







common_layer:
ArgMaxLayer类;
ConcatLayer类:
EltwiseLayer类;
FlattenLayer类;
InnerProductLayer类;
MVNLayer类;
SilenceLayer类;
SoftmaxLayer类,CuDNNSoftmaxLayer类;
SplitLayer类;
SliceLayer类。
呃,貌似就晓得全链接一样!!一个个的来看看这些是可以用在什么地方?
1 ArgMaxLayer:
Compute the index of the @f$ K @f$ max values for each datum across all dimensions @f$ (C \times H \times W) @f$.
Intended for use after a classification layer to produce a prediction. If parameter out_max_val is set to true, output is a vector of pairs (max_ind, max_val) for each image.
NOTE: does not implement Backwards operation.
1.1 原理介绍:
在做分类之后,也就是经过全链接层之后,对每组数据计算其最大的前K个值。
感觉上有点像:例如我们在使用caffeNet做预测的时候,通常会输出概率最大的5个值,感觉上就是这个层在起作用。(这句话是乱说的哈,没有得到确认!)
所以也不需要反馈什么的了。
1.2 属性变量:
bool out_max_val_;
size_t top_k_;从下面的构造函数里面可以看到,当out_max_val_赋值为true的时候,输出包括下标和值;赋值为false的时候,就只输出下标。
top_k_的话,用于表明找到前top_k_个最大值吧。
1.3 构造函数:
template <typename Dtype>
void ArgMaxLayer<Dtype>::LayerSetUp(const vector<Blob<Dtype>*>& bottom,
vector<Blob<Dtype>*>* top) {
out_max_val_ = this->layer_param_.argmax_param().out_max_val();
top_k_ = this->layer_param_.argmax_param().top_k();
CHECK_GE(top_k_, 1) << " top k must not be less than 1.";
CHECK_LE(top_k_, bottom[0]->count() / bottom[0]->num())
<< "top_k must be less than or equal to the number of classes.";
}
template <typename Dtype>
void ArgMaxLayer<Dtype>::Reshape(const vector<Blob<Dtype>*>& bottom,
vector<Blob<Dtype>*>* top) {
if (out_max_val_) {
// Produces max_ind and max_val
(*top)[0]->Reshape(bottom[0]->num(), 2, top_k_, 1);
} else {
// Produces only max_ind
(*top)[0]->Reshape(bottom[0]->num(), 1, top_k_, 1);
}
}这两个函数没什么好说的嘛,很好理解。只是好像最开始学习使用caffe,并试着训练一些模型,试着写模型的配置文件时,没有用过这个层一样?!
1.4 前馈函数:
template <typename Dtype>
void ArgMaxLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom,
vector<Blob<Dtype>*>* top) {
const Dtype* bottom_data = bottom[0]->cpu_data();
Dtype* top_data = (*top)[0]->mutable_cpu_data();
int num = bottom[0]->num();
int dim = bottom[0]->count() / bottom[0]->num();
for (int i = 0; i < num; ++i) {
std::vector<std::pair<Dtype, int> > bottom_data_vector;
for (int j = 0; j < dim; ++j) {
bottom_data_vector.push_back(
std::make_pair(bottom_data[i * dim + j], j));
}
std::partial_sort(
bottom_data_vector.begin(), bottom_data_vector.begin() + top_k_,
bottom_data_vector.end(), std::greater<std::pair<Dtype, int> >());
for (int j = 0; j < top_k_; ++j) {
top_data[(*top)[0]->offset(i, 0, j)] = bottom_data_vector[j].second;
}
if (out_max_val_) {
for (int j = 0; j < top_k_; ++j) {
top_data[(*top)[0]->offset(i, 1, j)] = bottom_data_vector[j].first;
}
}
}
}我想可以用下面这样一个图来表述ArgMaxLayer的作用:
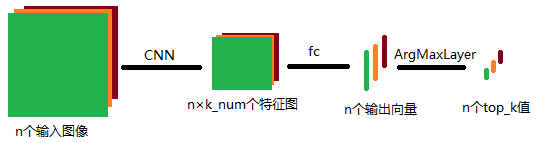
这个图的最有端,也表明了其计算过程,所以再去读一下上面的前馈函数,就很容易理解了吧。
2 ConcatLayer:
Takes at least two Blob%s and concatenates them along either the num or channel dimension, outputting the result.
2.1 原理介绍:
前馈:(矩阵合并)
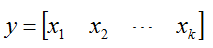
反馈:(矩阵分割)
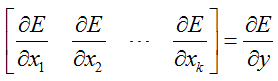
有没有觉得奇怪,什么地方会用这种层呢?其实至少在google的论文中看到了确实用得上这种层,也就是那个“盗梦空间”结构。
2.2 属性变量:
Blob<Dtype> col_bob_;
int count_;
int num_;
int channels_;
int height_;
int width_;
int concat_dim_;其中两个变量不怎么认识:
col_bob_:
concat_dim_:指定在链接Blob时的维度,例如当concat_dim_,表示从第2个维度链接Blob。
其余的几个变量都是比较熟悉了,不过需要注意的是,这里的几个值都是用于设置top层Blob大小的。
2.3 构造函数:
template <typename Dtype>
void ConcatLayer<Dtype>::LayerSetUp(const vector<Blob<Dtype>*>& bottom,
vector<Blob<Dtype>*>* top) {
concat_dim_ = this->layer_param_.concat_param().concat_dim();
CHECK_GE(concat_dim_, 0) <<
"concat_dim should be >= 0";
CHECK_LE(concat_dim_, 1) <<
"For now concat_dim <=1, it can only concat num and channels";
}
template <typename Dtype>
void ConcatLayer<Dtype>::Reshape(const vector<Blob<Dtype>*>& bottom,
vector<Blob<Dtype>*>* top) {
// Initialize with the first blob.
