









架构
mysql最大的特色就是把查询处理与 实际的数据存储和提取(存储引擎)的操作分开了。其整体的架构如下:
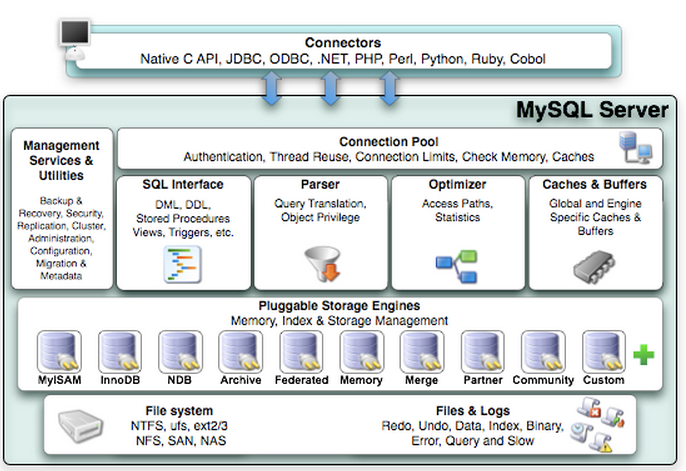
- Connectors 看到JDBC就懂起了,是连接mysql的各种客户端
- Connection Pool 用于创建用户连接,缓存连接线程,做连接池。 还有鉴权
修改my.ini重启可以修改最大连接数:
max_connections=200查看当前变量配置:
SHOW VARIABLES like 'max_c%';下面的命令还能查看具体的当前连接的信息:
SHOW processlist;虽然mysql自带了连接池,但是更多的还是使用客户端连接池的方式。
基本的原理就是一次建立连接之后缓存,然后所有调用连接的地方都从池中取封装之后的
在关闭池中取出的连接时不会真正的关闭连接,而是放回池中,这样就减少了鉴权,三次握手等等操作,增加性能。
- SQL Interface
内置函数,DML, DDL,存储过程,视图,触发器,都在这边。 - Parser
解析器, 主要有两个功能。验证sql语句是否正确, 把sql语句解析为数据结构,以后只使用这个结构。
解析器的功能基本上都是这样的,比如Spring中也有xml的解析器也是先转化为一个数据结构之后使用这个数据结构。 - Optimizer
优化器。 记得JVM也是有优化器的,会进行重排序呀,以及解释语法糖啊等等操作。
解析器解析成树,然后进行重写查询,决定表的读取顺序,以及选择合适的索引的操作。在解析查询之前会先检查缓存,如果命中就没有解析优化和执行的过程。
这里有一个更好的说明:http://blog.csdn.net/whyangwanfu/article/details/1943021 - Cache & Buffer
缓存,执行查询语句的时候会先查缓存,如果命中则直接返回,如果没命中才去查sql语句 - Managerment Service
非常强大的管理功能, 监控,备份,还原, 镜像, 集群。。。。 - Storage Engine
存储引擎,
常用的存储引擎
SHOW TABLE STATUS like 'biz_pay_task';这样可以查看表的各种信息,包括存储引擎
InnoDB
- 适用于大多数成功少回滚的大量短期事务
- 使用MVCC来支持高并发
- 实现了四个隔离级别,默认REPEATEABLE READ
- 通过间隙锁策略防止幻读的出现
MyISAM
- 文件分离
- 恢复慢
- 支持GIS,全文索引,压缩
- 表锁,不支持事务
Memmory
这就是Redis呀
Infobright
面向列的存储引擎,适用于数据仓库
选择引擎
可以从如下的几个出发点:
- 是否需要事务 InnoDb
- 是否用到全文索引 InnoDB + Sphinx
- 备份及恢复 InnoDB
- 日志型, 插入性能要求高, 用MyISAM,还能随时拷贝备库去做分析
进行服务器测量时的一些基本知识:
- 用响应时间定义服务器新跟那个
- 最佳开始点是应用程序,而不是数据库,因为他更容易发生问题。
- 完整的测量会产生大量需要分析的数据,要根据情况对这些数据进行汇总以及细分分析
- 通常消耗时间的操作时工作和等待:我们通常能够很好的去测量工作时间,但是当cpu使用率很低有等待的情况是却无法很好的测量。















 4119
4119

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









