







1、Storm程序的并发机制
1.1、概念
Workers (JVMs): 在一个物理节点上可以运行一个或多个独立的JVM 进程。一个Topology可以包含一个或多个worker(并行的跑在不同的物理机上), 所以worker process就是执行一个topology的子集, 并且worker只能对应于一个topology
Executors (threads): 在一个worker JVM进程中运行着多个Java线程。一个executor线程可以执行一个或多个tasks。但一般默认每个executor只执行一个task。一个worker可以包含一个或多个executor, 每个component (spout或bolt)至少对应于一个executor, 所以可以说executor执行一个compenent的子集, 同时一个executor只能对应于一个component。
Tasks(bolt/spout instances): Task就是具体的处理逻辑对象,每一个Spout和Bolt会被当作很多task在整个集群里面执行。每一个task对应到一个线程,而stream grouping则是定义怎么从一堆task发射tuple到另外一堆task。你可以调用TopologyBuilder.setSpout和TopBuilder.setBolt来设置并行度 — 也就是有多少个task。
1.2、配置并行度
对于并发度的配置, 在storm里面可以在多个地方进行配置, 优先级为:
defaults.yaml < storm.yaml < topology-specific configuration
< internal component-specific configuration < external component-specific configuration worker processes的数目, 可以通过配置文件和代码中配置, worker就是执行进程, 所以考虑并发的效果, 数目至少应该大亍machines的数目
executor的数目, component的并发线程数,只能在代码中配置(通过setBolt和setSpout的参数), 例如, setBolt(“green-bolt”, new GreenBolt(), 2)
tasks的数目, 可以不配置, 默认和executor1:1, 也可以通过setNumTasks()配置
Topology的worker数通过config设置,即执行该topology的worker(java)进程数。它可以通过 storm rebalance 命令任意调整。
Config conf = newConfig();
conf.setNumWorkers(2); //用2个worker
topologyBuilder.setSpout("blue-spout", newBlueSpout(), 2); //设置2个并发度
topologyBuilder.setBolt("green-bolt", newGreenBolt(), 2).setNumTasks(4).shuffleGrouping("blue-spout"); //设置2个并发度,4个任务
topologyBuilder.setBolt("yellow-bolt", newYellowBolt(), 6).shuffleGrouping("green-bolt"); //设置6个并发度
StormSubmitter.submitTopology("mytopology", conf, topologyBuilder.createTopology());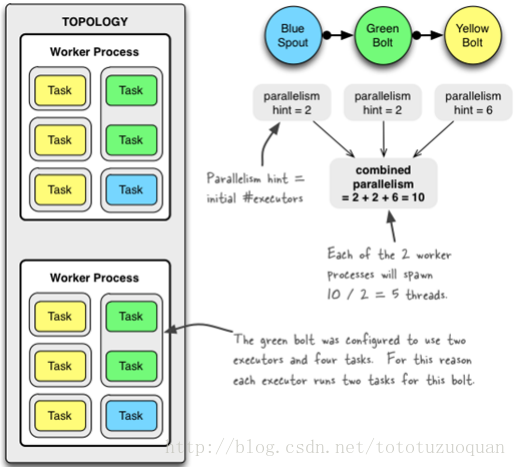
3个组件的并发度加起来是10,就是说拓扑一共有10个executor,一共有2个worker,每个worker产生10 / 2 = 5条线程。
绿色的bolt配置成2个executor和4个task。为此每个executor为这个bolt运行2个task。
动态的改变并行度
Storm支持在不 restart topology 的情况下, 动态的改变(增减) worker processes 的数目和 executors 的数目, 称为rebalancing. 通过Storm web UI,或者通过storm rebalance命令实现:
storm rebalance mytopology -n 5 -e blue-spout=3 -e yellow-bolt=10local or shuffle 分组
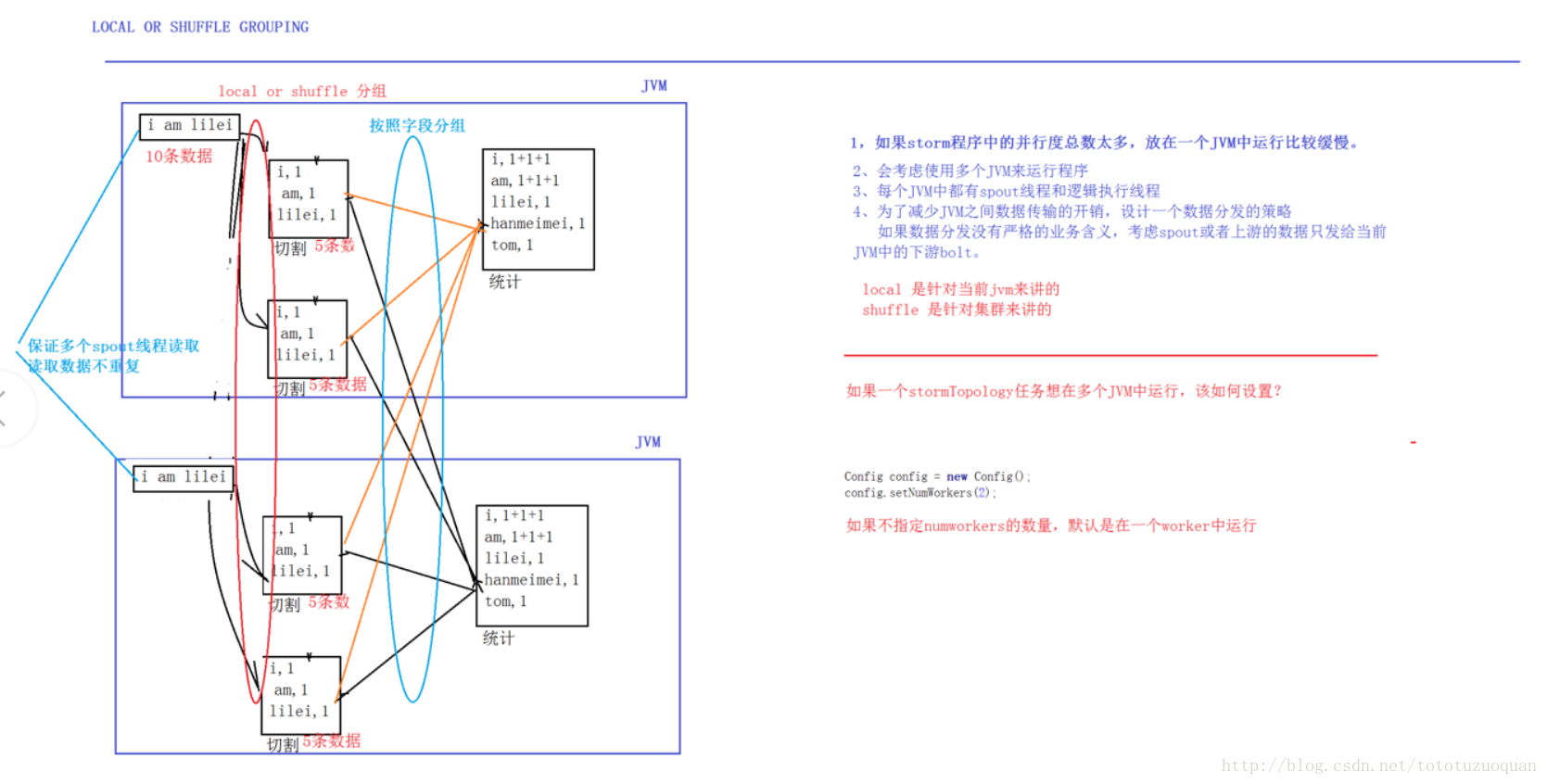
说明:
1.如果strom程序中的并行度总数太多,放在一个JVM中运行比较缓慢。
2.会考虑使用多个JVM来运行程序。
3.每个JVM中都有spout线程和逻辑执行线程。
4.为了减少JVM之间数据传输的开销,设计一个数据分发的策略
如果数据分发没有严格的业务含义,考虑spout或者上游的数据只发给当前JVM中的下游bolt.
local是针对当前JVM来讲的。
shuffle是针对集群来讲的。
如果一个stormTopology任务想在多个JVM中运行,如何设置?
Config config = new Config();
config.setNumWorkers(2);
如果不指定numworkers的数量,默认是在一个worker中运行。
分组的概念