count_ = bottom[0]->count();
num_ = bottom[0]->num();
channels_ = bottom[0]->channels();
height_ = bottom[0]->height();
width_ = bottom[0]->width();
for (int i = 1; i < bottom.size(); ++i) {
count_ += bottom[i]->count();
if (concat_dim_== 0) {
num_ += bottom[i]->num();
} else if (concat_dim_ == 1) {
channels_ += bottom[i]->channels();
} else if (concat_dim_ == 2) {
height_ += bottom[i]->height();
} else if (concat_dim_ == 3) {
width_ += bottom[i]->width();
}
}
(*top)[0]->Reshape(num_, channels_, height_, width_);
CHECK_EQ(count_, (*top)[0]->count());
}这里在初始化的时候, Reshape()中,注意到那个for了吧。假设bottom中有K个Blob,链接的维度是1,那么自然top层Blob的channels_维等于bottom中K个channels之和。
2.4 前馈反馈函数:
前馈:
template <typename Dtype>
void ConcatLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom,
vector<Blob<Dtype>*>* top) {
Dtype* top_data = (*top)[0]->mutable_cpu_data();
if (concat_dim_== 0) {
int offset_num = 0;
for (int i = 0; i < bottom.size(); ++i) {
const Dtype* bottom_data = bottom[i]->cpu_data();
int num_elem = bottom[i]->count();
caffe_copy(num_elem, bottom_data, top_data+(*top)[0]->offset(offset_num));
offset_num += bottom[i]->num();
}
} else if (concat_dim_ == 1) {
int offset_channel = 0;
for (int i = 0; i < bottom.size(); ++i) {
const Dtype* bottom_data = bottom[i]->cpu_data();
int num_elem =
bottom[i]->channels()*bottom[i]->height()*bottom[i]->width();
for (int n = 0; n < num_; ++n) {
caffe_copy(num_elem, bottom_data+bottom[i]->offset(n),
top_data+(*top)[0]->offset(n, offset_channel));
}
offset_channel += bottom[i]->channels();
} // concat_dim_ is guaranteed to be 0 or 1 by LayerSetUp.
}
}这里的实现中,算是默认了,链接的维度只可能是第0维和第1维。既然这样的话,Reshape中也没有必要写那么多了嘛。
其它的就相当于是矩阵的拼接。
反馈:
template <typename Dtype>
void ConcatLayer<Dtype>::Backward_cpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down, vector<Blob<Dtype>*>* bottom) {
const Dtype* top_diff = top[0]->cpu_diff();
if (concat_dim_ == 0) {
int offset_num = 0;
for (int i = 0; i < bottom->size(); ++i) {
Blob<Dtype>* blob = (*bottom)[i];
if (propagate_down[i]) {
Dtype* bottom_diff = blob->mutable_cpu_diff();
caffe_copy(blob->count(), top_diff + top[0]->offset(offset_num),
bottom_diff);
}
offset_num += blob->num();
}
} else if (concat_dim_ == 1) {
int offset_channel = 0;
for (int i = 0; i < bottom->size(); ++i) {
Blob<Dtype>* blob = (*bottom)[i];
if (propagate_down[i]) {
Dtype* bottom_diff = blob->mutable_cpu_diff();
int num_elem = blob->channels()*blob->height()*blob->width();
for (int n = 0; n < num_; ++n) {
caffe_copy(num_elem, top_diff + top[0]->offset(n, offset_channel),
bottom_diff + blob->offset(n));
}
}
offset_channel += blob->channels();
}
} // concat_dim_ is guaranteed to be 0 or 1 by LayerSetUp.
}同样,反馈的时候,就是矩阵分割的问题。
3 EltwiseLayer:
Compute elementwise operations, such as product and sum, along multiple input Blobs.
3.1 原理介绍:
对多个矩阵之间按元素进行某种操作,通过源码可以看到,一共提供了:乘以,求和,取最大值,三种操作。
前面介绍了那么多前馈和反馈的原理,这里理解起来应该很容易。这里三种操作,分别进行就好了。
3.2 属性变量:
EltwiseParameter_EltwiseOp op_;
vector<Dtype> coeffs_;
Blob<int> max_idx_;
bool stable_prod_grad_;既然实现的是多个Blob之间的某种操作,那么自然会定义是什么操作,所以有了变量op_,但是EltwiseParameter_EltwiseOp类型是在什么地方定义的?
coeffs_:该变量的大小应该是和bottom层的Blob个数是相同的,也就是说如果在进行求和的时候,是按照加权求和的。也就是:
其中的 y 和 x_i 都是矩阵,而coeffs_i是一个值。
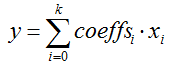
max_idx_:如果是进行取最大值操作,为了在反馈的时候,能够反馈得回去,所以需要记录最大值来源于哪个Blob。从后面会看到top层的Blob和bottom的Blob尺寸大小是相同的,但是top层只有一个Blob,而bottom层有多个Blob。
stable_prod_grad_:在乘积方式反馈的时候,控制反馈的方式。
3.3 构造函数:
template <typename Dtype>
void EltwiseLayer<Dtype>::LayerSetUp(const vector<Blob<Dtype>*>& bottom,
vector<Blob<Dtype>*>* top) {
CHECK(this->layer_param().eltwise_param().coeff_size() == 0
|| this->layer_param().eltwise_param().coeff_size() == bottom.size()) <<
"Eltwise Layer takes one coefficient per bottom blob.";
CHECK(!(this->layer_param().eltwise_param().operation()
== EltwiseParameter_EltwiseOp_PROD
&& this->layer_param().eltwise_param().coeff_size())) <<
"Eltwise layer only takes coefficients for summation.";
op_ = this->layer_param_.eltwise_param().operation();
// Blob-wise coefficients for the elementwise operation.
coeffs_ = vector<Dtype>(bottom.size(), 1);
if (this->layer_param().eltwise_param().coeff_size()) {
for (int i = 0; i < bottom.size(); ++i) {
coeffs_[i] = this->layer_param().eltwise_param().coeff(i);
}
}
stable_prod_grad_ = this->layer_param_.eltwise_param().stable_prod_grad();
}
template <typename Dtype>
void EltwiseLayer<Dtype>::Reshape(const vector<Blob<Dtype>*>& bottom,
vector<Blob<Dtype>*>* top) {
const int num = bottom[0]->num();
const int channels = bottom[0]->channels();
const int height = bottom[0]->height();
const int width = bottom[0]->width();
for (int i = 1; i < bottom.size(); ++i) {
CHECK_EQ(num, bottom[i]->num());
CHECK_EQ(channels, bottom[i]->channels());
CHECK_EQ(height, bottom[i]->height());
CHECK_EQ(width, bottom[i]->width());
}
(*top)[0]->Reshape(num, channels, height, width);
// If max operation, we will initialize the vector index part.
