







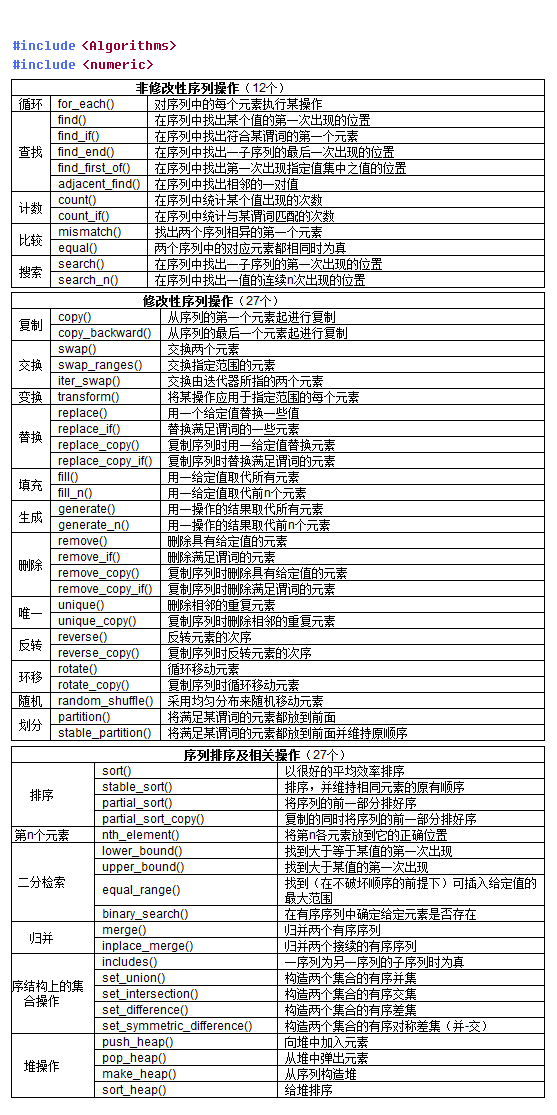
 本文详细介绍了STL中的算法分类及具体实现,包括查找、排序、删除替换等算法,并提供了丰富的代码示例。
本文详细介绍了STL中的算法分类及具体实现,包括查找、排序、删除替换等算法,并提供了丰富的代码示例。
STL算法部分主要由头文件<algorithm>,<numeric>,<functional>组成。要使用 STL中的算法函数必须包含头文件<algorithm>,对于数值算法须包含<numeric>,<functional>中则定义了一些模板类,用来声明函数对象。
first和last-1交换,然后重新生成一个堆。可使用容器的back来访问被"弹出"的元素或者使用pop_back进行真正的删除。重载版本使用自定义的比较操作。
// binary_search example
#include <iostream> // std::cout
#include <algorithm> // std::binary_search, std::sort
#include <vector> // std::vector
bool myfunction (int i,int j) { return (i<j); }
int main () {
int myints[] = {1,2,3,4,5,4,3,2,1};
std::vector<int> v(myints,myints+9); // 1 2 3 4 5 4 3 2 1
// using default comparison:
std::sort (v.begin(), v.end());
std::cout << "looking for a 3... ";
if (std::binary_search (v.begin(), v.end(), 3))
std::cout << "found!\n"; else std::cout << "not found.\n";
// using myfunction as comp:
std::sort (v.begin(), v.end(), myfunction);
std::cout << "looking for a 6... ";
if (std::binary_search (v.begin(), v.end(), 6, myfunction))
std::cout << "found!\n"; else std::cout << "not found.\n";
return 0;
}
//looking for a 3... found!
