






1、为什么要用etcd集群?
集群很好理解,毕竟增加了高可用性了,那为什么要用etcd而不实用zookeeper呢?从运维的角度来看,zk难以维护,而etcd作为后起之秀,则大大减少的运维的成本。
2、etcd是什么?
etcd主要用来作为共享的服务配置及服务发现,使用的是raft协议来保证在分布式系统下的数据一致性,而raft算法那么容易理解,对于每个过程也是很好处理的。
3、如何使用etcd集群?
etcd的集群搭建是相当容易的,在使用的时候,使用命令行或者接口都是可以的,而作为一种分布式的kv存储,和redis感觉很相同,都是使用key value的模式,不过在etcd中,使用的树形结构来组织,和linux的目录结构是一致的(具体见后文实例)。
1、集群架构
在搭建集群中,使用四台机器进行演示,etcd集群为3台机器,1台机器作为备用机器,进行模拟坏的机器。

2、 安装etcd
在centos7系统上自带有etcd,从而只要直接使用yum进行安装即可(在四台机器上均要进行安装)。
3、 开启防火墙
[root@centos ~]# firewall-cmd --add-port=2380/tcp --permanent;firewall-cmd --add-port=2379/tcp --permanent;systemctl restart firewalld
success
success
4、 启动etcd
在新建集群的时候,首先在一台机器上启动etcd服务(测试的时候,注意将ip地址进行修改即可):
[root@docker-ce /]# etcd --name docker-ce --data-dir /etcd --initial-advertise-peer-urls http://192.168.1.222:2380 --listen-peer-urls http://192.168.1.222:2380 --listen-client-urls http://192.168.1.222:2379,http://127.0.0.1:2379 --advertise-client-urls http://192.168.1.222:2379 --initial-cluster-token etcd-cluster-1 --initial-cluster docker2=http://192.168.1.33:2380,docker1=http://192.168.1.32:2380,docker-ce=http://192.168.1.222:2380 --initial-cluster-state new
[root@docker-ce ~]# etcdctl member list(查看节点成员)
client: etcd cluster is unavailable or misconfigured; error #0: client: endpoint http://127.0.0.1:2379 exceeded header timeout
; error #1: dial tcp 127.0.0.1:4001: getsockopt: connection refused
[root@docker-ce ~]# etcdctl cluster-health(检查集群是否健康)
cluster may be unhealthy: failed to list members
Error: client: etcd cluster is unavailable or misconfigured; error #0: dial tcp 127.0.0.1:4001: getsockopt: connection refused
; error #1: client: endpoint http://127.0.0.1:2379 exceeded header timeout
error #0: dial tcp 127.0.0.1:4001: getsockopt: connection refused
error #1: client: endpoint http://127.0.0.1:2379 exceeded header timeout
[root@docker-ce ~]# netstat -ntlp|grep etcd(查看etcd监听的端口,客户端使用的端口为2379,服务端使用的端口为2380)
tcp 0 0 192.168.1.222:2379 0.0.0.0:* LISTEN 115537/etcd
tcp 5 0 127.0.0.1:2379 0.0.0.0:* LISTEN 115537/etcd
tcp 0 0 192.168.1.222:2380 0.0.0.0:* LISTEN 115537/etcd
[root@docker-ce ~]# ps -ef|grep etcd(查看etcd进程)
root 115537 1347 24 20:29 pts/0 00:00:58 etcd --name docker-ce --data-dir /etcd --initial-advertise-peer-urls http://192.168.1.222:2380 --listen-peer-urls http://192.168.1.222:2380 --listen-client-urls http://192.168.1.222:2379,http://127.0.0.1:2379 --advertise-client-urls http://192.168.1.222:2379 --initial-cluster-token etcd-cluster-1 --initial-cluster docker2=http://192.168.1.33:2380,docker1=http://192.168.1.32:2380,docker-ce=http://192.168.1.222:2380 --initial-cluster-state new
启动日志中,出现报错信息,也就是无法连接其他机器的通信端口2380.
2018-02-08 20:33:34.566814 W | rafthttp: health check for peer c9bb018f3490f125 could not connect: dial tcp 192.168.1.33:2380: getsockopt: connection refused
2018-02-08 20:33:34.642930 W | rafthttp: health check for peer f83aa3ff91a96c2f could not connect: dial tcp 192.168.1.32:2380: getsockopt: connection refused
启动另外一台机器上的etcd进程:
[root@docker1 ~]# etcd --name docker1 --data-dir /etcd --initial-advertise-peer-urls http://192.168.1.32:2380 --listen-peer-urls http://192.168.1.32:2380 --listen-client-urls http://192.168.1.32:2379,http://127.0.0.1:2379 --advertise-client-urls http://192.168.1.32:2379 --initial-cluster-token etcd-cluster-1 --initial-cluster docker2=http://192.168.1.33:2380,docker1=http://192.168.1.32:2380,docker-ce=http://192.168.1.222:2380 --initial-cluster-state new
[root@docker-ce ~]# etcdctl member list(查看集群成员,发现已经有两个节点)
5d951def1d1ebd99: name=docker-ce peerURLs=http://192.168.1.222:2380 clientURLs=http://192.168.1.222:2379 isLeader=true
c9bb018f3490f125: name=docker2 peerURLs=http://192.168.1.33:2380 clientURLs= isLeader=false
f83aa3ff91a96c2f: name=docker1 peerURLs=http://192.168.1.32:2380 clientURLs=http://192.168.1.32:2379 isLeader=false
[root@docker-ce ~]# etcdctl cluster-health(etcd集群已经能够正常工作,已经完成了选举)
member 5d951def1d1ebd99 is healthy: got healthy result from http://192.168.1.222:2379
member c9bb018f3490f125 is unreachable: no available published client urls
member f83aa3ff91a96c2f is healthy: got healthy result from http://192.168.1.32:2379
cluster is healthy
启动第三个节点上的etcd进程:
[root@docker2 ~]# etcd --name docker2 --data-dir /etcd --initial-advertise-peer-urls http://192.168.1.33:2380 --listen-peer-urls http://192.168.1.33:2380 --listen-client-urls http://192.168.1.33:2379,http://127.0.0.1:2379 --advertise-client-urls http://192.168.1.33:2379 --initial-cluster-token etcd-cluster-1 --initial-cluster docker2=http://192.168.1.33:2380,docker1=http://192.168.1.32:2380,docker-ce=http://192.168.1.222:2380 --initial-cluster-state new
[root@docker-ce ~]# etcdctl member list(查看集群成员列表,在其中显示了成员名称,名称和id都是唯一的,并且显示了服务端各个节点之间通信的地址,并且显示这个成员的状态,有的为leader,有的为follower)
5d951def1d1ebd99: name=docker-ce peerURLs=http://192.168.1.222:2380 clientURLs=http://192.168.1.222:2379 isLeader=true
c9bb018f3490f125: name=docker2 peerURLs=http://192.168.1.33:2380 clientURLs=http://192.168.1.33:2379 isLeader=false
f83aa3ff91a96c2f: name=docker1 peerURLs=http://192.168.1.32:2380 clientURLs=http://192.168.1.32:2379 isLeader=false
[root@docker-ce ~]# etcdctl cluster-health(集群状态为健康)
member 5d951def1d1ebd99 is healthy: got healthy result from http://192.168.1.222:2379
member c9bb018f3490f125 is healthy: got healthy result from http://192.168.1.33:2379
member f83aa3ff91a96c2f is healthy: got healthy result from http://192.168.1.32:2379
cluster is healthy
启动参数说明如下:
--name:节点的名称,唯一标识这个节点;
--data-dir:存储数据的目录,当没有指定wal-dir的时候,日志文件也会存储在这个目录下,主要用来存储节点的信息和集群的信息,还有快照文件;
--initial-advertise-peer-urls:告知集群其他节点的这个成员的url信息,可以有多个;
--listen-peer-urls:监听其他节点的url,主要用来和其他的节点进行通信;
--listen-client-urls:监听客户端的url,主要用来接受客户端的信息;
--advertise-client-urls:对外的监听的客户端的url,用来接受客户端的信息,不过是public的;
--initial-cluster-tocken:集群启动的时候的tocken信息,相当于集群id;
--initial-cluster:集群启动时候的配置信息(也就是集群的所有member节点);
--initial-cluster-state:初始化的时候集群的状态(new或者existing)。
5、 为何要用奇数个节点
在组建集群的时候,我们总是可以看到使用奇数个节点,例如,3,5,7,9等节点的数量。
主要是在选主leader的时候,不会发生脑裂的情况。一般情况是如果有3个,那么可以容许一个挂掉;如果有五个,那么容许2个挂掉;也就是N/2+1个活着就行。
节点数量看起来越多越好,但是在通信的时候,首先是leader要发送很多信息给follower,从而导致网络可能有压力;另外就是写的时候,必须全部首先写到leader之中,然后从leader进行同步,这样会造成写的性能下降。
6、 测试
测试的时候,最简单的方式就是使用命令客户端,etcdctl来使用,如下:
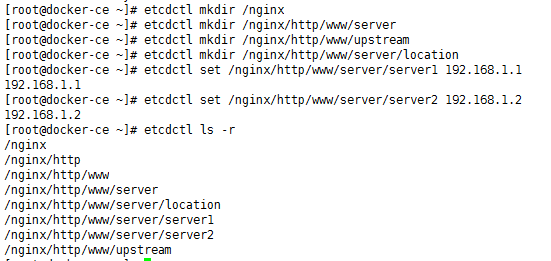
在这里mkdir主要是创建一个目录,树形结构,而set则是设置一个kv值,而get则是取出这个值,从而达到配置共享的目的,也实现了分布式系统中的强一致性。
1、 一台机器进程崩溃