if (this->layer_param_.eltwise_param().operation() ==
EltwiseParameter_EltwiseOp_MAX && top->size() == 1) {
max_idx_.Reshape(bottom[0]->num(), channels, height, width);
}
}从这里的 Reshape()中看到,该层的所有输入Blob的尺寸必须相同。
3.4 前馈反馈函数:
前馈:
template <typename Dtype>
void EltwiseLayer<Dtype>::Forward_cpu(
const vector<Blob<Dtype>*>& bottom, vector<Blob<Dtype>*>* top) {
int* mask = NULL;
const Dtype* bottom_data_a = NULL;
const Dtype* bottom_data_b = NULL;
const int count = (*top)[0]->count();
Dtype* top_data = (*top)[0]->mutable_cpu_data();
switch (op_) {
case EltwiseParameter_EltwiseOp_PROD:
caffe_mul(count, bottom[0]->cpu_data(), bottom[1]->cpu_data(), top_data);
for (int i = 2; i < bottom.size(); ++i) {
caffe_mul(count, top_data, bottom[i]->cpu_data(), top_data);
}
break;
case EltwiseParameter_EltwiseOp_SUM:
caffe_set(count, Dtype(0), top_data);
// TODO(shelhamer) does BLAS optimize to sum for coeff = 1?
for (int i = 0; i < bottom.size(); ++i) {
caffe_axpy(count, coeffs_[i], bottom[i]->cpu_data(), top_data);
}
break;
case EltwiseParameter_EltwiseOp_MAX:
// Initialize
mask = max_idx_.mutable_cpu_data();
caffe_set(count, -1, mask);
caffe_set(count, Dtype(-FLT_MAX), top_data);
// bottom 0 & 1
bottom_data_a = bottom[0]->cpu_data();
bottom_data_b = bottom[1]->cpu_data();
for (int idx = 0; idx < count; ++idx) {
if (bottom_data_a[idx] > bottom_data_b[idx]) {
top_data[idx] = bottom_data_a[idx]; // maxval
mask[idx] = 0; // maxid
} else {
top_data[idx] = bottom_data_b[idx]; // maxval
mask[idx] = 1; // maxid
}
}
// bottom 2++
for (int blob_idx = 2; blob_idx < bottom.size(); ++blob_idx) {
bottom_data_b = bottom[blob_idx]->cpu_data();
for (int idx = 0; idx < count; ++idx) {
if (bottom_data_b[idx] > top_data[idx]) {
top_data[idx] = bottom_data_b[idx]; // maxval
mask[idx] = blob_idx; // maxid
}
}
}
break;
default:
LOG(FATAL) << "Unknown elementwise operation.";
}
}这里的代码直接看,容易理解。
反馈:
template <typename Dtype>
void EltwiseLayer<Dtype>::Backward_cpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down, vector<Blob<Dtype>*>* bottom) {
const int* mask = NULL;
const int count = top[0]->count();
const Dtype* top_data = top[0]->cpu_data();
const Dtype* top_diff = top[0]->cpu_diff();
for (int i = 0; i < bottom->size(); ++i) {
if (propagate_down[i]) {
const Dtype* bottom_data = (*bottom)[i]->cpu_data();
Dtype* bottom_diff = (*bottom)[i]->mutable_cpu_diff();
switch (op_) {
case EltwiseParameter_EltwiseOp_PROD:
if (stable_prod_grad_) {
bool initialized = false;
for (int j = 0; j < bottom->size(); ++j) {
if (i == j) { continue; }
if (!initialized) {
caffe_copy(count, (*bottom)[j]->cpu_data(), bottom_diff);
initialized = true;
} else {
caffe_mul(count, (*bottom)[j]->cpu_data(), bottom_diff,
bottom_diff);
}
}
} else {
caffe_div(count, top_data, bottom_data, bottom_diff);
}
caffe_mul(count, bottom_diff, top_diff, bottom_diff);
break;
case EltwiseParameter_EltwiseOp_SUM:
if (coeffs_[i] == Dtype(1)) {
caffe_copy(count, top_diff, bottom_diff);
} else {
caffe_cpu_scale(count, coeffs_[i], top_diff, bottom_diff);
}
break;
case EltwiseParameter_EltwiseOp_MAX:
mask = max_idx_.cpu_data();
for (int index = 0; index < count; ++index) {
Dtype gradient = 0;
if (mask[index] == i) {
gradient += top_diff[index];
}
bottom_diff[index] = gradient;
}
break;
default:
LOG(FATAL) << "Unknown elementwise operation.";
}
}
}
}反馈中的 求和反馈,取最大值的反馈,都还是很好理解。
乘积的反馈好像有点怪怪的。首先来看看成绩反馈时的基本原理:
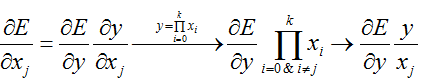
所以直接使用top_data/bottom_data再乘以top_diff,这个是很好理解的。
可是源代码中提供了两种方式:
第1中方式是:计算mul(x_i),i=0...k-1且i != j
第2种方式就是:top_data/bottom_data
只要数据不是很多0,结果应该是差不多的,那么为什么会用这两种方式呢?不理解。
4 FlattenLayer:
Reshapes the input Blob into flat vectors.
Note: because this layer does not change the input values -- merely the dimensions -- it can simply copy the input. The copy happens "virtually" (thus taking effectively 0 real time) by setting, in Forward, the data pointer of the top Blob to that of the bottom Blob (see Blob::ShareData), and in Backward, the diff pointer of the bottom Blob to that of the top Blob (see Blob::ShareDiff).
4.1 原理介绍:
其实没啥原理,只是简单的将数据从一个矩阵变成了一个向量而已。
所以前馈反馈,都只是简单的赋值过程。
4.2 构造函数:
template <typename Dtype>
void FlattenLayer<Dtype>::Reshape(const vector<Blob<Dtype>*>& bottom,
vector<Blob<Dtype>*>* top) {
int channels_out = bottom[0]->channels() * bottom[0]->height()
* bottom[0]->width();
(*top)[0]->Reshape(bottom[0]->num(), channels_out, 1, 1);
count_ = bottom[0]->num() * channels_out;
CHECK_EQ(count_, bottom[0]->count());
CHECK_EQ(count_, (*top)[0]->count());
}这里将top层的数据存储格式做了改变,相当于原来的数据尺寸是这样的:(nums, channels, heights, weights),到了top层变成了:(nums, channels×heights×weights)。
4.3 前馈反馈函数:
template <typename Dtype>
void FlattenLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom,
vector<Blob<Dtype>*>* top) {
(*top)[0]->ShareData(*bottom[0]);
}
template <typename Dtype>
void FlattenLayer<Dtype>::Backward_cpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down, vector<Blob<Dtype>*>* bottom) {
(*bottom)[0]->ShareDiff(*top[0]);
}前馈只是做简单的赋值,这个倒是很好理解。但是反馈的时候为啥还是简单的赋值呢?数据尺寸不应该是从(nums, channels×heights×weights)变到了(nums, channels, heights, weights)吗?