//looking for a 6... not found// copy algorithm example
#include <iostream> // std::cout
#include <algorithm> // std::copy
#include <vector> // std::vector
int main () {
int myints[]={10,20,30,40,50,60,70};
std::vector<int> myvector (7);
std::copy ( myints, myints+7, myvector.begin() );
std::cout << "myvector contains:";
for (std::vector<int>::iterator it = myvector.begin(); it!=myvector.end(); ++it)
std::cout << ' ' << *it;
std::cout << '\n';
return 0;
}
//myvector contains: 10 20 30 40 50 60 70// copy_if example
#include <iostream> // std::cout
#include <algorithm> // std::copy_if, std::distance
#include <vector> // std::vector
int main () {
std::vector<int> foo = {25,15,5,-5,-15};
std::vector<int> bar (foo.size());
// copy only positive numbers:
auto it = std::copy_if (foo.begin(), foo.end(), bar.begin(), [](int i){return !(i<0);} );
bar.resize(std::distance(bar.begin(),it)); // shrink container to new size
std::cout << "bar contains:";
for (int& x: bar) std::cout << ' ' << x;
std::cout << '\n';
return 0;
}
//bar contains: 25 15 5// copy_n algorithm example
#include <iostream> // std::cout
#include <algorithm> // std::copy
#include <vector> // std::vector
int main () {
int myints[]={10,20,30,40,50,60,70};
std::vector<int> myvector;
myvector.resize(7); // allocate space for 7 elements
std::copy_n ( myints, 7, myvector.begin() );
std::cout << "myvector contains:";
for (std::vector<int>::iterator it = myvector.begin(); it!=myvector.end(); ++it)
std::cout << ' ' << *it;
std::cout << '\n';
return 0;
}
//myvector contains: 10 20 30 40 50 60 70// count algorithm example
#include <iostream> // std::cout
#include <algorithm> // std::count
#include <vector> // std::vector
int main () {
// counting elements in array:
int myints[] = {10,20,30,30,20,10,10,20}; // 8 elements
int mycount = std::count (myints, myints+8, 10);
std::cout << "10 appears " << mycount << " times.\n";
// counting elements in container:
std::vector<int> myvector (myints, myints+8);
mycount = std::count (myvector.begin(), myvector.end(), 20);
std::cout << "20 appears " << mycount << " times.\n";
return 0;
}
//
//10 appears 3 times.
//20 appears 3 times.// count_if example
#include <iostream> // std::cout
#include <algorithm> // std::count_if
#include <vector> // std::vector
bool IsOdd (int i) { return ((i%2)==1); }
int main () {
std::vector<int> myvector;
for (int i=1; i<10; i++) myvector.push_back(i); // myvector: 1 2 3 4 5 6 7 8 9
int mycount = count_if (myvector.begin(), myvector.end(), IsOdd);
std::cout << "myvector contains " << mycount << " odd values.\n";
return 0;
}
//myvector contains 5 odd values.// equal algorithm example
#include <iostream> // std::cout
#include <algorithm> // std::equal
#include <vector> // std::vector
bool mypredicate (int i, int j) {
return (i==j);
}
int main () {
int myints[] = {20,40,60,80,100}; // myints: 20 40 60 80 100
std::vector<int>myvector (myints,myints+5); // myvector: 20 40 60 80 100
// using default comparison:
if ( std::equal (myvector.begin(), myvector.end(), myints) )
std::cout << "The contents of both sequences are equal.\n";
else
std::cout << "The contents of both sequences differ.\n";
myvector[3]=81; // myvector: 20 40 60 81 100
// using predicate comparison:
if ( std::equal (myvector.begin(), myvector.end(), myints, mypredicate) )
std::cout << "The contents of both sequences are equal.\n";
else
std::cout << "The contents of both sequences differ.\n";
return 0;
}
//Output:
//The contents of both sequences are equal.
