针对的问题是:
1.H是针对实例X的有限的假设空间
2.目标是找出目标假设c:
X→
{0,1}
//
X→
{0,1}表示理解不能,不应该是映射到D的吗????因为是Konzept,所以对应的值域只有{0,1},表示对应事物的存在与否。??
3.确定的实例序列:X=
<x1,...,xm>
<script id="MathJax-Element-13" type="math/tex">
</script>
4.目标序列:D=
<d1,...,dm>
<script id="MathJax-Element-14" type="math/tex">
</script>
为了简化问题,我们进行以下假设:
1.训练数据没受到干扰,也就是说
di=c(xi)
//训练数据不应该是X,D对吗??为什么就是D了????
2.c包含在假设空间H中
3.每个假设的先验概率相等
(Kein Grund a priori anzunehmen, dass irgendeiner Hypothese wahrscheinlicher ist als eine andere)
根据上面的问题设定,我们有:
根据上述条件,我们可以得出对应的后验概率,分为两种情况:
1. h(xi)=di (konsistente Hypothesen)
2.other:
其中 VSH,D 为假设空间H中,符合条件的假设的数量
(Menge der h aus H, die konsistent mit D sind(Versionenraum von H??))
/*感觉上面就是要得全部了,下面还有一个定义
Definition:Ein lernverfahren ist ein konsistenter Lerner, wenn es eine Hypothese liefert, die keine Fehler auf den Trainingsdaten macht.
Unter obigen Voraussetzungen gibt jeder konsistente Lerne eine MAP-Hypothese aus
Methode um induktiven Bias auszudrücken???
*/
例子:学习实数方程
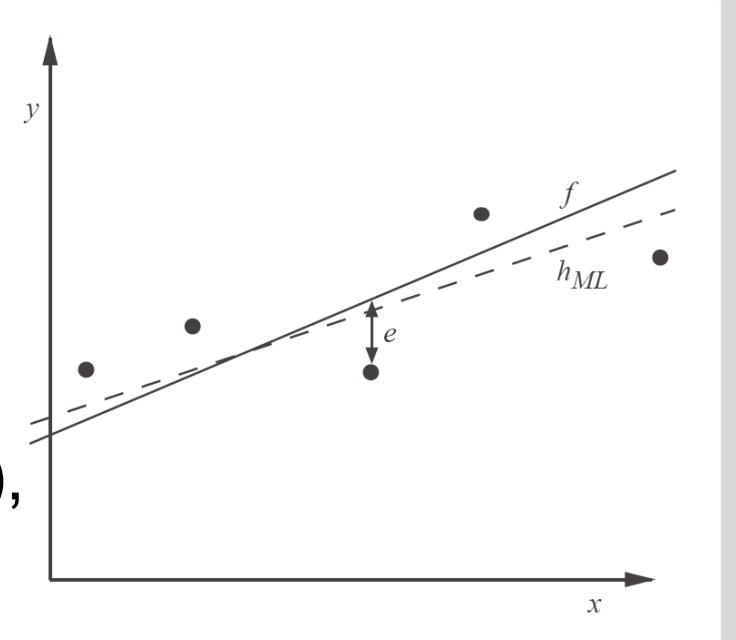
寻找的目标是:实数方程f
已知的是:受干扰的
<xi,di>
<script id="MathJax-Element-21" type="math/tex">
</script>对,也就是说:
1.
di=f(xi)+ei
2.
ei
是干扰项(随机变量),他的取值和
xi
无关,他的分布符合中值为0的正太分布。
由上面的条件,我们可以得到
hML
满足下面这条式子:
上面这条式子是怎么来得呢??下面是过程:
//因为e=d-h,且e符合中值为0的正太分布
优化的贝叶斯分类器
前面在讲得一直是如何选出最优的假设,但要知道
hMAP(x)
并不一定是最可能的分类,那么对一个新的实例x,我们要怎么对其进行分类呢???
一个例子先说明为什么
hMAP(x)
不一定是最可能的分类:
//所以前面说那么多MAP啊ML啊的东西究竟有什么意思???
