









hive:我只用他来检索过日志,对这个谈不上什么精通或熟练,只是会使用而已,可以按需求进行特定的数据检索而已,这个东西很方便,比map-reduce方便很多
你可以把他完全当成mysql来用,因为这个也是用的SQL 语句,存储只不过数据不是存在我们常用的mysql等数据库中
为什么有map-reduce还要有这个hive呢?
我个人的理解是,map-reduce不管你查询什么或计算什么都需要一次任务提交,调度,计算,输出
这个都需要走完应该走的流程,而hive则不一样尽管他是把类似的SQL语句转成map-reduce来处理,
下面几个说明简单的说一下这个是什么?
一:什么是Hive
•Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能。
•本质是将SQL转换为MapReduce程序
二:为什么用Hive
为什么要使用Hive
•操作接口采用类SQL语法,提供快速开发的能力
•避免了去写MapReduce,减少开发人员的学习成本
•扩展功能很方便
三:Hive与Hadoop的关系
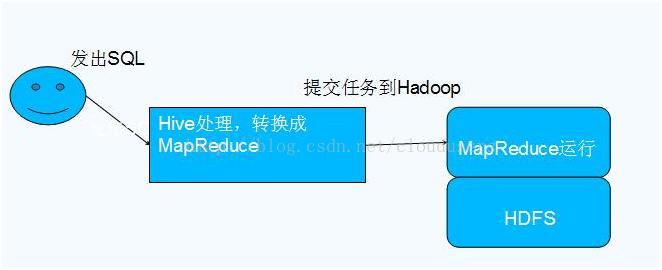
四:数据库对比
|
| Hive | RDBMS |
| 查询语言 | HQL | SQL |
| 数据存储 | HDFS | Raw Device or Local FS |
| 执行 | MapReduce | Excutor |
| 执行延迟 | 高 | 低 |
| 处理数据规模 | 大 | 小 |
| 索引 | 0.8版本后加入位图索引 | 有复杂的索引 |
下面我以数据检索为需求,一步步的把这个用法说清楚(不是理论高度,呵呵,我也没有那个高度)
再次明确一下示例需求: 每天每小时网络上都有一批日志实时的入到hdfs中,例如你在hadoop命令查看如2013-11-30目录下的内容格式如
/home/data/ineternet/2013-11-30/00.log
/home/data/ineternet/2013-11-30/01.log
/home/data/ineternet/2013-11-30/02.log
.....
/home/data/ineternet/2013-11-30/23.log
我们需要可以随时查看某天某个时间的日志信息。
首先,需要创建对应的表,之后才能使用hive SQL来进行查询
而创建表中各项可以根据需要查看的信息进行定制,但在创建表之前需要将日志进行划分partition,这相当于把日志按某种条件分类索引以便按要求查询,
例如示例建表脚本如下:
cat hive.create.sh
#!/bin/bash
hivepath=/home/software/hive//bin
hadooppath=/home/software/hadoop//bin
dirs=$($hadooppath/hadoop fs -ls /home/data/internet/*)
addPartition=
for dir in $dirs
do
#echo $dir
if [[ `expr length $dir` -gt 10 ]]
then
day=`echo $dir|awk --posix -F'/' '{if ($5~/[0-9]{4}-[0-9]{2}-[0-9]{2}/){print $5}}'`
hour=`echo $dir|awk --posix -F'/' '{if ($6~/[0-9]{2}/){print $6}}'`
if [[ `expr length "$day"` -gt 0 && `expr length "$hour"` -gt 0 ]]
then
addPartition=$addPartition" alter table hive_table add partition (day='$day',hour='$hour') location '$dir';"
fi
fi
done
#echo $addPartition
##############################################################
$hivepath/hive << EOF
drop table hive_table;
create external table hive_table
(
time string,
host string,
pid string,
info string,
src string,
stage string,
key string,
ret string
)partitioned by (day string,hour string)
clustered by (key) into 32 buckets
row format delimited fields terminated by '\t'
lines terminated by '\n';
$addPartition
EOF
从上面的脚本可以看到两部分,上面部分是创建partition,即是将天和小时进行划分,下面是根据划分创建表hive_table
后面我们的查询也是基于这个hive_table表
待续














 908
908











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









