







这是caffe官方文档Notebook Examples中的第二个例子,链接地址:http://nbviewer.jupyter.org/github/BVLC/caffe/blob/master/examples/01-learning-lenet.ipynb
这个例子使用LeNet对手写数字分类。LeNet的结构可以参考:http://blog.csdn.net/thystar/article/details/50470325
1. 改变工作目录:
import os
caffe_root = '/home/sindyz/caffe-master/'
os.chdir(caffe_root)
2. 导入相应的包
import sys
sys.path.insert(0, './python')
import caffe
from pylab import *
%matplotlib inline3. 获取数据
如果已经下载过,这步可以不要
# Download and prepare data
!data/mnist/get_mnist.sh
!examples/mnist/create_mnist.sh4. 写LeNet网络结构,分别命名为lenet_auto_train.prototxt和lenet_auto_test.prototxt
from caffe import layers as L
from caffe import params as P
def lenet(lmdb, batch_size):
# our version of LeNet: a series of linear and simple nonlinear transformations
n = caffe.NetSpec()
n.data, n.label = L.Data(batch_size=batch_size, backend=P.Data.LMDB, source=lmdb,
transform_param=dict(scale=1./255), ntop=2)
n.conv1 = L.Convolution(n.data, kernel_size=5, num_output=20, weight_filler=dict(type='xavier'))
n.pool1 = L.Pooling(n.conv1, kernel_size=2, stride=2, pool=P.Pooling.MAX)
n.conv2 = L.Convolution(n.pool1, kernel_size=5, num_output=50, weight_filler=dict(type='xavier'))
n.pool2 = L.Pooling(n.conv2, kernel_size=2, stride=2, pool=P.Pooling.MAX)
n.ip1 = L.InnerProduct(n.pool2, num_output=500, weight_filler=dict(type='xavier'))
n.relu1 = L.ReLU(n.ip1, in_place=True)
n.ip2 = L.InnerProduct(n.relu1, num_output=10, weight_filler=dict(type='xavier'))
n.loss = L.SoftmaxWithLoss(n.ip2, n.label)
return n.to_proto()
with open('examples/mnist/lenet_auto_train.prototxt', 'w') as f:
f.write(str(lenet('examples/mnist/mnist_train_lmdb', 64)))
with open('examples/mnist/lenet_auto_test.prototxt', 'w') as f:
f.write(str(lenet('examples/mnist/mnist_test_lmdb', 100)))
5. 查看网络结构
!cat examples/mnist/lenet_auto_train.prototxt输出:
layer {
name: "data"
type: "Data"
top: "data"
top: "label"
transform_param {
scale: 0.00392156862745
}
data_param {
source: "examples/mnist/mnist_train_lmdb"
batch_size: 64
backend: LMDB
}
}
layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
convolution_param {
num_output: 20
kernel_size: 5
weight_filler {
type: "xavier"
}
}
}
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "conv2"
type: "Convolution"
bottom: "pool1"
top: "conv2"
convolution_param {
num_output: 50
kernel_size: 5
weight_filler {
type: "xavier"
}
}
}
layer {
name: "pool2"
type: "Pooling"
bottom: "conv2"
top: "pool2"
pooling_param {
pool: MAX
kernel_size: 2
stride: 2
}
}
layer {
name: "ip1"
type: "InnerProduct"
bottom: "pool2"
top: "ip1"
inner_product_param {
num_output: 500
weight_filler {
type: "xavier"
}
}
}
layer {
name: "relu1"
type: "ReLU"
bottom: "ip1"
top: "ip1"
}
layer {
name: "ip2"
type: "InnerProduct"
bottom: "ip1"
top: "ip2"
inner_product_param {
num_output: 10
weight_filler {
type: "xavier"
}
}
}
layer {
name: "loss"
type: "SoftmaxWithLoss"
bottom: "ip2"
bottom: "label"
top: "loss"
}
6. 查看参数文件,同样是prototxt文件,用带动量的SGD(随机梯度下降),权重衰减,以及特定的学习率:
!cat examples/mnist/lenet_auto_solver.prototxt# The train/test net protocol buffer definition
train_net: "examples/mnist/lenet_auto_train.prototxt"
test_net: "examples/mnist/lenet_auto_test.prototxt"
# test_iter specifies how many forward passes the test should carry out.
# In the case of MNIST, we have test batch size 100 and 100 test iterations,
# covering the full 10,000 testing images.
test_iter: 100
# Carry out testing every 500 training iterations.
test_interval: 500
# The base learning rate, momentum and the weight decay of the network.
base_lr: 0.01
momentum: 0.9
weight_decay: 0.0005
# The learning rate policy
lr_policy: "inv"
gamma: 0.0001
power: 0.75
# Display every 100 iterations
display: 100
# The maximum number of iterations
max_iter: 10000
# snapshot intermediate results
snapshot: 5000
snapshot_prefix: "examples/mnist/lenet"7. 使用GPU,载入solver,这里用SGD,Adagrad和Nesterov加速梯度也是可行的:
这里需要说明一下,caffe的优化函数是非凸的,没有解析解,需要通过优化方法来求解,
caffe封装了三种优化方法:
- Stochastic Gradient Descent (SGD), 随机梯度下降
- AdaptiveGradient (ADAGRAD), 自适应梯度下降
- Nesterov’s Accelerated Gradient (NAG)。Nesterov加速梯度下降法
caffe.set_device(0)
caffe.set_mode_gpu()
solver = caffe.SGDSolver(caffe_root+'/examples/mnist/lenet_auto_solver.prototxt')
8. 查看中间特征(blobs)和参数(params)的维数:
[(k,v.data.shape) for k,v in solver.net.blobs.items()]
[('data', (64, 1, 28, 28)),
('label', (64,)),
('conv1', (64, 20, 24, 24)),
('pool1', (64, 20, 12, 12)),
('conv2', (64, 50, 8, 8)),
('pool2', (64, 50, 4, 4)),
('ip1', (64, 500)),
('ip2', (64, 10)),
('loss', ())]
[(k,v[0].data.shape) for k,v in solver.net.params.items()]
[('conv1', (20, 1, 5, 5)),
('conv2', (50, 20, 5, 5)),
('ip1', (500, 800)),
('ip2', (10, 500))]
9. 在测试集和训练集上执行一个前向的过程
solver.net.forward()
solver.test_nets[0].forward()
{'loss': array(2.2941734790802, dtype=float32)}
10. 显示训练集8个数据的图像和他们的标签,
imshow(solver.net.blobs['data'].data[:8, 0].transpose(1, 0, 2).reshape(28, 8*28), cmap='gray')
print solver.net.blobs['label'].data[:8]
[ 5. 0. 4. 1. 9. 2. 1. 3.]