//The contents of both sequence differ.// find example
#include <iostream> // std::cout
#include <algorithm> // std::find
#include <vector> // std::vector
int main () {
int myints[] = { 10, 20, 30 ,40 };
int * p;
// pointer to array element:
p = std::find (myints,myints+4,30);
++p;
std::cout << "The element following 30 is " << *p << '\n';
std::vector<int> myvector (myints,myints+4);
std::vector<int>::iterator it;
// iterator to vector element:
it = find (myvector.begin(), myvector.end(), 30);
++it;
std::cout << "The element following 30 is " << *it << '\n';
return 0;
}
//Output:
//The element following 30 is 40
//The element following 30 is 40// find_first_of example
#include <iostream> // std::cout
#include <algorithm> // std::find_first_of
#include <vector> // std::vector
#include <cctype> // std::tolower
bool comp_case_insensitive (char c1, char c2) {
return (std::tolower(c1)==std::tolower(c2));
}
int main () {
int mychars[] = {'a','b','c','A','B','C'};
std::vector<char> haystack (mychars,mychars+6);
std::vector<char>::iterator it;
int needle[] = {'A','B','C'};
// using default comparison:
it = find_first_of (haystack.begin(), haystack.end(), needle, needle+3);
if (it!=haystack.end())
std::cout << "The first match is: " << *it << '\n';
// using predicate comparison:
it = find_first_of (haystack.begin(), haystack.end(),
needle, needle+3, comp_case_insensitive);
if (it!=haystack.end())
std::cout << "The first match is: " << *it << '\n';
return 0;
}
//Output:
//The first match is: A
//The first match is: a
// find_end example
#include <iostream> // std::cout
#include <algorithm> // std::find_end
#include <vector> // std::vector
bool myfunction (int i, int j) {
return (i==j);
}
int main () {
int myints[] = {1,2,3,4,5,1,2,3,4,5};
std::vector<int> haystack (myints,myints+10);
int needle1[] = {1,2,3};
// using default comparison:
std::vector<int>::iterator it;
it = std::find_end (haystack.begin(), haystack.end(), needle1, needle1+3);
if (it!=haystack.end())
std::cout << "needle1 last found at position " << (it-haystack.begin()) << '\n';
int needle2[] = {4,5,1};
// using predicate comparison:
it = std::find_end (haystack.begin(), haystack.end(), needle2, needle2+3, myfunction);
if (it!=haystack.end())
std::cout << "needle2 last found at position " << (it-haystack.begin()) << '\n';
return 0;
}
//Output:
//needle1 found at position 5
//needle2 found at position 3
// find_if example
#include <iostream> // std::cout
#include <algorithm> // std::find_if
#include <vector> // std::vector
bool IsOdd (int i) {
return ((i%2)==1);
}
int main () {
std::vector<int> myvector;
myvector.push_back(10);
myvector.push_back(25);
myvector.push_back(40);
myvector.push_back(55);
std::vector<int>::iterator it = std::find_if (myvector.begin(), myvector.end(), IsOdd);
std::cout << "The first odd value is " << *it << '\n';
return 0;
}
//Output:
//The first odd value is 25
// for_each example
#include <iostream> // std::cout
#include <algorithm> // std::for_each
#include <vector> // std::vector
void myfunction (int i) { // function:
std::cout << ' ' << i;
}
struct myclass { // function object type:
void operator() (int i) {std::cout << ' ' << i;}
} myobject;
int main () {
std::vector<int> myvector;
myvector.push_back(10);
myvector.push_back(20);
myvector.push_back(30);
std::cout << "myvector contains:";
for_each (myvector.begin(), myvector.end(), myfunction);
std::cout << '\n';
// or:
std::cout << "myvector contains:";
for_each (myvector.begin(), myvector.end(), myobject);
std::cout << '\n';
return 0;
}
//Output:
//myvector contains: 10 20 30
//myvector contains: 10 20 30
// remove algorithm example
#include <iostream> // std::cout
#include <algorithm> // std::remove
int main () {
int myints[] = {10,20,30,30,20,10,10,20}; // 10 20 30 30 20 10 10 20
// bounds of range:
int* pbegin = myints; // ^
int* pend = myints+sizeof(myints)/sizeof(int); // ^ ^
pend = std::remove (pbegin, pend, 20); // 10 30 30 10 10 ? ? ?
