







MapReduce 2.0应用场景、原理与基本架构 | mapreduce顺序图 + mapreduce动图
请保留图片来源的权利。
跟着董老师学习hadoop, this is chaper 4
比以前印象更深的是 combiner + partionner
图 MR 内部逻辑
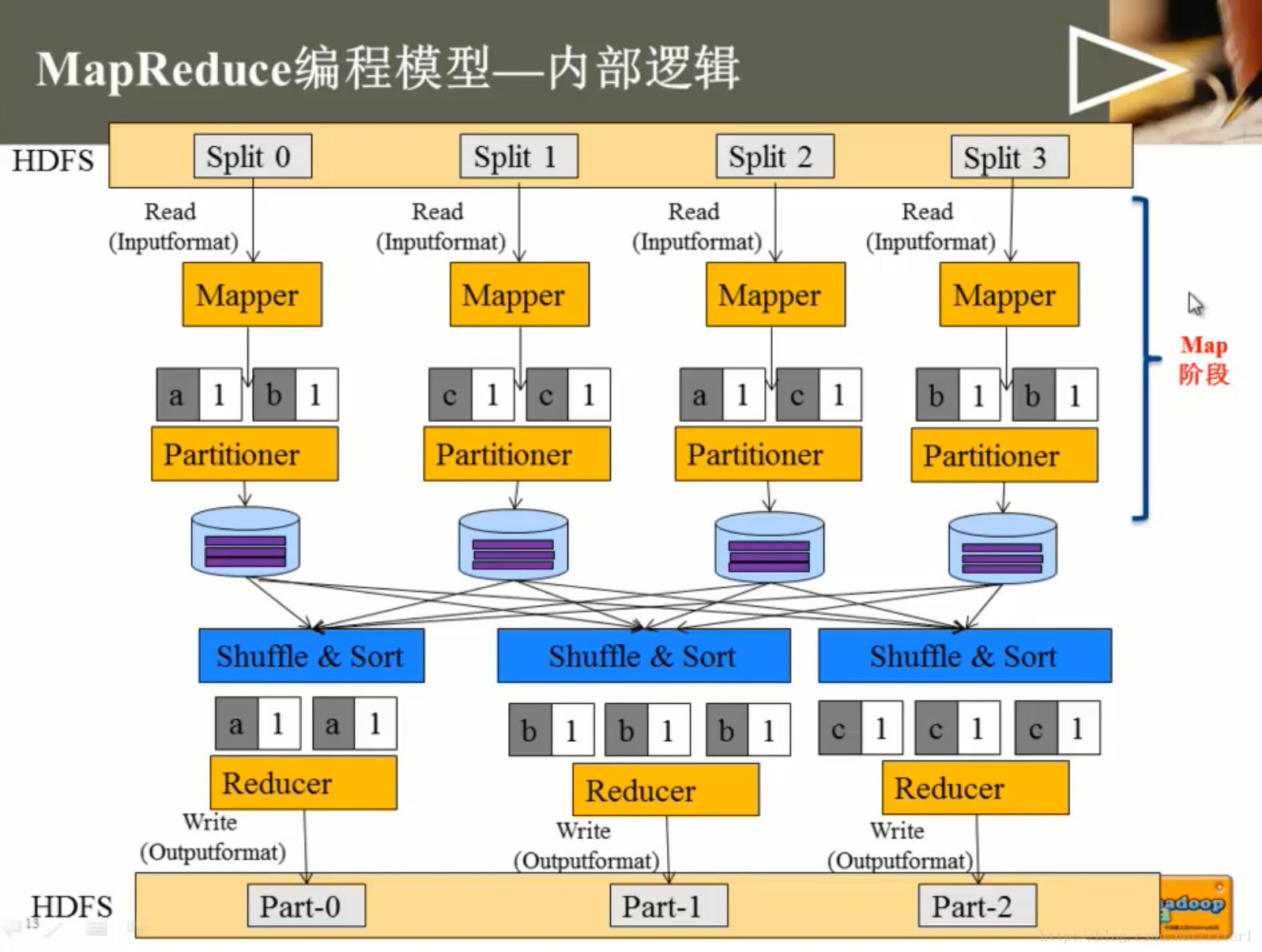
mapreduce动图 演示 MR工作流程

