







各字符集编码间的转换
1 字符集编码简介
字符(Character)是文字与符号的总称,包括文字、图形符号、数学符号等。
一组抽象字符的集合就是字符集(Charset)。
字符集常常和一种具体的语言文字对应起来,该文字中的所有字符或者大部分常用字符就构成了该文字的字符集,比如英文字符集。一组有共同特征的字符也可以组成字符集,比如繁体汉字字符集、日文汉字字符集。
计算机要处理各种字符,就需要将字符和二进制内码对应起来,这种对应关系就是字符编码(Encoding)。
制定编码首先要确定字符集,并将字符集内的字符排序,然后和二进制数字对应起来。根据字符集内字符的多少,会确定用几个字节来编码。每种编码都限定了一个明确的字符集合,叫做被编码过的字符集(Coded Character Set),这是字符集的另外一个含义。通常所说的字符集大多是这个含义。
2 常见字符集编码
ASCII
American Standard Code for Information Interchange美国信息交换标准码
目前计算机中用得最广泛的字符集及其编码,由美国国家标准局(ANSI)制定。它已被国际标准化组织(ISO)定为国际标准,称为ISO 646标准。ASCII字符集由控制字符和图形字符组成。在计算机的存储单元中,一个ASCII码值占一个字节(8个二进制位)。
ISO 8859-1
ISO 8859,全称ISO/IEC 8859,是国际标准化组织(ISO)及国际电工委员会(IEC)联合制定的一系列8位字符集的标准,现时定义了15个字符集。ASCII收录了空格及94个“可印刷字符”,足以给英语使用。。
很明显,iso8859-1编码表示的字符范围很窄,无法表示中文字符。但是,由于是单字节编码,和计算机最基础的表示单位一致,所以很多时候,仍旧使用iso8859-1编码来表示。而且在很多协议上,默认使用该编码。
UCS
通用字符集(Universal Character Set,UCS)是由ISO制定的ISO 10646(或称ISO/IEC 10646)标准所定义的字符编码方式,采用4字节编码。UCS包含了已知语言的所有字符。UCS还包括大量的图形、印刷、数学、科学符号。
* UCS-2: 与UNICODE的2byte编码基本一样。
* UCS-4: 4byte编码, 目前是在UCS-2前加上2个全零的byte。
Unicode
Unicode(统一码、万国码、单一码)是一种在计算机上使用的字符编码。它是www.unicode.org制定的编码机制,要将全世界常用文字都函括进去。它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。Unicode的编码方式与ISO 10646的通用字符集(Universal Character Set,UCS)概念相对应,目前的用于实用的Unicode版本对应于UCS-2,使用16位的编码空间。也就是每个字符占用2个字节,基本满足各种语言的使用。实际上目前版本的Unicode尚未填充满这16位编码,保留了大量空间作为特殊使用或将来扩展。
UTF
Unicode 的实现方式不同于编码方式。
一个字符的Unicode编码是确定的,但是在实际传输过程中,由于不同系统平台的设计不一定一致,以及出于节省空间的目的,对Unicode编码的实现方式有所不同。Unicode的实现方式称为Unicode转换格式(Unicode Translation Format,简称为 UTF)。
* UTF-8: 8bit变长编码,对于大多数常用字符集(ASCII中0~127字符)它只使用单字节,而对其它常用字符(特别是朝鲜和汉语会意文字),它使用3字节。
* UTF-16: 16bit编码,是变长码,大致相当于20位编码,值在0到0x10FFFF之间,基本上就是Unicode编码的实现,与CPU字序有关。
汉字编码
汉字编码有下面几种:
* GB2312字集是简体字集,全称为GB2312(80)字集,共包括国标简体汉字6763个。
* BIG5字集是台湾繁体字集,共包括国标繁体汉字13053个。
* GBK字集是简繁字集,包括了GB字集、BIG5字集和一些符号,共包括21003个字符。
* GB18030是国家制定的一个强制性大字集标准,全称为GB18030-2000,它的推出使汉字集有了一个“大一统”的标准。
其他