// ^ ^
std::cout << "range contains:";
for (int* p=pbegin; p!=pend; ++p)
std::cout << ' ' << *p;
std::cout << '\n';
return 0;
}
//Output:
//range contains: 10 30 30 10 10
// remove_if example
#include <iostream> // std::cout
#include <algorithm> // std::remove_if
bool IsOdd (int i) { return ((i%2)==1); }
int main () {
int myints[] = {1,2,3,4,5,6,7,8,9}; // 1 2 3 4 5 6 7 8 9
// bounds of range:
int* pbegin = myints; // ^
int* pend = myints+sizeof(myints)/sizeof(int); // ^ ^
pend = std::remove_if (pbegin, pend, IsOdd); // 2 4 6 8 ? ? ? ? ?
// ^ ^
std::cout << "the range contains:";
for (int* p=pbegin; p!=pend; ++p)
std::cout << ' ' << *p;
std::cout << '\n';
return 0;
}
//Output:
//the range contains: 2 4 6 8
// search algorithm example
#include <iostream> // std::cout
#include <algorithm> // std::search
#include <vector> // std::vector
bool mypredicate (int i, int j) {
return (i==j);
}
int main () {
std::vector<int> haystack;
// set some values: haystack: 10 20 30 40 50 60 70 80 90
for (int i=1; i<10; i++) haystack.push_back(i*10);
// using default comparison:
int needle1[] = {40,50,60,70};
std::vector<int>::iterator it;
it = std::search (haystack.begin(), haystack.end(), needle1, needle1+4);
if (it!=haystack.end())
std::cout << "needle1 found at position " << (it-haystack.begin()) << '\n';
else
std::cout << "needle1 not found\n";
// using predicate comparison:
int needle2[] = {20,30,50};
it = std::search (haystack.begin(), haystack.end(), needle2, needle2+3, mypredicate);
if (it!=haystack.end())
std::cout << "needle2 found at position " << (it-haystack.begin()) << '\n';
else
std::cout << "needle2 not found\n";
return 0;
}
//Output:
//match1 found at position 3
//match2 not found// sort algorithm example
#include <iostream> // std::cout
#include <algorithm> // std::sort
#include <vector> // std::vector
bool myfunction (int i,int j) { return (i<j); }
struct myclass {
bool operator() (int i,int j) { return (i<j);}
} myobject;
int main () {
int myints[] = {32,71,12,45,26,80,53,33};
std::vector<int> myvector (myints, myints+8); // 32 71 12 45 26 80 53 33
// using default comparison (operator <):
std::sort (myvector.begin(), myvector.begin()+4); //(12 32 45 71)26 80 53 33
// using function as comp
std::sort (myvector.begin()+4, myvector.end(), myfunction); // 12 32 45 71(26 33 53 80)
// using object as comp
std::sort (myvector.begin(), myvector.end(), myobject); //(12 26 32 33 45 53 71 80)
// print out content:
std::cout << "myvector contains:";
for (std::vector<int>::iterator it=myvector.begin(); it!=myvector.end(); ++it)
std::cout << ' ' << *it;
std::cout << '\n';
return 0;
}
//Output:
//myvector contains: 12 26 32 33 45 53 71 80
// stable_sort example
#include <iostream> // std::cout
#include <algorithm> // std::stable_sort
#include <vector> // std::vector
bool compare_as_ints (double i,double j)
{
return (int(i)<int(j));
}
int main () {
double mydoubles[] = {3.14, 1.41, 2.72, 4.67, 1.73, 1.32, 1.62, 2.58};
std::vector<double> myvector;
myvector.assign(mydoubles,mydoubles+8);
std::cout << "using default comparison:";
std::stable_sort (myvector.begin(), myvector.end());
for (std::vector<double>::iterator it=myvector.begin(); it!=myvector.end(); ++it)
std::cout << ' ' << *it;
std::cout << '\n';
myvector.assign(mydoubles,mydoubles+8);
std::cout << "using 'compare_as_ints' :";
std::stable_sort (myvector.begin(), myvector.end(), compare_as_ints);
for (std::vector<double>::iterator it=myvector.begin(); it!=myvector.end(); ++it)
std::cout << ' ' << *it;
std::cout << '\n';
return 0;
}
//compare_as_ints is a function that compares only the integral part of the elements, therefore, elements with the same integral part are considered equivalent. stable_sort preserves the relative order these had before the call.