直接关闭一台follower的进程模拟宕机,发现集群是健康的,依旧是可以工作的。
在恢复的时候,直接使用原来的启动程序启动即可,无须修改任何东西。

当一个leader的进程挂了的时候,集群在短时间内会完成选举,选举之后,正常工作,当进程恢复启动之后,原来的leader会向新的leader进行同步信息,从而达到一致性的目的。
2、 主机迁移
有的时候,物理机需要下线维修,从而需要将数据拷贝到其他的机器上,从而在这里使用第三台机器来进行迁移。
在这里进行恢复的时候,必须按照步骤进行恢复,首先停止需要停止的机器的etcd进程,然后将数据拷贝到新机器的数据目录中

更新集群中的信息,然后在新机器上启动etcd进程。

测试:

3、 扩容
当发现集群的能力跟不上的时候,那么就需要扩容。
首先进行注册新的节点:

然后进行启动etcd进程,但是需要注意的是,启动的时候需要三个值,也就是ETCD_NAME,ETCD_INITIAL_CLUSTER,ETCD_INITIAL_CLUSTER_STATE,表示新加入一个集群。
etcd --name docker22 --data-dir /etcd --initial-advertise-peer-urls http://192.168.1.33:2380 --listen-peer-urls http://192.168.1.33:2380 --listen-client-urls http://192.168.1.33:2379,http://127.0.0.1:2379 --advertise-client-urls http://192.168.1.33:2379 --initial-cluster-token etcd-cluster-1 --initial-cluster docker-ce=http://192.168.1.222:2380,docker22=http://192.168.1.33:2380,docker2=http://192.168.1.22:2379,docker1=http://192.168.1.32:2380 --initial-cluster-state existing
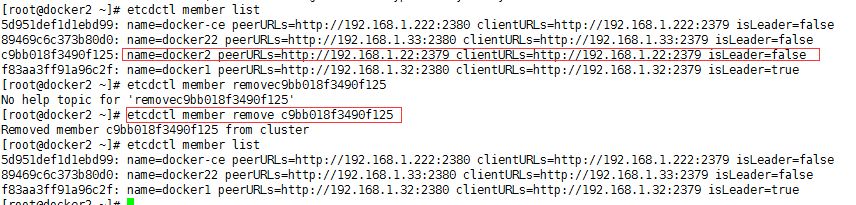
4、 缩容
当集群需要缩小规模的时候,主要直接移除节点,那么节点上etcd进程会被停止。
待续。。。。。















 3295
3295











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