只是我的个人理解哈:Blob的数据存储只是一个一维的指针,可以直接看成是一个向量,只是逻辑上划分成了矩阵。所以就算改变尺寸都只是逻辑上的划分而已,物理上的先后顺序应该是没有做任何变化的,所以在前馈反馈的时候,都只需要将指针赋值过来就好。
5 InnerProductLayer:
Also known as a "fully-connected" layer, computes an inner product with a set of learned weights, and (optionally) adds biases.
5.1 原理介绍:
前馈的过程是很简单的:y = W * x + b
反馈的过程:
对权重W求偏导的链式法则:
对偏置b求偏导的链式法则:
对数据x求偏导的链式法则:
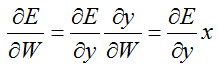
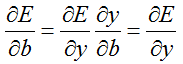
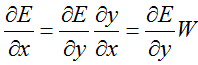
5.2 属性变量:
int M_;
int K_;
int N_;
bool bias_term_;
Blob<Dtype> bias_multiplier_;M_:在 Reshape()函数中看到,M_表示的是前层的num,也就是输入图像数量。
K_:从构造函数中可以看到K_ = bottom[0]->count() / bottom[0]->num(),所以如果该层前面是pooling层或者卷积层,那么K_相当于是channel*height*width,如果前层是全链接层,那么K_相当于4096(全链接层典型的数字,或者说是前层全链接层的num_output )。
N_:表示本层的num_output
bias_term_:表示是否存在偏置
bias_multipiler_:在Reshape()函数中看到,全部被初始化为1了,该数据的大小长度就是M_。
5.3 构造函数:
template <typename Dtype>
void InnerProductLayer<Dtype>::LayerSetUp(const vector<Blob<Dtype>*>& bottom,
vector<Blob<Dtype>*>* top) {
const int num_output = this->layer_param_.inner_product_param().num_output();
bias_term_ = this->layer_param_.inner_product_param().bias_term();
N_ = num_output;
K_ = bottom[0]->count() / bottom[0]->num();
// Check if we need to set up the weights
if (this->blobs_.size() > 0) {
LOG(INFO) << "Skipping parameter initialization";
} else {
if (bias_term_) {
this->blobs_.resize(2);
} else {
this->blobs_.resize(1);
}
// Intialize the weight
this->blobs_[0].reset(new Blob<Dtype>(1, 1, N_, K_));
// fill the weights
shared_ptr<Filler<Dtype> > weight_filler(GetFiller<Dtype>(
this->layer_param_.inner_product_param().weight_filler()));
weight_filler->Fill(this->blobs_[0].get());
// If necessary, intiialize and fill the bias term
if (bias_term_) {
this->blobs_[1].reset(new Blob<Dtype>(1, 1, 1, N_));
shared_ptr<Filler<Dtype> > bias_filler(GetFiller<Dtype>(
this->layer_param_.inner_product_param().bias_filler()));
bias_filler->Fill(this->blobs_[1].get());
}
} // parameter initialization
this->param_propagate_down_.resize(this->blobs_.size(), true);
}
template <typename Dtype>
void InnerProductLayer<Dtype>::Reshape(const vector<Blob<Dtype>*>& bottom,
vector<Blob<Dtype>*>* top) {
// Figure out the dimensions
M_ = bottom[0]->num();
CHECK_EQ(bottom[0]->count() / bottom[0]->num(), K_) << "Input size "
"incompatible with inner product parameters.";
(*top)[0]->Reshape(bottom[0]->num(), N_, 1, 1);
// Set up the bias multiplier
if (bias_term_) {
bias_multiplier_.Reshape(1, 1, 1, M_);
caffe_set(M_, Dtype(1), bias_multiplier_.mutable_cpu_data());
}
}这里的构造函数主要就是设置属性变量(前面介绍过了),以及权重初始化(如果有偏置,也将其初始化)。
5.4 前馈反馈函数:
前馈:
template <typename Dtype>
void InnerProductLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom,
vector<Blob<Dtype>*>* top) {
const Dtype* bottom_data = bottom[0]->cpu_data();
Dtype* top_data = (*top)[0]->mutable_cpu_data();
const Dtype* weight = this->blobs_[0]->cpu_data();
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasTrans, M_, N_, K_, (Dtype)1.,
bottom_data, weight, (Dtype)0., top_data);
if (bias_term_) {
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, M_, N_, 1, (Dtype)1.,
bias_multiplier_.cpu_data(),
this->blobs_[1]->cpu_data(), (Dtype)1., top_data);
}
}前馈是非常好理解的,直接按照公式计算就好了。
反馈:
template <typename Dtype>
void InnerProductLayer<Dtype>::Backward_cpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down,
vector<Blob<Dtype>*>* bottom) {
if (this->param_propagate_down_[0]) {
const Dtype* top_diff = top[0]->cpu_diff();
const Dtype* bottom_data = (*bottom)[0]->cpu_data();
// Gradient with respect to weight
caffe_cpu_gemm<Dtype>(CblasTrans, CblasNoTrans, N_, K_, M_, (Dtype)1.,
top_diff, bottom_data, (Dtype)0., this->blobs_[0]->mutable_cpu_diff());
}
if (bias_term_ && this->param_propagate_down_[1]) {
const Dtype* top_diff = top[0]->cpu_diff();
// Gradient with respect to bias
caffe_cpu_gemv<Dtype>(CblasTrans, M_, N_, (Dtype)1., top_diff,
bias_multiplier_.cpu_data(), (Dtype)0.,
this->blobs_[1]->mutable_cpu_diff());
}
if (propagate_down[0]) {
const Dtype* top_diff = top[0]->cpu_diff();
// Gradient with respect to bottom data
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, M_, K_, N_, (Dtype)1.,
top_diff, this->blobs_[0]->cpu_data(), (Dtype)0.,
(*bottom)[0]->mutable_cpu_diff());
}
}根据前面反馈原理的介绍,这里的计算也大概就明白了,在对偏置b求导的过程中,用到了参数bias_multiplier_.cpu_data(),该值通常被设置为1。
另外可能比较好奇,为啥会计算这么多的偏导呢?看看BP原理,或者其他神经网络的反馈链式法则就会明白。
6 MVNLayer:
Normalizes the input to have 0-mean and/or unit (1) variance.
6.1 原理介绍:
前馈:
通常我们说到的标准化(或者说规范化)包括两个步骤:
1 中心化:
2 归一化:
所以标准化就是:
也就是数据减去均值除以标准差。
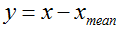
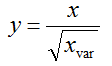
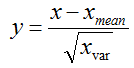
反馈:
1 如果只做了中心化,那么反馈很简单:
2 如果做了标准化,那么反馈就比较复杂了:
严格按照链式法则,这个时候的反馈应该是这样的,也就是说还需要计算方差。
但是源码中却计算得更复杂,似乎基本按照了前馈计算的时候一致了,不过这里的均值计算更加复杂。详情见后面源码。为什么会这样计算,我也没有弄明白!
