







http://blog.csdn.net/jinzhuojun/article/details/46552397
由于Android的SystemServer内有一票重要Service,所以在进程内有一个软件实现的Watchdog机制,用于监视SystemServer中各Service是否正常工作。如果超过一定时间(默认30秒),就dump现场便于分析,再超时(默认60秒)就重启SystemServer保证系统可用性。同时logcat中会打印类似下面信息:
W Watchdog: *** WATCHDOG KILLING SYSTEM PROCESS: Blocked in monitor com.android.server.am.ActivityManagerService on foreground thread (android.fg), Blocked in handler on ActivityManager (ActivityManager), Blocked in handler on WindowManager thread (WindowManager)
主要实现代码位于/frameworks/base/services/core/Java/com/android/server/Watchdog.java和/frameworks/base/core/jni/android_server_Watchdog.cpp。大体的框架很简单。Watchdog是SystemServer中的独立线程,它隔一定时间间隔会向各监视线程调度一次检查操作。这个检查操作当中会调用已注册的Monitor对象。如果Monitor对象上产生死锁,或是关键线程hang住,那么该检查必定不能按时结束,这样就被Watchdog检查到。
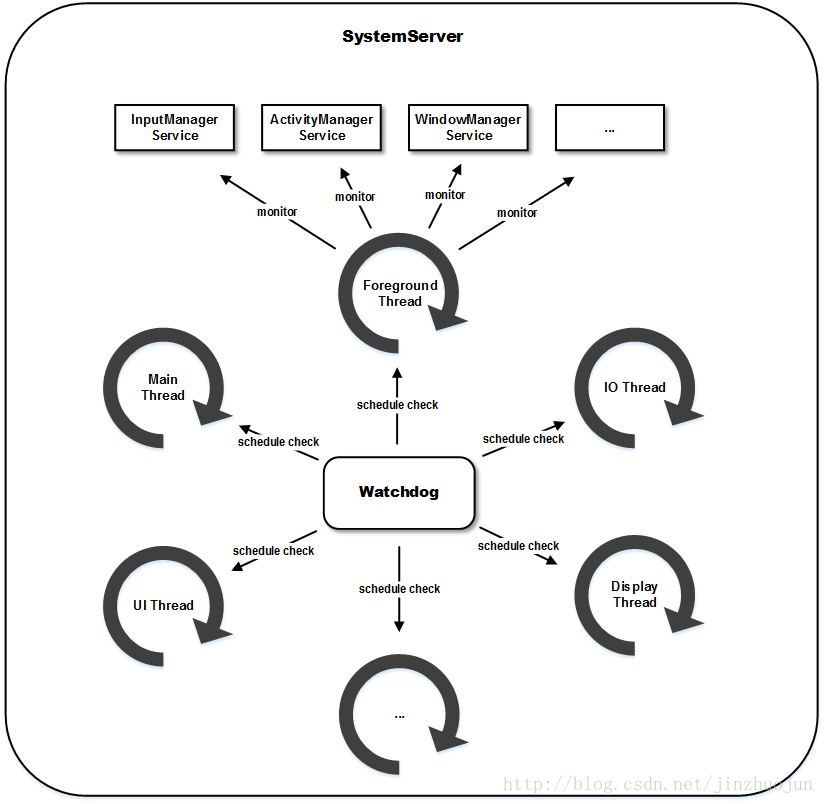
先来看看总体类图。因为是唯一的,Watchdog实现为Singleton。其中维护HandlerChecker数组,对应要检查的线程。HandlerChecker数组中有Monitor数组,对应要检查的Monitor对象。要接受检查的对象需要实现Monitor接口。
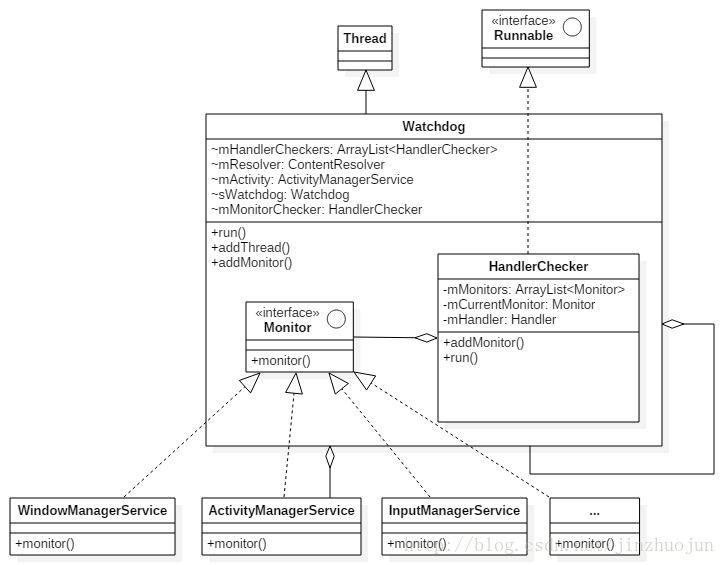
初始化是从SystemServer的startOtherServices()中开始的,其大体流程如下:
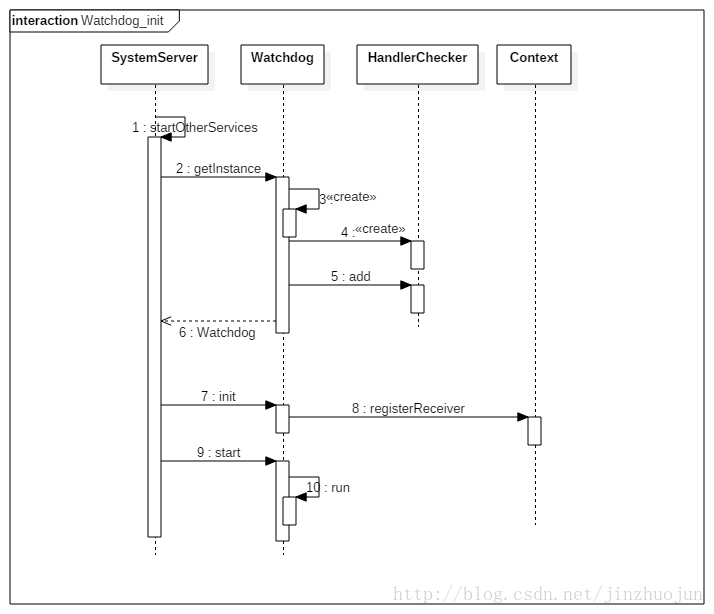
首先,在SystemServer.java中,会创建Watchdog并启动。
- 472 Slog.i(TAG, "Init Watchdog");
- 473 final Watchdog watchdog = Watchdog.getInstance();
- 474 watchdog.init(context, mActivityManagerService);
- …
- 1120 Watchdog.getInstance().start();
- 215 mMonitorChecker = new HandlerChecker(FgThread.getHandler(),
- 216 "foreground thread", DEFAULT_TIMEOUT);
- 217 mHandlerCheckers.add(mMonitorChecker);
接下来,对于System Server的主线程,UI线程,IO线程和Display线程,分别做相同操作,这坨线程和FgThread一样都继承自ServiceThread。在init()函数中,接下来会调用registerReceiver()来注册系统重启的BroadcastReceiver。在收到系统重启广播时会执行RebootRequestReceiver的onReceive()函数,继而调用rebootSystem()重启系统。它允许其它模块(如CTS)通过发广播来让系统重启。
然后,各个需要被Watchdog监视的Service需要将自己进行注册。它们都实现了Watchdog.Monitor接口,其中主要是monitor()函数。例如ActivityManagerService:
- 2150 Watchdog.getInstance().addMonitor(this);
- 2151 Watchdog.getInstance().addThread(mHandler);
- 18767 public void monitor() {
- 18768 synchronized (this) { }
- 18769 }
回到SystemServer中,通过Watchdog的start()方法启动Watchdog线程,Watchdog.run()被执行。