//Possible output:
//using default comparison: 1.32 1.41 1.62 1.73 2.58 2.72 3.14 4.67
//using 'compare_as_ints' : 1.41 1.73 1.32 1.62 2.72 2.58 3.14 4.67// swap algorithm example (C++98)
#include <iostream> // std::cout
#include <algorithm> // std::swap
#include <vector> // std::vector
int main () {
int x=10, y=20; // x:10 y:20
std::swap(x,y); // x:20 y:10
std::vector<int> foo (4,x), bar (6,y); // foo:4x20 bar:6x10
std::swap(foo,bar); // foo:6x10 bar:4x20
std::cout << "foo contains:";
for (std::vector<int>::iterator it=foo.begin(); it!=foo.end(); ++it)
std::cout << ' ' << *it;
std::cout << '\n';
return 0;
}
//Output:
//foo contains: 10 10 10 10 10 10
// unique algorithm example
#include <iostream> // std::cout
#include <algorithm> // std::unique, std::distance
#include <vector> // std::vector
bool myfunction (int i, int j) {
return (i==j);
}
int main () {
int myints[] = {10,20,20,20,30,30,20,20,10}; // 10 20 20 20 30 30 20 20 10
std::vector<int> myvector (myints,myints+9);
// using default comparison:
std::vector<int>::iterator it;
it = std::unique (myvector.begin(), myvector.end()); // 10 20 30 20 10 ? ? ? ?
// ^
myvector.resize( std::distance(myvector.begin(),it) ); // 10 20 30 20 10
// using predicate comparison:
std::unique (myvector.begin(), myvector.end(), myfunction); // (no changes)
// print out content:
std::cout << "myvector contains:";
for (it=myvector.begin(); it!=myvector.end(); ++it)
std::cout << ' ' << *it;
std::cout << '\n';
return 0;
}
//Output:
//myvector contains: 10 20 30 20 10
// unique_copy example
#include <iostream> // std::cout
#include <algorithm> // std::unique_copy, std::sort, std::distance
#include <vector> // std::vector
bool myfunction (int i, int j) {
return (i==j);
}
int main () {
int myints[] = {10,20,20,20,30,30,20,20,10};
std::vector<int> myvector (9); // 0 0 0 0 0 0 0 0 0
// using default comparison:
std::vector<int>::iterator it;
it=std::unique_copy (myints,myints+9,myvector.begin()); // 10 20 30 20 10 0 0 0 0
// ^
std::sort (myvector.begin(),it); // 10 10 20 20 30 0 0 0 0
// ^
// using predicate comparison:
it=std::unique_copy (myvector.begin(), it, myvector.begin(), myfunction);
// 10 20 30 20 30 0 0 0 0
// ^
myvector.resize( std::distance(myvector.begin(),it) ); // 10 20 30
// print out content:
std::cout << "myvector contains:";
for (it=myvector.begin(); it!=myvector.end(); ++it)
std::cout << ' ' << *it;
std::cout << '\n';
return 0;
}
//Output:
//myvector contains: 10 20 30
// lower_bound/upper_bound example
#include <iostream> // std::cout
#include <algorithm> // std::lower_bound, std::upper_bound, std::sort
#include <vector> // std::vector
int main () {
int myints[] = {10,20,30,30,20,10,10,20};
std::vector<int> v(myints,myints+8); // 10 20 30 30 20 10 10 20
std::sort (v.begin(), v.end()); // 10 10 10 20 20 20 30 30
std::vector<int>::iterator low,up;
low=std::lower_bound (v.begin(), v.end(), 20); // ^
up= std::upper_bound (v.begin(), v.end(), 20); // ^
std::cout << "lower_bound at position " << (low- v.begin()) << '\n';
std::cout << "upper_bound at position " << (up - v.begin()) << '\n';
return 0;
}
//Output:
//lower_bound at position 3
//upper_bound at position 6
网上实例:http://www.cplusplus.com/reference/algorithm/upper_bound/


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









