









一、storm是一个用于实时流式计算的分布式计算引擎,弥补了Hadoop在实时计算方面的不足(Hadoop在本质上是一个批处理系统)。
二、storm在实际应用场景中的位置一般如下:
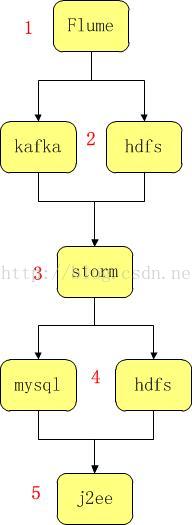
其中的编号1~5说明如下:
1、Flume用于收集日志信息;
2、结合数据传输功能可以把收集到的日志信息实时传输到kafka集群,或保存到Hadoop hdfs中保存。
这里之所以选择kafka集群是因为kafka集群具备缓冲功能,可以防止数据采集速度和数据处理速度不匹配导致数据丢失,这样做可以提高可靠性。
3、使用storm实时处理数据;
4、保存storm处理的结果数据,当数据量不是特别巨大时,可以使用MySQL存储;当数据量特别巨大时,可以选择hdfs存储。
5、用于实时展示处理结果。
三、storm的抽象运行方式:
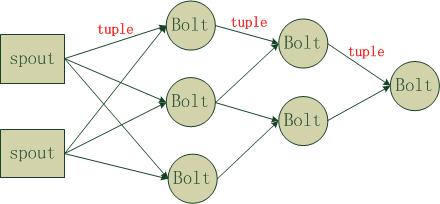
其中:
spout为数据流的源头;
tuple为流动中的数据承载单元;
Bolt为数据流处理的中间状态。
四、spout和Bolt如何形成程序运行?
storm中运行的程序称为Topology,Topology将spout和bolt组装在一起,完成实时计算的任务。具体操作是通过TopologyBuilder的setSpout方法和setBolt方法,例子如下:
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("spout-name", your-spout-program);
builder.setBolt("bolt-name-one", your-bolt-program-one, thread-number)
.fieldsGrouping("spout-name", new Fields("field-key-name-one"));
builder.setBolt("bolt-name-two", your-bolt-program-two).fieldsGrouping("bolt-name-one", new Fields("field-key-name-two"));
Config conf = new Config();
StormSubmitter.submitTopology("your-Topology-name", conf,builder.createTopology());五、如何决定数据流的流向:
(1)借助在TopologyBuilder的setSpout方法和setBolt方法的第一个参数中为Spout程序和Bolt程序取的名字,例如上面示例代码中的“spout-name”以及“bolt-name-one”,“bolt-name-two”。
补充:setBolt方法原型:
setBolt(String id, IBasicBolt bolt, Number parallelism_hint)
Define a new bolt in this topology.
setSpout方法原型:
setSpout(String id, IRichSpout spout, Number parallelism_hint)
Define a new spout in this topology with the specified parallelism.补充:fieldGrouping方法原型:
T fieldsGrouping(String componentId,
Fields fields)
The stream is partitioned by the fields specified in the grouping.
Parameters:
componentId -
fields -
Returns:六、数据流中的数据承载单元tuple结构是什么
官网文档如下:
The tuple is the main data structure in Storm. A tuple is a named list of values, where each value can be any type. Tuples are dynamically typed -- the types of the fields do not need to be declared. Tuples have helper methods like getInteger and getString to get field values without having to cast the result. Storm needs to know how to serialize all the values in a tuple. By default, Storm knows how to serialize the primitive types, strings, and byte arrays. If you want to use another type, you'll need to implement and register a serializer for that type. See http://github.com/nathanmarz/storm/wiki/Serializationfor more info.
通俗的讲,tuple就是一个值列表,其中的值类型可以是任何类型,默认类型有byte,integer,short,long,float,double,string,byte[]。
tuple数据结构如下:
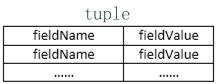
其中,fieldName是定义在declareOutputFields方法中的Fields对象,fieldValue值是在emit方法中发送的Values对象。
tuple都是通过spout和bolt发射(传送)的。
例如:
spout程序如下:
public class ParallelFileSpout extends BaseRichSpout{
@SuppressWarnings("rawtypes")
public void open(Map conf, TopologyContext context,
SpoutOutputCollector collector) {
}
/**
* called in SpoutTracker. called once, send a single tuple.
*/
public void nextTuple() {
//不断获取数据并发射
collector.emit(new Values("your-sent-fieldValue"));
}
/**
* define field. used for grouping by field.
*/
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("your-sent-fieldName"));
}
}
bolt程序如下:
public class DetectionBolt extends BaseBasicBolt {
public void prepare(Map stormConf, TopologyContext context) {
}
public void execute(Tuple input, BasicOutputCollector collector) {
//不断的处理数据后发射
collector.emit(new Values(“your-sent-fieldValue”));
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("your-sent-fieldName"));
}
}
七、spout如何发射无界的数据流,bolt如何处理接收到的数据tuple
(1)如在上一部分spout的示例代码,其中必含有nextTuple方法,在spout程序生命周期中,nextTuple方法一直运行,所以可以一直获取数据流中的数据并持续像bolt处理程序发射。
(2)如在上一部分bolt的示例代码,其中必含有execute方法,在bolt程序生命周期中,只要其收到tuple数据就会处理,根据需要会把处理后的数据继续发射出去。
八、如何保证所有发射的数据tuple都被正确处理
同一个tuple不管是处理成功还是失败,都由创建它的Spout发射并维护。
九、storm和Hadoop中各角色对比
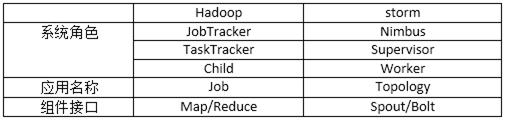
十、storm比Hadoop实时是因为Hadoop在把一批数据都处理完毕后才输出处理结果,而storm是处理一点数据就实时输出这些数据的处理结果。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