Watchdog的主体是一个循环。在每一次循环中,所有HandlerChecker的scheduleCheckLocked()函数被调用。其中主要是往被监视线程的Looper中放入HandlerChecker对象,HandlerChecker本身作为Runnable,是线程的可执行体。因此当被监视线程把它从Looper中拿出来后,它的run()函数被调用。然后,Watchdog.run()等待最长30秒后,调用evaluateCheckerCompletionLocked()检查各HandlerChecker结果状态。一个HandlerChecker结果状态有四种,COMPLETED(0),WAITING(1), WAITED_HALF(2)和OVERDUE(3)。分别代表目标Looper已处理monitor,延时小于30秒,延时大于30秒小于60秒,延时大于60秒。最终的总状态是它们的最大值(也就是意味着最坏情况的那种情况)。如果总状态是COMPLETED,WAITING或WAITED_HALF,则进入循环下一轮。注意如果是WAITED_HALF,也就是说等了大于30秒,需要调用AMS.dumpStackTraces()来dump栈。如果状态为WAITED_HALF,进入下一轮循环后,又会等待最长30秒。
假设有线程阻塞,对于阻塞线程的HandlerChecker,它的延迟超过60秒,导致总状态为OVERDUE。这里会调用getBlockedCheckersLocked()和describeCheckersLocked()打印出是哪个Handler阻塞了。在Eventlog中打出信息后,把当前pid和相关进程pid放入待杀列表。然后和上面一样调用AMS.dumpStackTraces()打印栈。之后等待2秒等stacktrace写完。如有需要还会调用dumpKernelStackTraces()将kernel部分的stacktrace打出来。本质上是读取/proc/[pid]/task下的线程的和相应的/proc/[tid]/stack文件。然后调用doSyncRq()通知kernel把阻塞线程信息和backtrace打印出来(通过写/proc/sysrq-trigger)。之后会创建专门的线程来将信息写入到Dropbox,该线程会执行AMS.addErrorToDropBox()。Dropbox是Android中的一套日志记录系统,作用是将系统出错信息记录下来并且保留一段时间,避免被覆盖。当出现crash, wtf, lowmem或者Watchdog被触发都会通过Dropbox来记录。
- 425 Thread dropboxThread = new Thread("watchdogWriteToDropbox") {
- 426 public void run() {
- 427 mActivity.addErrorToDropBox(
- 428 "watchdog", null, "system_server", null, null,
- 429 subject, null, stack, null);
- 430 }
- 431 };
- 432 dropboxThread.start();
- 433 try {
- 434 dropboxThread.join(2000); // wait up to 2 seconds for it to return.
- 435 } catch (InterruptedException ignored) {}
接下来,如果设置了ActivityController就调用其systemNotResponding()接口(IActivityController是给测试开发时用的接口,用于监视AMS里的行为)。然后判断Debugger是否连着和是否允许restart。如果没有连着debugger且允许restart,就开始大开杀戒了。
- 467 Slog.w(TAG, "*** WATCHDOG KILLING SYSTEM PROCESS: " + subject);
- ...
- 476 Slog.w(TAG, "*** GOODBYE!");
- 477 Process.killProcess(Process.myPid());
- 478 System.exit(10);
这就是Watchdog的大体流程,回过头看下AMS中dumpStackTraces()的一些细节。参数中的pids包含了本进程,阻塞线程以及phone进程等。NATIVE_STACKS_OF_INTEREST包含了下面三个关键进程。
- 67 public static final String[] NATIVE_STACKS_OF_INTEREST = new String[] {
- 68 "/system/bin/mediaserver",
- 69 "/system/bin/sdcard",
- 70 "/system/bin/surfaceflinger"
- 71 };
dumpStackTraces()实现中先从dalvik.vm.stack-trace-file这个system property中取出trace路径,默认为/data/anr/traces.txt。接着它创建该文件(需要的话),设置属性,最后调用同名函数dumpStackTraces()完成真正的dump工作。dump工作首先会用FileObserver(利用inotify机制)监视trace文件什么时候写完。它会创建一个独立的线程ObserverThread并运行。然后对于前面加入到要dump线程列表中的进程,发送SIGQUIT信号。如果是虚拟机进程,ART中的SignalCatcher::HandleSigQuit()(在/art/runtime/signal_catcher.cc)会被调用来dump信息(DVM也是类似的)。对于前面的核心Service,调用Debug.dumpNativeBacktraceToFile()来输出它们的backtrace。
总结下来,dumpStackTraces()大体流程如下:

可以看到,其中主要收集三类信息:一是关键进程(也就是上面收集的pid)的stacktrace;二是几个关键native服务的stacktrace;三是CPU的使用率。其中一是通过往目标进程发SIGQUIT来获取,因为Java虚拟机的Runtime会捕获SIGQUIT信号打印栈信息。二的原理是向后台debuggerd这个daemon发起申请,让其用ptrace打印目标进程的stacktrace然后用本地socket传回来。部分实现位于android_os_Debug.cpp和/system/core/libcutils/debugger.c。发起申请和接收数据的代码在以下函数:
- 131int dump_backtrace_to_file_timeout(pid_t tid, int fd, int timeout_secs) {
- 132 int sock_fd = make_dump_request(DEBUGGER_ACTION_DUMP_BACKTRACE, tid, timeout_secs);
- ...
- 137 /* Write the data read from the socket to the fd. */
- ...
- 141 while ((n = TEMP_FAILURE_RETRY(read(sock_fd, buffer, sizeof(buffer)))) > 0) {
- 142 if (TEMP_FAILURE_RETRY(write(fd, buffer, n)) != n) {
- 143 result = -1;
- 144 break;
- 145 }
- 146 }
- ...
总得来说,Watchdog是一个软件实现的检测SystemServer进程内死锁或挂起问题,并能够从中恢复的机制。除了Watchdog外,Android中还有一些自检容错及出错信息收集机制,前者有ANR,OOM Killer,init中的重启机制等,后者有Dropbox,Debuggerd,Eventlog,Bugreport等。除此之外,其它的信息查看和调试命令就不计其数了,如dumpsys, dumpstate, showslab, procrank, procmem, latencytop, librank, schedtop, svc, am ,wm, atrace, proc, pm, service, getprop/setprop, logwrapper, input, getevent/sendevent等。充分利用这些工具能够有效提高分析问题的效率。















 2099
2099

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