11. 显示测试集中的8个图像和他们的标签
imshow(solver.test_nets[0].blobs['data'].data[:8, 0].transpose(1, 0, 2).reshape(28, 8*28), cmap='gray')
print solver.test_nets[0].blobs['label'].data[:8]
[ 7. 2. 1. 0. 4. 1. 4. 9.]
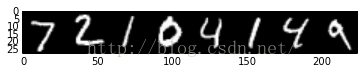
11. 执行无误,则执行一步SGB, 查看权值的变化:
第一层权值的变化如下图:20个5x5规模的滤波器
solver.step(1)
imshow(solver.net.params['conv1'][0].diff[:, 0].reshape(4, 5, 5, 5)
...: .transpose(0, 2, 1, 3).reshape(4*5, 5*5), cmap='gray')

运行网络,这个过程和通过caffe的binary训练是一样的,
12. 控制循环
因为可以控制python中的循环,因此可以做一些其他的事情,例如自定义停止的标准,通过循环更新网络来改变求解过程:
%%time
niter = 200
test_interval = 25
# losses will also be stored in the log
train_loss = zeros(niter)
test_acc = zeros(int(np.ceil(niter / test_interval)))
output = zeros((niter, 8, 10))
# the main solver loop
for it in range(niter):
solver.step(1) # SGD by Caffe
# store the train loss
train_loss[it] = solver.net.blobs['loss'].data
# store the output on the first test batch
# (start the forward pass at conv1 to avoid loading new data)
solver.test_nets[0].forward(start='conv1')
output[it] = solver.test_nets[0].blobs['ip2'].data[:8]
# run a full test every so often
# (Caffe can also do this for us and write to a log, but we show here
# how to do it directly in Python, where more complicated things are easier.)
if it % test_interval == 0:
print 'Iteration', it, 'testing...'
correct = 0
for test_it in range(100):
solver.test_nets[0].forward()
correct += sum(solver.test_nets[0].blobs['ip2'].data.argmax(1)
== solver.test_nets[0].blobs['label'].data)
test_acc[it // test_interval] = correct / 1e4
Iteration 0 testing...
Iteration 25 testing...
Iteration 50 testing...
Iteration 75 testing...
Iteration 100 testing...
Iteration 125 testing...
Iteration 150 testing...
Iteration 175 testing...
CPU times: user 19 s, sys: 6.2 s, total: 25.2 s
Wall time: 24.4 s
13. 画出训练样本损失和测试样本正确率
_, ax1 = subplots()
ax2 = ax1.twinx()
ax1.plot(arange(niter), train_loss)
ax2.plot(test_interval * arange(len(test_acc)), test_acc, 'r')
ax1.set_xlabel('iteration')
ax1.set_ylabel('train loss')
ax2.set_ylabel('test accuracy')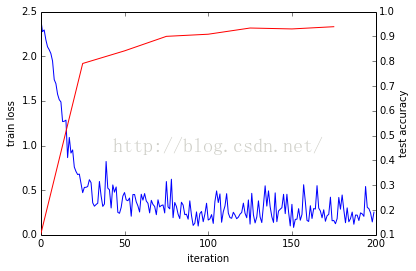
14. 画出分类结果:
for i in range(8):
figure(figsize=(2, 2))
imshow(solver.test_nets[0].blobs['data'].data[i, 0], cmap='gray')
figure(figsize=(10, 2))
imshow(output[:50, i].T, interpolation='nearest', cmap='gray')
xlabel('iteration')
ylabel('label')图像省略,在网站上有的
15. 使用softmax分类
for i in range(8):
figure(figsize=(2, 2))
imshow(solver.test_nets[0].blobs['data'].data[i, 0], cmap='gray')
figure(figsize=(10, 2))
imshow(exp(output[:50, i].T) / exp(output[:50, i].T).sum(0), interpolation='nearest', cmap='gray')
xlabel('iteration')
ylabel('label')
参考网站:
http://nbviewer.jupyter.org/github/BVLC/caffe/blob/master/examples/01-learning-lenet.ipynb














 679
679











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









