







逻辑回归(Logistic Regression)是一个非线性回归模型,主要应用于0、1分类问题,也可看作单层的神经网络。
1. 原理推导
1.1 样本定义
每个样本计作(x, y),其中x为特征向量,y为标签0或1,x包含nx个特征:
x=⎡⎣⎢⎢⎢⎢x1x2⋮xnx⎤⎦⎥⎥⎥⎥(1)
训练集包含m个样本: {
(x(1),y(1)),(x(2),y(2)),⋯,(x(m),y(m))} ,上标(m)为第m个样本。
1.2 逻辑回归模型
问题:给定x,如何训练参数w和b,得到期望值 a=P(y=1|x) ?
为了保证期望值a在0 ~ 1之间,给定逻辑回归模型:
z=wTx+b(2)
a=σ(z)(3)
式中,w维度为(nx, 1),b为实数,z为线性模型,σ(z)为非线性的sigmoid函数。
1.3 sigmoid函数
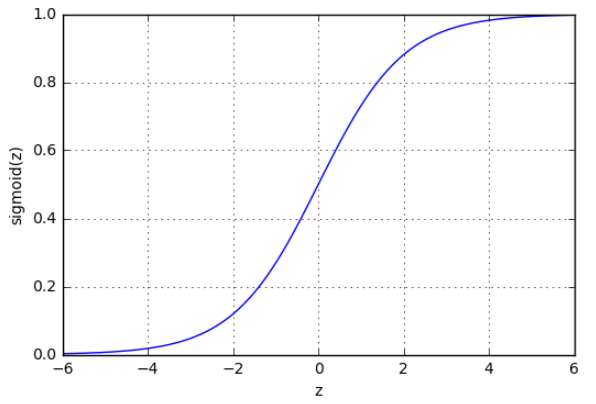
σ(z)=11+e−z(4)
当z → ∞时,σ(z) → 1;当z → -∞时,σ(z) → 0。函数值处于0 ~ 1之间,因此适合于0、1分类问题。曲线如下:
1.4 代价函数(Cost Function)
目标:给定训练集 {
(x(1),y(1)),(x(2),y(2)),⋯,(x(m),y(m))} ,预测值a(i) ≈ y(i)。
由于期望 a=P(y=1|x) ,可得:
{
P(y=1|x)=aP(y=0|x)=1−a(5)
使用概率论中极大似然估计(Maximum Likelihood Estimate,MLE)的方法来计算损失函数,可将概率写成:
P(y|x)=ay(1−a)1−y(6)
取对数似然函数:
log[P(y|x)]=yloga+(1−y)log(1−a)=−L(a,y)(7)
上式中,L(a, y)为损失函数(Loss Function),最大似然估计的目标是使log[P(y|x)]最大化,也就是损失函数L(a, y)最小化。则损失函数为:
L(a,y)=−[yloga+(1−y)log(1−a)](8)
当y = 1时, L(a,1)=−loga ,要使L尽可能小,则预测值a尽可能大,最大为1;
当y = 0时, L(a,0)=−log(1−a) ,要使L尽可能小,则预测值a尽可能小,最小为0。
对于m个训练样本,假设训练样本互相独立,则m个样本的联合概率可以写成:
Pmsamples=∏i=1mP(y(i)∣∣x(i))
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 996
996











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