注意图中第4步/第5步:local write, remote read. 这是一次新的认识
mapreduce顺序图 展示MR工作部分细节

- 优点:那就是顺序图的优势哈
- 缺点
- 没有展示partioner的hash过程
- todo:
shuffle排完序,依然还要做一次hdfs 磁盘IO?
MORE
以下只展开基本概念和心得
概念
概念1
Split与Block
Block
HDFS中最小的数据存储单位
默认是64MB
Spit
MapReduce中最小的计算单元
默认与Block一一对应
Block与Split
Split与Block是对应关系是任意的,可由用户控制
概念2
Combiner可做看local reducer
合并相同的key对应的value( wordcount例子)
通常与Reducer逻辑一样
好处
减少Map Task输出数据量(磁盘IO)
减少Reduce-Map网络传输数据量(网络IO)
如何正确使用
结果可叠加
Sum(YES!), Average( NO!)
概念3
Partitioner决定了 Map Task输出的每条数据
交给哪个Reduce Task处理
默认实现: hash(key) mod R
R是Reduce Task数目
允许用户自定义
很多情况需自定义Partitioner
比如“hash(hostname(URL)) mod R”确保相同域
名的网页交给同一个Reduce Task处理
概念4 TaskTracker
66:承上启下的作用
Slave
• 运行Map Task和
Reduce Task
• 与 JobTracker交互,
执行命令,并汇报
任务状态
以上就是各种*tracker
66:mapper的输入时一条一条的,reducer的输入时一组一组的;
概念5 MR2.0 yarn相关节点 *node介绍
5.1 Client
与MapReduce 1.0的Client类似,用户通过Client与YARN
交互,提交MapReduce作业,查询作业运行状态,管理作
业等。
5.2 MRAppMaster
功能类似于 1.0中的JobTracker,但不负责资源管理;
功能包括:任务划分、资源申请并将之二次分配个Map
Task和Reduce Task、任务状态监控和容错
66:资源给resource manager拿去管了。
讲师观点:在mapper/reducer分配过程中,概念Yarn(分化出RM ,MRAppMaster等),
如果把Resource M ,Node M两个概念去除了,跟之前的1.0 (*tracker),就类似了,
66:运行前分任务/分资源,运行时心跳监测/容错。概念6 MapReduce 2.0容错性
…
一旦Task挂掉,则MRAppMaster将为之重新申请资源,
并运行之。最多重新运行次数可由用户设置,默认4次。
讲师说:一旦超过4次无效,那么就丢掉 承包的数据(他负责) 处理
概念7数据本地性( data locality)
如果任务运行在它将处理的数据所在的节点,则称该任务
具有“数据本地性”
本地性可避免跨节点或机架数据传输,提高运行效率
概念8 不能启用推测执行机制
任务间存在严重的负载倾斜
特殊任务,比如任务向数据库中写数据 (避免重复写DB)
讲师说:这是单个作业的属性
二 个人心得
partionner会告知每次map的结果给哪个reducer
每一个reducerer 要对每一个mapper(准备是partionner)生成的结果进行 运程镜像拷贝,其中拉取过程就是shuffle。
更加深入的理解洗牌shuffle机制,这章文章直觉把他作为reduce的一部分所有的排序,就是按照key相同进行归类,而且这是内部实现的
普遍的,map的结果是写在本地磁盘上的,reduce则是放在hdfs
(更新:大部分情况,除了map-only作业,也就是一个作业只有map,没有reduce的特殊场景,mapper就跟hdfs write扯关系了)textinputformat类:输入格式化类 会灵活处理有效的数据被截断的场景。
block是hdfs概念,64M,128M,512M都有, hadoop 2.0 默认128M???(66使用的默认参数)
spit 则是MR最小的计算单元,默认是与block一一对应,当然可以定制















 3438
3438

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