优化的贝叶斯分类器
根据下式进行分类
例子:
优化的贝叶斯分类器的优缺点
优点:
在相同假设空间以及基本知识的条件下,不存在平均效果比它更好得分类器了。
(Kein anderes Klassifikationsverfahren (bei gleichem Hypothesenraum und Vorwissen)schneidet im Durchschnitt besser ab.)
缺点:
当假设空间比较大使得他花费是相当可观的。
Gibbs算法
1.根据P(h|D),随机从H中选出假设h
2.把h(x)作为x的分类
3.确定其期望值
上面这种算法在特定的假设下满足:
幼稚的贝叶斯分类器
已知:
1.实例x:
<a1,a2,...,an>
<script id="MathJax-Element-34" type="math/tex">
</script>是属性a的交集(Konjunktion von Attributen)
2.类集合(有限的)V={
v1,...,vm
}
3. 训练数据,分类例子的集合
目标:
针对输入实例的最可能的类
其中:
P(vi) 可以通过数数比较容易得到
P(a1,a2,..,an|vj) 考虑到属性a的各种结合方式,这个对训练数据的要求比较高啊
因此我们对上式进行简化,我们假设属性 ai 之间是非条件关联的( ai bedingt unabhängig):
由此我们得到了一个幼稚的(简化了的)贝叶斯分类器:
非条件关联(bedingte Unabhängigkeit)
如果有:
那么我们就说X在给定Z的条件下与Y非条件关联
/*定义原文
X ist bedingt unabhängig von Z gegeben Z ,wenn die Wahrscheinlichkeitsverteilung von X bei gegebenem Wert von Z unabhängig vom Wert von Z ist.
*/
总结
1.
P(vj),P(ai|vj)
都是数出来的
2.分类的概率和假设相对应
(Wahrscheinlichkeiten für Klassifikation enspricht gelernter Hypothese)
3.新的实例会通过MAP规则进行分类
4.当满足非条件关联时NB分类和MAP分类等价
(Keine explizite Suche im Hypothesenraum???)
//课件里有一例子,S31
问题(Schätzen von Wahrscheinlichkeiten)
假如类型为
vj
的训练数据中属性值为
ai
的一次也没有出现怎么办???
解决方法:使用Laplace估值(好像叫平滑定理来着的)(m-Laplace Schätzer)
其中:
n为例子中 v=vj 的数量
nc 为例子中 v=vj,a=aj 的数量
p是 P(ai|vj) 的前验概率,比如:p= 1Value(ai)
m表示虚假例子的数量(virtuellen Beispiele)
例子:文章分类
好吧其实只是区分为感兴趣和不感兴趣两类,更像是垃圾邮件分类:Document
→
{+,-}
1.用由单词组成的向量表示文章,每个位置都是一个表示属性
(Repräsentation jedes Textes als Vektor aus Wörtern:Ein Attribut pro Wortposition im Dokument)
2.学习阶段:通过训练数据估计下面值:P(+),P(-),P(doc|+),P(doc|-),其中有
P(ai=wk|vj) 为在给定 vj 的条件下单词 wk 在位置 ai 出现的概率
另外加上一个弱化条件bag of words:
/*?????
给跪了,翻译过来就是 wk 在第i个位置出现的概率等于其在第m个位置的概率,针对任意的i,m。也就是说这个单词在每个位置出现的概率是相同的???
另外为什么整个doc的概率就由一个单词来决定???
感觉下一页ppt和这一页有点接不上???
*/
搜集vocabulary:
计算每个类 vj 对应的 P(vj),P(wk|vj) :
//感觉和前一页的内容一样,但是好看多了
3.分类阶段
先定义position,他表示vocabulary中包含特殊符号的每一个position
//是vocabulary中的position还是元例子中的position??
计算 vNB
不是训练例子中的特殊符号的position会被忽略
//有点晕,这是干嘛呢??为什么弄个position出来,就是为了减少计算量吗,那又为什么会使用特殊符号的位置呢??














 2092
2092











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