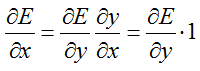
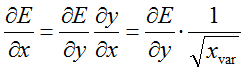
6.2 属性变量:
Blob<Dtype> mean_, variance_, temp_;
/// sum_multiplier is used to carry out sum using BLAS
Blob<Dtype> sum_multiplier_;这里的均值方差,貌似不同的图片,不同的通道,都是不一样的,因为从 Reshape()函数中可以看到其详细的数据结构。
temp_的话,只是一个中间变量而已,跟top,bottom的尺寸大小一样。
6.3 构造函数:
template <typename Dtype>
void MVNLayer<Dtype>::Reshape(const vector<Blob<Dtype>*>& bottom,
vector<Blob<Dtype>*>* top) {
(*top)[0]->Reshape(bottom[0]->num(), bottom[0]->channels(),
bottom[0]->height(), bottom[0]->width());
mean_.Reshape(bottom[0]->num(), bottom[0]->channels(),
1, 1);
variance_.Reshape(bottom[0]->num(), bottom[0]->channels(),
1, 1);
temp_.Reshape(bottom[0]->num(), bottom[0]->channels(),
bottom[0]->height(), bottom[0]->width());
sum_multiplier_.Reshape(1, 1,
bottom[0]->height(), bottom[0]->width());
Dtype* multiplier_data = sum_multiplier_.mutable_cpu_data();
caffe_set(sum_multiplier_.count(), Dtype(1), multiplier_data);
}注意其中对sum_multiplier_的初始化,每个值都赋值为1了得。
6.4 前馈反馈函数:
前馈:
template <typename Dtype>
void MVNLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom,
vector<Blob<Dtype>*>* top) {
const Dtype* bottom_data = bottom[0]->cpu_data();
Dtype* top_data = (*top)[0]->mutable_cpu_data();
int num;
if (this->layer_param_.mvn_param().across_channels())
num = bottom[0]->num();
else
num = bottom[0]->num() * bottom[0]->channels();
int dim = bottom[0]->count() / num;
Dtype eps = 1e-10;
if (this->layer_param_.mvn_param().normalize_variance()) {
// put the squares of bottom into temp_
caffe_powx(bottom[0]->count(), bottom_data, Dtype(2),
temp_.mutable_cpu_data());
// computes variance using var(X) = E(X^2) - (EX)^2
caffe_cpu_gemv<Dtype>(CblasNoTrans, num, dim, 1. / dim, bottom_data,
sum_multiplier_.cpu_data(), 0., mean_.mutable_cpu_data()); // EX
caffe_cpu_gemv<Dtype>(CblasNoTrans, num, dim, 1. / dim, temp_.cpu_data(),
sum_multiplier_.cpu_data(), 0.,
variance_.mutable_cpu_data()); // E(X^2)
caffe_powx(mean_.count(), mean_.cpu_data(), Dtype(2),
temp_.mutable_cpu_data()); // (EX)^2
caffe_sub(mean_.count(), variance_.cpu_data(), temp_.cpu_data(),
variance_.mutable_cpu_data()); // variance
// do mean and variance normalization
// subtract mean
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, num, dim, 1, -1.,
mean_.cpu_data(), sum_multiplier_.cpu_data(), 0.,
temp_.mutable_cpu_data());
caffe_add(temp_.count(), bottom_data, temp_.cpu_data(), top_data);
// normalize variance
caffe_powx(variance_.count(), variance_.cpu_data(), Dtype(0.5),
variance_.mutable_cpu_data());
caffe_add_scalar(variance_.count(), eps, variance_.mutable_cpu_data());
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, num, dim, 1, 1.,
variance_.cpu_data(), sum_multiplier_.cpu_data(), 0.,
temp_.mutable_cpu_data());
caffe_div(temp_.count(), top_data, temp_.cpu_data(), top_data);
} else {
caffe_cpu_gemv<Dtype>(CblasNoTrans, num, dim, 1. / dim, bottom_data,
sum_multiplier_.cpu_data(), 0., mean_.mutable_cpu_data()); // EX
// subtract mean
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, num, dim, 1, -1.,
mean_.cpu_data(), sum_multiplier_.cpu_data(), 0.,
temp_.mutable_cpu_data());
caffe_add(temp_.count(), bottom_data, temp_.cpu_data(), top_data);
}
}在统计学里面可以找到方差的计算方式不仅仅只有高中课本那种方法,还可以:
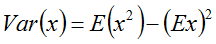
在上面的前馈函数中也就是这样去计算的。
先将 x^2 计算出来存放在中间变量 temp_ 中;
在计算 x的均值,存在在变量 mean_ 中;
接着计算 方差的中间变量,存放在 variance_ 中;这里计算的中间结果是:variance_ = 1/n * temp_ = 1/n * x^2,也就是E(x^2)
再接着计算 均值的平方,存放在变量 temp_ 中;这里的计算是:temp_ = mean_^2 = (1/n * x)^2,也就是(Ex)^2
最后得到方差结果,存放在变量 variance_ 中;这里的计算是:variance_ = variance_ - temp_ = E(x^2) - (Ex)^2
得到方差之后,标准化才刚刚开始:
先将数据减掉均值,存放在top中;top = bottom - mean_
再将方差开根号,存放在variance_中,也就是标准差;variance_ = (variance_)^(0.5)
在 variance_ 上加上一个很小的实数,存放在variance_中;这是因为标准化的时候要除以这个variance_,为了避免报错吧。
将标准差数据放入temp_中;
最后除以temp_;top = top/temp_
整个标准化过程结束。其中用到了很多次sum_multiplier_变量,前面介绍过,这个变量中全部都存放的是1,那么它起到的是什么作用呢?注意前面的if判断,这个标准化过程是通道内进行还是通道间进行。再后面的if判断,是否用标准差进行标准化,如果不用标准差,相当于只是做了中心化,而不做归一化。标准化是包括了中心化和归一化两个步骤的!