我们在Windows系统中保存文本文件时通常可以选择编码为ANSI、Unicode、Unicode big endian和UTF-8,这里的ANSI和Unicode big endian是什么编码呢?
1)ANSI
使用2个字节来代表一个字符的各种汉字延伸编码方式,称为ANSI编码。在简体中文系统下,ANSI编码代表GB2312编码,在日文操作系统下,ANSI编码代表JIS编码。
2)Unicode big endian:
UTF-8以字节为编码单元,没有字节序的问题。UTF-16以两个字节为编码单元,在解释一个UTF-16文本前,首先要弄清楚每个编码单元的字节序。Unicode规范中推荐的标记字节顺序的方法是BOM(即Byte Order Mark)。在UCS编码中有一个叫做"ZERO WIDTH NO-BREAK SPACE"的字符,它的编码是FEFF。而FFFE在UCS中是不存在的字符,所以不应该出现在实际传输中。UCS规范建议我们在传输字节流前,先传输字符"ZERO WIDTH NO-BREAK SPACE"。这样如果接收者收到FEFF,就表明这个字节流是Big-Endian的;如果收到FFFE,就表明这个字节流是Little-Endian的。
因此字符"ZERO WIDTH NO-BREAK SPACE"又被称作BOM。Windows就是使用BOM来标记文本文件的编码方式的。
所以,我们实际环境中使用的字符集编码都是ANSI编码或者说是GB2312编码或者说是GBK编码。
在如此多种编码和字符集弄的我们眼花缭乱的情况下,我们只需选择一种兼容性最好的编码方式和字符集,让它成为我们程序子系统之间交互的编码契约,那么从此恼人的乱码问题即将远离我们而去,这种兼容性最好的编码就是UTF-8!毕竟GBK/GB2312是国内的标准,当我们大量使用国外的开源软件时,UTF-8才是编码界最通用的语言。
3 编程语言与编码
不同的编程语言内部支持的字符编码不一样:
1)C、C++、Python2内部字符串都是使用当前系统默认编码
2)Python3、Java内部字符串用Unicode保存
3)Ruby有一个内部变量$KCODE用来表示可识别的多字节字符串的编码,变量值为"EUC" "SJIS" "UTF8" "NONE"之一。
4 各字符集编码间的转换
LINUX
在LINUX上进行编码转换时, 可以利用iconv函数族编程实现。
1.iconv函数族的头文件是iconv.h,使用前需包含之。
#include <iconv.h>
2.iconv函数族有三个函数, 原型如下:
(1) iconv_t iconv_open(const char *tocode, const char *fromcode)
此函数说明将要进行哪两种编码的转换,tocode是目标编码, fromcode是原编码,该函数返回一个转换句柄, 供以下两个函数使用。
(2) size_t iconv(iconv_t cd,char **inbuf,size_t *inbytesleft,char **outbuf,size_t *outbytesleft)
此函数从inbuf中读取字符, 转换后输出到outbuf中, inbytesleft用以记录还未转换的字符数,outbytesleft用以记录输出缓冲的剩余空间。
(3) int iconv_close(iconv_t cd)
此函数用于关闭转换句柄,释放资源。
3.使用示例
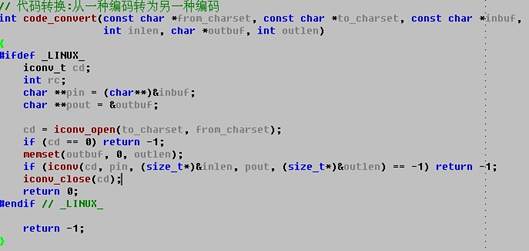
==========================================================================
WIN32
WIN32下的字符转换实例比较多,最常见的可以使用::WideCharToMultiByte来进行字符集编码的转换。使用示例:
1. UTF-8转Unicode

==========================================================================
=================
2. Unicode转GB2312















 7833
7833











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