说明:
Strom里面有7种类型的stream grouping
1.Shuffle Grouping:随机分组,随机派发stream里面的tuple,保证每个bolt接收到的tuple数目大致相同。
2.Fields Grouping:按字段分组,比如按userid来分组,具有同样userid的tuple会被分到相同的Bolts里的task,而不同的userId则会被分配到不同的bolts里的task.
3.All Grouping:广播发送,对于每一个tuple,所有的bolts都会收到。
4.Global Grouping:全局分组,这个tuple被分配到storm中的一个bolt的其中一个task。再具体一点就是分配给id值最低的那个task.
5.Non Grouping:不分组,这stream grouping个分组的意思是说stream不关心到底谁会收到它的tuple。目前这种分组和Shuffle grouping是一样的效果,有一点不同的是storm会把这个bolt放在这个bolt的订阅者同一个线程里面去执行。
6.Direct Grouping:直接分组,这是一种比较特别的分组方法,用这种分组意味着消息的发送者指定由消息接收者的哪个task处理这个消息。只有被声明Direct Stream的消息流可以声明这种分组方法。而且这种消息tuple必须使用emitDirect方法来发射。消息处理者可以通过TopologyContext来获取处理它的消息的task的id(OutputCollector.emit方法也会返回task的id)
7.Local or shuffle grouping:如果目标bolt有一个或者多个task在同一个工作进程中,tuple将会被随机发给这些tasks。否则,和普通的Shuffle Grouping行为一致。














 295
295











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