所以,如果只做中心化时,也就是else的部分,就很简单:top = bottom - mean_
反馈:
template <typename Dtype>
void MVNLayer<Dtype>::Backward_cpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down,
vector<Blob<Dtype>*>* bottom) {
const Dtype* top_diff = top[0]->cpu_diff();
const Dtype* top_data = top[0]->cpu_data();
const Dtype* bottom_data = (*bottom)[0]->cpu_data();
Dtype* bottom_diff = (*bottom)[0]->mutable_cpu_diff();
int num;
if (this->layer_param_.mvn_param().across_channels())
num = (*bottom)[0]->num();
else
num = (*bottom)[0]->num() * (*bottom)[0]->channels();
int dim = (*bottom)[0]->count() / num;
Dtype eps = 1e-10;
if (this->layer_param_.mvn_param().normalize_variance()) {
caffe_mul(temp_.count(), top_data, top_diff, bottom_diff);
caffe_cpu_gemv<Dtype>(CblasNoTrans, num, dim, 1., bottom_diff,
sum_multiplier_.cpu_data(), 0., mean_.mutable_cpu_data());
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, num, dim, 1, 1.,
mean_.cpu_data(), sum_multiplier_.cpu_data(), 0.,
bottom_diff);
caffe_mul(temp_.count(), top_data, bottom_diff, bottom_diff);
caffe_cpu_gemv<Dtype>(CblasNoTrans, num, dim, 1., top_diff,
sum_multiplier_.cpu_data(), 0., mean_.mutable_cpu_data());
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, num, dim, 1, 1.,
mean_.cpu_data(), sum_multiplier_.cpu_data(), 1.,
bottom_diff);
caffe_cpu_axpby(temp_.count(), Dtype(1), top_diff, Dtype(-1. / dim),
bottom_diff);
// put the squares of bottom into temp_
caffe_powx(temp_.count(), bottom_data, Dtype(2),
temp_.mutable_cpu_data());
// computes variance using var(X) = E(X^2) - (EX)^2
caffe_cpu_gemv<Dtype>(CblasNoTrans, num, dim, 1. / dim, bottom_data,
sum_multiplier_.cpu_data(), 0., mean_.mutable_cpu_data()); // EX
caffe_cpu_gemv<Dtype>(CblasNoTrans, num, dim, 1. / dim, temp_.cpu_data(),
sum_multiplier_.cpu_data(), 0.,
variance_.mutable_cpu_data()); // E(X^2)
caffe_powx(mean_.count(), mean_.cpu_data(), Dtype(2),
temp_.mutable_cpu_data()); // (EX)^2
caffe_sub(mean_.count(), variance_.cpu_data(), temp_.cpu_data(),
variance_.mutable_cpu_data()); // variance
// normalize variance
caffe_powx(variance_.count(), variance_.cpu_data(), Dtype(0.5),
variance_.mutable_cpu_data());
caffe_add_scalar(variance_.count(), eps, variance_.mutable_cpu_data());
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, num, dim, 1, 1.,
variance_.cpu_data(), sum_multiplier_.cpu_data(), 0.,
temp_.mutable_cpu_data());
caffe_div(temp_.count(), bottom_diff, temp_.cpu_data(), bottom_diff);
} else {
caffe_copy(temp_.count(), top_diff, bottom_diff);
}
}我们先来解析不标准化,只中心化的反馈过程,程序中很简单,直接将top层的误差作为bottom的误差。很容易理解。
但是如果前馈是标准化的过程,反馈的时候,在源码中的体现太复杂了,具体为什么要这样计算我也不明白,在计算方差之前的一大堆都是在计算均值,然后就是top_diff减掉那个均值,存放在bottom_diff中。最后计算出了标准差,再用bottom_diff除以这个标准差。如果只是单纯的除以标准差,我觉得就很好理解了。但是源码看起来不仅仅除以标准差了!
7 SilenceLayer:
Ignores bottom blobs while producing no top blobs. (This is useful to suppress outputs during testing.)
呃,这个感觉可以忽略的样子,不知道起到了什么作用。函数也只有一个:
template <typename Dtype>
void SilenceLayer<Dtype>::Backward_cpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down, vector<Blob<Dtype>*>* bottom) {
for (int i = 0; i < bottom->size(); ++i) {
if (propagate_down[i]) {
caffe_set((*bottom)[i]->count(), Dtype(0),
(*bottom)[i]->mutable_cpu_data());
}
}
}只有一个反馈,而且是如果要方向传播的话,就直接把底层数据全部设置为0??!!
这想达到一个什么样的效果呢?
8 SoftmaxLayer:
Computes the softmax function.
8.1 原理介绍:
具体原理可以参考斯坦福的Softmax回归
8.2 属性变量:
/// sum_multiplier is used to carry out sum using BLAS
Blob<Dtype> sum_multiplier_;
/// scale is an intermediate Blob to hold temporary results.
Blob<Dtype> scale_;这里一样涉及到一个属性变量 sum_multiplier_,在MVNLayer当中同样出现了。其注释都是:sum_multiplier is used to carry out sum using BLAS。
举个例子:向量A=[1 2 3],向量B=[1 1 1],那么A*B=sum(A(i)*B(i)) =6。而sum_multiplier_的作用就是这个例子中的向量B。
scale_已经有了注释,是用于存放中间结果的。
8.3 构造函数:
template <typename Dtype>
void SoftmaxLayer<Dtype>::Reshape(const vector<Blob<Dtype>*>& bottom,
vector<Blob<Dtype>*>* top) {
(*top)[0]->Reshape(bottom[0]->num(), bottom[0]->channels(),
bottom[0]->height(), bottom[0]->width());
sum_multiplier_.Reshape(1, bottom[0]->channels(), 1, 1);
Dtype* multiplier_data = sum_multiplier_.mutable_cpu_data();
for (int i = 0; i < sum_multiplier_.count(); ++i) {
multiplier_data[i] = 1.;
}
scale_.Reshape(bottom[0]->num(), 1, bottom[0]->height(), bottom[0]->width());
}这里的sum_multiplier_一样全部被初始化为1了的。而scale_的大小尺寸有点奇怪,在批处理的时候通常都会有num这个东西来表示数量,而scale又是单通道的。
大概是要将所有通道的数据的计算结果全部放在一起吧。
8.4 前馈反馈函数:
前馈:
template <typename Dtype>
void SoftmaxLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom,
vector<Blob<Dtype>*>* top) {
const Dtype* bottom_data = bottom[0]->cpu_data();
Dtype* top_data = (*top)[0]->mutable_cpu_data();
Dtype* scale_data = scale_.mutable_cpu_data();
int num = bottom[0]->num();
int channels = bottom[0]->channels();
int dim = bottom[0]->count() / bottom[0]->num();
int spatial_dim = bottom[0]->height() * bottom[0]->width();
caffe_copy(bottom[0]->count(), bottom_data, top_data);
// We need to subtract the max to avoid numerical issues, compute the exp,
// and then normalize.
