




今天的主要内容有:
1. Linux下使用定时器crontab
1、安装
yum -y install vixie-cron
yum -y install crontabs2、启停命令
service crond start //启动服务
service crond stop //关闭服务
service crond restart //重启服务
service crond reload //重新载入配置
service crond status //查看crontab服务状态3、查看所有定时器任务
crontab -l
这个定时器任务是每分钟用sh执行test.sh脚本
4、添加定时器任务
crontab -e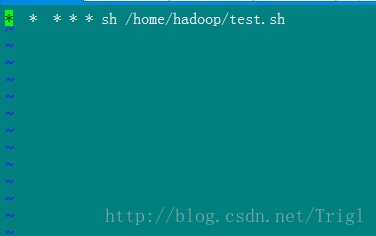
5、crontab的时间表达式
基本格式 :
* * * * * command
分 时 日 月 周 命令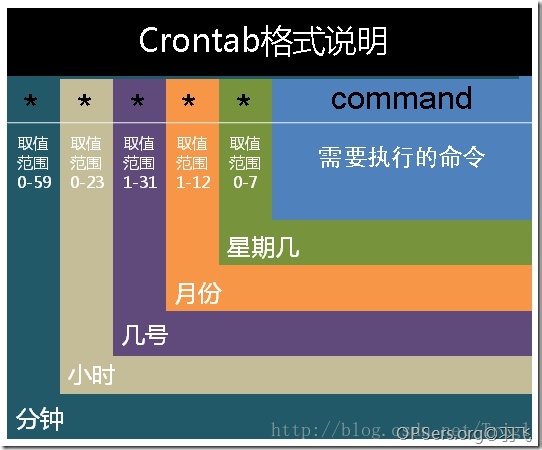
6、常用实例
// 每分钟执行一次
* * * * *
// 每隔一小时执行一次
00 * * * *
* */1 * * * (/表示频率)
// 每小时的15和45分各执行一次
15,45 * * *  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 755
755

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









