








3) Scheduling in YARN
a) In an ideal world, the requests that a YARN application makes would be granted immediately. In the real world, however, resources are limited, and on a busy cluster, an application will often need to wait to have some of its requests fulfilled. It is the job of the YARN scheduler to allocate resources to applications according to some defined policy. Scheduling in general is a difficult problem and there is no one “best” policy, which is why YARN provides a choice of schedulers and configurable policies. We look at these next.
在理想的情况下,一个YARN应用发出的请求会被及时响应,然而,在现实情况下,资源是有限的,在一个繁忙的集群中,一个应用经常需要等待才能满足它的某些请求。根据一些确定的规则给应用程序分配资源,这就是YARN调度器的工作。通常而言,调度,是一个棘手的问题,没有一个“最好的”方针,这也就是为什么YARN提供了一个调度器和可配置规则的选择的原因。接下来我们可以看到那些。
b) Scheduler Options
c) Three schedulers are available in YARN: the FIFO, Capacity, and Fair Schedulers. The FIFO Scheduler places applications in a queue and runs them in the order of submission (first in, first out). Requests for the first application in the queue are allocated first; once its requests have been satisfied, the next application in the queue is served, and so on.
在YARN中,有三种调度器可用:FIFO,Capacity,Fair调度器。FIFO调度器会将应用程序置于一个队列中,然后按照提交的顺序运行它们(先进先出)。在队列中第一个应用的请求会被分配给第一个应用。一旦它的请求被满足了,队列中的下一个应用将开始接受服务,以此类推。
d) The FIFO Scheduler has the merit of being simple to understand and not needing any configuration, but it’s not suitable for shared clusters. Large applications will use all the resources in a cluster, so each application has to wait its turn. On a shared cluster it is better to use the Capacity Scheduler or the Fair Scheduler. Both of these allow longrunning jobs to complete in a timely manner, while still allowing users who are running concurrent smaller ad hoc queries to get results back in a reasonable time.
FIFO调度器具有容易理解和不需要配置的优点,但是它不适合于共享集群。大型应用程序将会使用集群中的所有资源,因此每一个应用都不得不等待来轮到自己。在一个共享集群中,使用Capacity或者Fair调度器会更好。这两者都允许需要长时间运行的作业以及时的方式来完成,但也任然允许正在运行的用户进行少量的特定的并发查询,且在一个合理的时间范围内返回结果。
e) 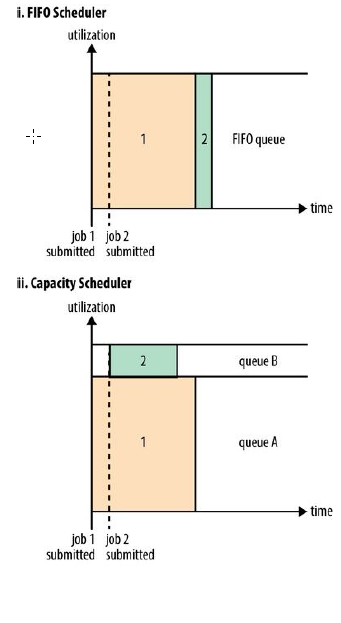
f) The difference between schedulers is illustrated in Figure 4-3, which shows that under the FIFO Scheduler (i) the small job is blocked until the large job completes.
调度器之间的差异在图表4-3中有说明,其展示了在FIFO调度器中,较小的作业被锁定,直到较大的作业完成.
g) With the Capacity Scheduler (ii in Figure 4-3), a separate dedicated queue allows the small job to start as soon as it is submitted, although this is at the cost of overall cluster utilization since the queue capacity is reserved for jobs in that queue. This means that the large job finishes later than when using the FIFO Scheduler.
在Capacity调度器中,只要作业已经提交,一个独立专门的队列将允许较小的作业启动,尽管是以整个集群利用率为代价的,这是由于队列容量需要给那个独立的队列的作业预留空间导致的。这也意味着,对于较大的作业来说,比采用FIFO调度器要完成的晚一些。
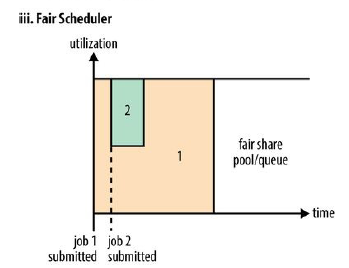
h) With the Fair Scheduler (iii in Figure 4-3), there is no need to reserve a set amount of capacity, since it will dynamically balance resources between all running jobs. Just after the first (large) job starts, it is the only job running, so it gets all the resources in the cluster. When the second (small) job starts, it is allocated half of the cluster resources so that each job is using its fair share of resources.
使用Fair调度器的话,没有必要预留一定数量的容量,因为Fair调度器将动态平衡所有运行作业的资源。第一个较大的作业刚刚启动之后,它就是唯一一个正在运行的作业,因此它将会得到集群中全部的资源。当第二个较小的作业启动时,它将会被分配一般的集群资源,以便每一个作业都可以使用它的公平分配的资源。
i) Note that there is a lag between the time the second job starts and when it receives its fair share, since it has to wait for resources to free up as containers used by the first job complete. After the small job completes and no longer requires resources, the large job goes back to using the full cluster capacity again. The overall effect is both high cluster utilization and timely small job completion.
注意,在第二个作业启动到他获得它的公平分配资源之间有一个时间延迟,因为它不得不等待被第一个作业所使用的容器完成之后所释放的资源。当较小的作业完成,且不再需要资源时,较大的作业将会返回去再次使用整个集群资源。整体效果就是高集群利用率和较小作业的及时完成性。
j) Capacity Scheduler Configuration
k) The Capacity Scheduler allows sharing of a Hadoop cluster along organizational lines, whereby each organization is allocated a certain capacity of the overall cluster. Each organization is set up with a dedicated queue that is configured to use a given fraction of the cluster capacity. Queues may be further divided in hierarchical fashion, allowing each organization to share its cluster allowance between different groups of users within the organization. Within a queue, applications are scheduled using FIFO scheduling.
Capacity调度器允许沿着组织线共享Hadoop集群,这可以通过给每个组织分配一定的集群容量来实现。每个组织可以通过已配置的专用队列去使用一部分已给定的集群资源来创建。队列可能更近一步的分开成为层级模式,其允许每个组织在组织内部的不同用户组织之间分享集群限额资源。在队列内部,应用程序将使用FIFO调度模式。
l) As we saw in Figure 4-3, a single job does not use more resources than its queue’s capacity. However, if there is more than one job in the queue and there are idle resources available, then the Capacity Scheduler may allocate the spare resources to jobs in the queue, even if that causes the queue’s capacity to be exceeded. This behavior is known as queue elasticity.
就像我们在图表4-3中看到的那样,单个作业不可能使用超过其队列容量的资源,然而,如果在队列中有不止一个作业,且还有空闲的资源可以使用,那么Capacity模式可能分配多余的资源给那些作业,即使这样会导致队列的容量溢出,这个动作以队列的灵活性著称。
hadoop权威指南(第四版)要点翻译(7)——Chapter 4. YARN(2)
最新推荐文章于 2024-04-21 23:13:45 发布














 1544
1544











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