for (int i = 0; i < num; ++i) {
// initialize scale_data to the first plane
caffe_copy(spatial_dim, bottom_data + i * dim, scale_data);
for (int j = 0; j < channels; j++) {
for (int k = 0; k < spatial_dim; k++) {
scale_data[k] = std::max(scale_data[k],
bottom_data[i * dim + j * spatial_dim + k]);
}
}
// subtraction
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, channels, spatial_dim,
1, -1., sum_multiplier_.cpu_data(), scale_data, 1., top_data + i * dim);
// exponentiation
caffe_exp<Dtype>(dim, top_data + i * dim, top_data + i * dim);
// sum after exp
caffe_cpu_gemv<Dtype>(CblasTrans, channels, spatial_dim, 1.,
top_data + i * dim, sum_multiplier_.cpu_data(), 0., scale_data);
// division
for (int j = 0; j < channels; j++) {
caffe_div(spatial_dim, top_data + (*top)[0]->offset(i, j), scale_data,
top_data + (*top)[0]->offset(i, j));
}
}
}从代码中可以看到,前馈的时候,批处理中每个图像是分别处理的:
先将某个图像按照通道维度计算最大值,存入scale_data中,所以感觉上scale_data只需要height*width大小的存储空间就够了,但是实际上却开辟了num*height*width。
这里的前馈计算过程中可能与斯坦福的介绍稍微有点差别,不过原理上都是一样的,这里的前馈计算如下:
假设某一个图像在某一个(channel, height, width)的坐标上的数据为x,在通道(channel, :, :)上的最大值为x_max;
在for后面的两个小for里面就是计算这个x_max;
之后的计算可以理解成遍历该通道的所有数据:(实际上是所有通道一起计算的)
之后再计算: x - x_max;
再之后计算指数:exp(x-x_max);
在求和这些指数:sum(x: exp(x-x_max));
最后再用除法,即:
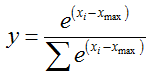
在源码中解释道了为什么要减去最大值,这是因为避免所谓的“数值问题”,那么到底是什么问题呢?我们知道指数函数是一个严格递增的函数,如果直接使用x的话,可能会造成大数吃小数的问题,因为sum的分母会因为某一个x很大而整体很大,其余的很多小x都会因此变得非常小。估计源码中说到的就是这个问题吧。
整个前馈过程看完了,还是不明白为啥scale_data开辟的空间会比实际使用的大很多呢?
反馈:
template <typename Dtype>
void SoftmaxLayer<Dtype>::Backward_cpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down,
vector<Blob<Dtype>*>* bottom) {
const Dtype* top_diff = top[0]->cpu_diff();
const Dtype* top_data = top[0]->cpu_data();
Dtype* bottom_diff = (*bottom)[0]->mutable_cpu_diff();
Dtype* scale_data = scale_.mutable_cpu_data();
int num = top[0]->num();
int channels = top[0]->channels();
int dim = top[0]->count() / top[0]->num();
int spatial_dim = top[0]->height() * top[0]->width();
caffe_copy(top[0]->count(), top_diff, bottom_diff);
for (int i = 0; i < num; ++i) {
// compute dot(top_diff, top_data) and subtract them from the bottom diff
for (int k = 0; k < spatial_dim; ++k) {
scale_data[k] = caffe_cpu_strided_dot<Dtype>(channels,
bottom_diff + i * dim + k, spatial_dim,
top_data + i * dim + k, spatial_dim);
}
// subtraction
caffe_cpu_gemm<Dtype>(CblasNoTrans, CblasNoTrans, channels, spatial_dim, 1,
-1., sum_multiplier_.cpu_data(), scale_data, 1., bottom_diff + i * dim);
}
// elementwise multiplication
caffe_mul(top[0]->count(), bottom_diff, top_data, bottom_diff);
}反馈的过程其实很优雅,说优雅是因为softmax本身就非常优雅,看似很复杂的函数表达式,导数的计算确实非常的简便:
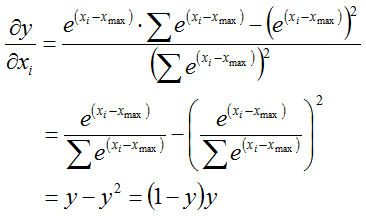
所以,误差传递过程是:
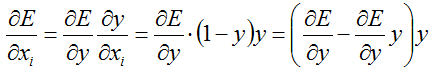
这个误差传递的过程,也是源码的计算思路过程:
先直接将top_diff存入bottom_diff中;
再计算这个误差与top_data的乘积存放在scale_data中;
在计算误差减掉scale_data,还是存放在bottom_diff中;
最后再计算bottom_diif与top_data的乘积,存入bottom_diff中。
9 SplitLayer:
Creates a "split" path in the network by copying the bottom Blob into multiple top Blob%s to be used by multiple consuming layers.
该层没有什么好说的,简单的将bottom数据拷贝到多个top中,反馈的时候也很简单,将多个top_diff的数据累加到bottom_diff中,该层的所有源码如下:
template <typename Dtype>
void SplitLayer<Dtype>::Reshape(const vector<Blob<Dtype>*>& bottom,
vector<Blob<Dtype>*>* top) {
count_ = bottom[0]->count();
for (int i = 0; i < top->size(); ++i) {
// Do not allow in-place computation in the SplitLayer. Instead, share data
// by reference in the forward pass, and keep separate diff allocations in
// the backward pass. (Technically, it should be possible to share the diff
// blob of the first split output with the input, but this seems to cause
// some strange effects in practice...)
CHECK_NE((*top)[i], bottom[0]) << this->type_name() << " Layer does not "
"allow in-place computation.";
(*top)[i]->Reshape(bottom[0]->num(), bottom[0]->channels(),
bottom[0]->height(), bottom[0]->width());
CHECK_EQ(count_, (*top)[i]->count());
}
}
template <typename Dtype>
void SplitLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom,
vector<Blob<Dtype>*>* top) {
for (int i = 0; i < top->size(); ++i) {
(*top)[i]->ShareData(*bottom[0]);
}
}
template <typename Dtype>
void SplitLayer<Dtype>::Backward_cpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down, vector<Blob<Dtype>*>* bottom) {
if (!propagate_down[0]) { return; }
if (top.size() == 1) {
caffe_copy(count_, top[0]->cpu_diff(), (*bottom)[0]->mutable_cpu_diff());
return;
}
caffe_add(count_, top[0]->cpu_diff(), top[1]->cpu_diff(),
(*bottom)[0]->mutable_cpu_diff());
// Add remaining top blob diffs.
for (int i = 2; i < top.size(); ++i) {
const Dtype* top_diff = top[i]->cpu_diff();
Dtype* bottom_diff = (*bottom)[0]->mutable_cpu_diff();
caffe_axpy(count_, Dtype(1.), top_diff, bottom_diff);
}
}10 SliceLayer:
Takes a Blob and slices it along either the num or channel dimension, outputting multiple sliced Blob results.
