




 本文详细介绍了如何在Ubuntu 16.04上设置Spark 2.0.1的分布式集群。包括创建用户、安装SSH以实现无密码登录、安装Java、配置环境变量、部署Hadoop 2.7、安装Scala以及最终安装和配置Spark。步骤涵盖从下载软件到启动集群,并提供了检查安装成功的途径。
本文详细介绍了如何在Ubuntu 16.04上设置Spark 2.0.1的分布式集群。包括创建用户、安装SSH以实现无密码登录、安装Java、配置环境变量、部署Hadoop 2.7、安装Scala以及最终安装和配置Spark。步骤涵盖从下载软件到启动集群,并提供了检查安装成功的途径。
电脑三台(局域网中):
| 名字 | IP |
|---|---|
| Master | 192.168.1.183 |
| Slave1 | 192.168.1.193 |
| Slave2 | 192.168.1.184 |
1 . 为每台机器配置一个名为spark用户,用户密码自己记住
2. 安装ssh(三台)
2.1, sudo apt-get install ssh
2.2,安装完成后,执行ssh-keygen -t rsa -P “”(一路回车即可)
2.3 ,转到.ssh文件中,执行cat id_rsa.pub >> authorized_keys,测试ssh Master看是否可以无密码登录
2.4,在Master下执行scp ~/.ssh/authorized_keys spark@Slave1:~/.ssh/来实现Master可以无密码登录Slave这些节点中。
3. 安装Java(Master)
3.1 下载java linux版本,在/home/spark下建立java文件,将文件解压到这tar -xvf jdk-8u111-linux-x64.tar.gz
3.2 配置环境变量 sudo gedit ~/.bashrc 在最下方写入
exportJAVA_HOME=/home/spark/java/jdk1.8.0_111
export JRE_HOME=${JAVA_HOME}/jre
exportCLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH3.3 java -version 测试是否成功
3.4 scp /home/spark/java spark@Slave1:~/java/将文件发給子节点,并照上面方法配java 环境。
4. 安装hadoop2.7(Master)
4.1 下载并解压到/home/spark/hadoop中
4.2 配置hadoop的环境变量
exportJAVA_HOME=/home/spark/java/jdk1.8.0_111
export JRE_HOME=${JAVA_HOME}/jre
exportCLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export HADOOP_HOME=/home/spark/hadoop/hadoop-2.7.3
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export PATH=${JAVA_HOME}/bin:${HADOOP_HOME}/bin:$PATH4.3 配置core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://Master:8020</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/spark/hadoop/hadoop-2.7.3/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
</configuration>4.4配置hdfs-site.xml(需要新建dfs/name和dfs/data两个文件。
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>Master:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/spark/hadoop/hadoop-2.7.3/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/spark/hadoop/hadoop-2.7.3/dfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>4.5 配置yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>Master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>Master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>Master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>Master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>Master:8088</value>
</property>
</configuration>4.6 配置mapred-site.xml.templet
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>执行 cp mapred-site.xml.templet mapred-site.xml
4.7 修改 slaves
删除localhost
添加Slave1和Slave2
4.8 执行scp /home/spark/hadoop spark@Slave1:~/ 主要将hadoop发给子节点
在Master 执行sudo cd $HADOOP_HOME
./bin/hadoop namenode -format
./sbin/start-all.sh
如果出错记得要学会看日志,在此hadoop集群就可以了
5. 安装scala 2.11
5.1 下载并解压到/home/spark/scala中
5.2 sudo gedit ~/.bashrc 配置环境变量
exportJAVA_HOME=/home/spark/java/jdk1.8.0_111
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export HADOOP_HOME=/home/spark/hadoop/hadoop-2.7.3
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export SCALA_HOME=/home/spark/scala/scala-2.11.6
export PATH=${JAVA_HOME}/bin:${HADOOP_HOME}/bin:${SCALA_HOME}/bin:$PATH执行 scala -version 可以检查
6. 安装spark 2.0.1
6.1下载并解压到/home/spark/spark中
6.2 配环境变量
export SPARK_MASTER_IP=Master
export SPARK_WORKER_MEMORY=1g
exportJAVA_HOME=/home/spark/java/jdk1.8.0_111
export JRE_HOME=${JAVA_HOME}/jre
exportCLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export HADOOP_HOME=/home/spark/hadoop/hadoop-2.7.3
export HADOOP_CONF_DIR=${HADOOP_HOME}/etc/hadoop
export SCALA_HOME=/home/spark/scala/scala-2.11.6
export SPARK_HOME=/home/spark/spark/spark-2.0.0-bin-hadoop2.7
export PATH=${JAVA_HOME}/bin:${HADOOP_HOME}/bin:${SCALA_HOME}/bin:${SPARK_HOME}/bin:$PAT**
6.3 修改spark-env.sh.templet
export JAVA_HOME=/home/spark/java/jdk1.8.0_111
export HADOOP_HOME=/home/spark/hadoop/hadoop-2.7.3
export SCALA_HOME=/home/spark/scala/scala-2.11.6
export SPARK_MASTER_IP=Master
export SPARK_WORKER_MEMORY=1g
export MASTER=spark://Master:7077执行cp spark-env.sh.templet hadoop-env.sh
6.4 修改 slaves
删除localhost
添加Slave1和Slave2
6.5 修改spark-defaults.conf.templet
spark.master spark://Master:7077
spark.executor.extraJavaOptions -XX:+PrintGCDetails -Dkey=value -Dnumbers="one two three"
spark.eventLog.enabled true
spark.eventLog.dir hdfs://Master:9000/filename
spark.yarn.historyServer.address hdfs://Master:18080
spark.history.fs.logDirectory hdfs://Master:9000/filename执行cp spark-defaults.conf.templet spark-defaults.conf
6.6 scp home/spark/spark spark@Slave1:~/ 将spark 发給子节点
6.7 (Master)执行 sudo cd $SPARK_HOME
./sbin/start-all
结果如下:Master
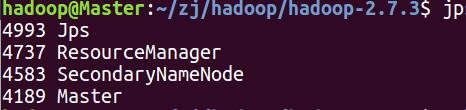
还有个namenode进程
Slave2中有
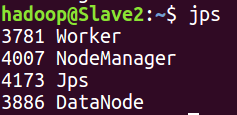
还可以登录http://master:507000 和http://master:8080查看,到此spark安装就成功了。共学习……。

















 3722
3722

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