10.1 原理介绍:
将bottom的数据按照某个维度进行分割,将各个分割的切片存入不同的top中。所以反馈的时候不会像SplitLayer那样会把top_diff的数据累加起来,而SliceLayer只需要将对应位置的top_diff拷贝到对应位置的bottom_diff中即可。
10.2 属性变量:
Blob<Dtype> col_bob_;
int count_;
int num_;
int channels_;
int height_;
int width_;
int slice_dim_;
vector<int> slice_point_;这些变量中,可能作为焦点的就是slice_dim_变量了,该变量在LayerSetUp()中被赋值的,从中可以看到slice_dim_的取值只能为0或者1。
另外就是slice_point_变量了,存放的是具体分割点。
很奇怪的是,在该层中没有用到col_bob_的样子嘛,为啥会有这个变量呢?
10.3 构造函数:
template <typename Dtype>
void SliceLayer<Dtype>::LayerSetUp(const vector<Blob<Dtype>*>& bottom,
vector<Blob<Dtype>*>* top) {
const SliceParameter& slice_param = this->layer_param_.slice_param();
slice_dim_ = slice_param.slice_dim();
CHECK_GE(slice_dim_, 0);
CHECK_LE(slice_dim_, 1) << "Can only slice num and channels";
slice_point_.clear();
std::copy(slice_param.slice_point().begin(),
slice_param.slice_point().end(),
std::back_inserter(slice_point_));
}
template <typename Dtype>
void SliceLayer<Dtype>::Reshape(const vector<Blob<Dtype>*>& bottom,
vector<Blob<Dtype>*>* top) {
count_ = 0;
num_ = bottom[0]->num();
channels_ = bottom[0]->channels();
height_ = bottom[0]->height();
width_ = bottom[0]->width();
if (slice_point_.size() != 0) {
CHECK_EQ(slice_point_.size(), top->size() - 1);
if (slice_dim_ == 0) {
CHECK_LE(top->size(), num_);
} else {
CHECK_LE(top->size(), channels_);
}
int prev = 0;
vector<int> slices;
for (int i = 0; i < slice_point_.size(); ++i) {
CHECK_GT(slice_point_[i], prev);
slices.push_back(slice_point_[i] - prev);
prev = slice_point_[i];
}
if (slice_dim_ == 0) {
slices.push_back(num_ - prev);
for (int i = 0; i < top->size(); ++i) {
(*top)[i]->Reshape(slices[i], channels_, height_, width_);
count_ += (*top)[i]->count();
}
} else {
slices.push_back(channels_ - prev);
for (int i = 0; i < top->size(); ++i) {
(*top)[i]->Reshape(num_, slices[i], height_, width_);
count_ += (*top)[i]->count();
}
}
} else {
if (slice_dim_ == 0) {
CHECK_EQ(num_ % top->size(), 0)
<< "Number of top blobs (" << top->size() << ") "
<< "should evenly divide input num ( " << num_ << ")";
num_ = num_ / top->size();
} else {
CHECK_EQ(channels_ % top->size(), 0)
<< "Number of top blobs (" << top->size() << ") "
<< "should evenly divide input channels ( " << channels_ << ")";
channels_ = channels_ / top->size();
}
for (int i = 0; i < top->size(); ++i) {
(*top)[i]->Reshape(num_, channels_, height_, width_);
count_ += (*top)[i]->count();
}
}
CHECK_EQ(count_, bottom[0]->count());
}别看这里的构造函数一大堆,其实就是各种检测,然后初始化top层的数据大小。
10.4 前馈反馈函数:
前馈反馈都是一个数据拷贝的过程,没啥好说的。代码如下:
前馈:
template <typename Dtype>
void SliceLayer<Dtype>::Forward_cpu(const vector<Blob<Dtype>*>& bottom,
vector<Blob<Dtype>*>* top) {
const Dtype* bottom_data = bottom[0]->mutable_cpu_data();
if (slice_dim_ == 0) {
int offset_num = 0;
for (int i = 0; i < top->size(); ++i) {
Blob<Dtype>* blob = (*top)[i];
Dtype* top_data = blob->mutable_cpu_data();
caffe_copy(blob->count(), bottom_data + bottom[0]->offset(offset_num),
top_data);
offset_num += blob->num();
}
} else if (slice_dim_ == 1) {
int offset_channel = 0;
for (int i = 0; i < top->size(); ++i) {
Blob<Dtype>* blob = (*top)[i];
Dtype* top_data = blob->mutable_cpu_data();
const int num_elem = blob->channels() * blob->height() * blob->width();
for (int n = 0; n < num_; ++n) {
caffe_copy(num_elem, bottom_data + bottom[0]->offset(n, offset_channel),
top_data + blob->offset(n));
}
offset_channel += blob->channels();
}
} // slice_dim_ is guaranteed to be 0 or 1 by SetUp.
}反馈:
template <typename Dtype>
void SliceLayer<Dtype>::Backward_cpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down, vector<Blob<Dtype>*>* bottom) {
if (!propagate_down[0]) { return; }
Dtype* bottom_diff = (*bottom)[0]->mutable_cpu_diff();
if (slice_dim_ == 0) {
int offset_num = 0;
for (int i = 0; i < top.size(); ++i) {
Blob<Dtype>* blob = top[i];
const Dtype* top_diff = blob->cpu_diff();
caffe_copy(blob->count(), top_diff,
bottom_diff + (*bottom)[0]->offset(offset_num));
offset_num += blob->num();
}
} else if (slice_dim_ == 1) {
int offset_channel = 0;
for (int i = 0; i < top.size(); ++i) {
Blob<Dtype>* blob = top[i];
const Dtype* top_diff = blob->cpu_diff();
const int num_elem = blob->channels() * blob->height() * blob->width();
for (int n = 0; n < num_; ++n) {
caffe_copy(num_elem, top_diff + blob->offset(n),
bottom_diff + (*bottom)[0]->offset(n, offset_channel));
}
offset_channel += blob->channels();
}
} // slice_dim_ is guaranteed to be 0 or 1 by SetUp.
}













 1104
1104











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









