










javascript 作为前端开发语言,自古来对二进制数据的读取解析方面的支持都很薄弱,一般来说,解析二进制数据时,往往是将数据转换成字符串,然后运用各种字符串操作技巧来实现二进制数据的读取。
由于NodeJS 作为后台服务器开发平台,数理逻辑的设计需求超越javascript作为前端语言时界面UI的设计需求,因此,加强二进制数据的读取功能显得越发重要,幸运的是,NodeJS提供了Buffer类,该类提供的一系列接口使得对二进制数据的读取和解析变得异常方便,本文以解析ELF文件格式为例,向大家展示NodeJS强大的二进制数据读取功能。
本文要读取的elf文件链接如下:
http://pan.baidu.com/s/1gfCX8I3
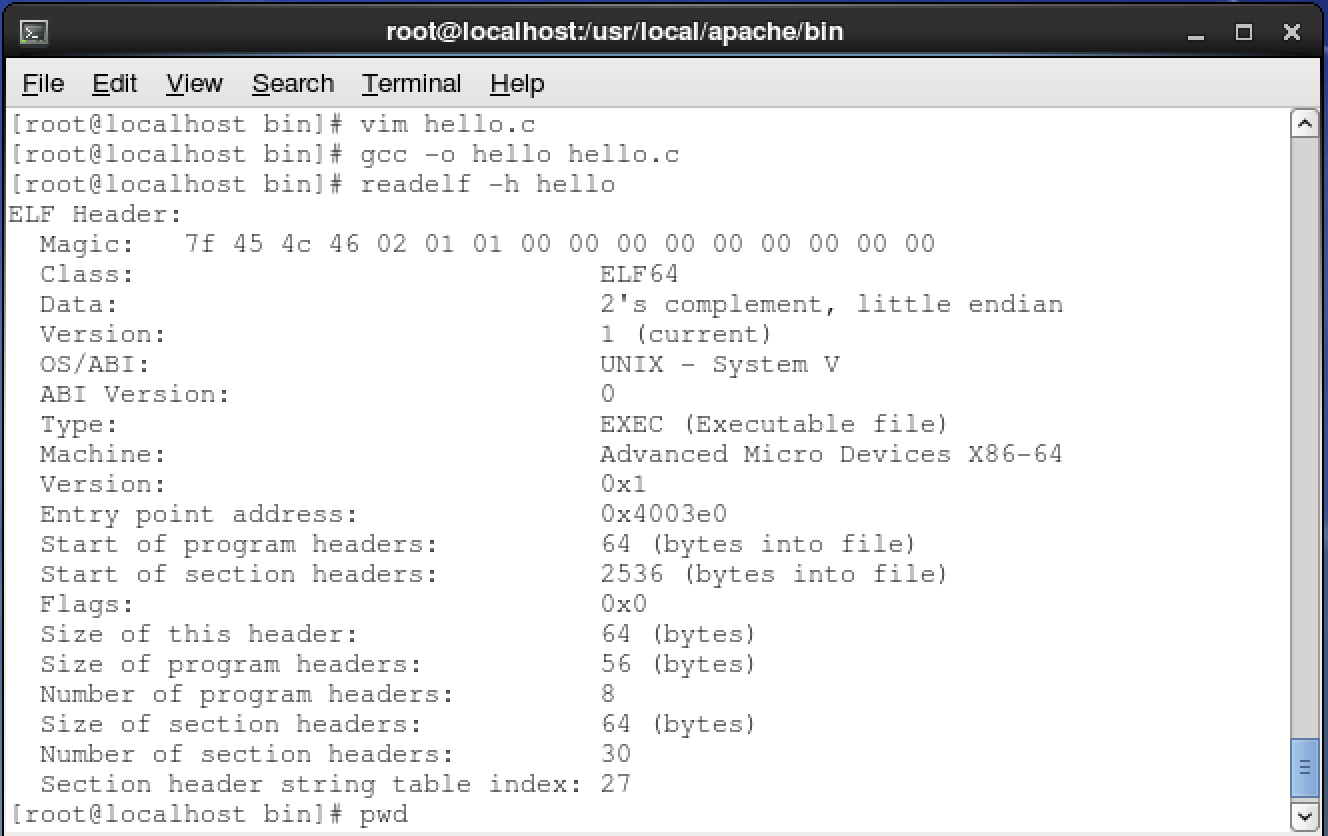
它是在Linux上编译的一个简单无比的Hello World C 语言程序,在Linux上,readelf 工具是解析elf文件的最佳工具,本文要使用NodeJS开发readelf 的 -h 命令行功能,即读取elf 文件的头部数据,Linux工具readelf -h 读取上述链接的elf文件后,显示信息如下:
接下来,我们看看如何通过NodeJS逐步实现该功能, 我们先看看ELF文件的头格式定义:
该定义的链接如下:
http://man7.org/linux/man-pages/man5/elf.5.html
#define EI_NIDENT 16
typedef struct {
unsigned char e_ident[EI_NIDENT];
uint16_t e_type;
uint16_t e_machine;
uint32_t e_version;
ElfN_Addr e_entry;
ElfN_Off e_phoff;
ElfN_Off e_shoff;
uint32_t e_flags;
uint16_t e_ehsize;
uint16_t e_phentsize;
uint16_t e_phnum;
uint16_t e_shentsize;
uint16_t e_shnum;
uint16_t e_shstrndx;
} ElfN_Ehdr;elf 二进制文件的头部开始有16字节,用于告诉操作系统如何解析该文件,我们先用代码把这16字节信息读取出来:
var fs = require('fs');
var fileBuf;
function readFile(fileName) {
fileBuf = fs.readFileSync(fileName);
}
if (process.argv.length >= 4) {
if (process.argv[2] === '-h') {
readFile(process.argv[3]);
console.log(fileBuf.slice(0,17));
}
}我们把上面的代码存储为readIdent.js, 将链接给的hello elf文件下载到与代码相同的目录,运行后结果如下:

大家可以发现,我们打印出来的数据跟前面readelf -h 后得到的magic部分是完全一样的。
我们解读下代码,首先我们用语句 fs = require(‘fs’); 将NodeJS的文件读取模块加载到程序,接下来调用fs模块的readFileSync以堵塞的方式将文件的内容读取,该函数返回的是一个Buffer类,在该类中,有一个字节缓冲区数组,专门用来存储要解析的二进制数据,fileBuf.slice(0,17)作用是将字节缓存区数组的头16个字节取出来,然后用console.log将这16字节的二进制数输出到控制台。这头16字节中,前8个字节都有特定的含义,接下来我们就要对着16字节的意义进行解读。
e_ident 数组的头四个字节,也就是elf文件的头四个字节是固定死的,叫魔术字,分别是:0x7f, 0x45, 0x4c, 0x46, 后三个字节对应的ASCII码字符是’E’,’L’,’F’, 我们把上面的代码稍加改动,把魔术字打印出来看看:
var fs = require('fs');
var fileBuf;
function readFile(fileName) {
fileBuf = fs.readFileSync(fileName);
}
if (process.argv.length >= 4) {
if (process.argv[2] === '-h') {
readFile(process.argv[3]);
var head = fileBuf.slice(0,17);
console.log(head);
console.log("magic num: ", head.toString('ascii', 0, 5));
}
}执行后结果如下:

fileBuf.slice(0, 17) 返回的也是一个Buffer类对象,这个Buffer类的字节缓冲区数组存储的是fileBuf字节缓冲区的头16字节数据,Buffer提供了一个接口函数toString, 可以对缓冲区中的二进制数据依据给定的格式进行解读,toString(‘ascii’, 0, 5) 表示把缓冲区的头4个字节当做ascii字符所组成的字符串,由于第一个字节0x7f在ascii码中对应的字符是不可打印的,因此console.log只输出了后三个字节对应的ascii字符,他们就是ELF.
e_ident 中的第五个字节表示可执行文件的二进制架构,称为EI_CLASS,如果该字节取值为0,那么表示该二进制文件是无效文件,如果是1,表示该文件可运行在32位的机器上,如果是2,表示可运行在64位的机器上。
第六个字节表示的是数据编码格式,称为EI_DATA, 取值0,表示编码格式未知,取值1表示little-endian,取值2表示big-endian,little-endian的意思是如果有4个单字节, 0x1,0x2,0x3,0x4 如果把他们当做一个32位数同时解析时,解析的数值结果是 0x04030201, 如果是big-endian,那么解析的结果是0x01020304.
第七个字节称为EI_VERSION, 用来表示当前ELF文件所对应的格式版本,取值0表示无效版本,取值1表示最新版本,ELF文件格式是进过长时间演化而来的,在发展过程中经历了不同的版本,不同版本,它的二进制格式是不同的,操作系统需要只当当前可执行文件对应的版本,才知道如何解析加载该文件。
第八字节称为EI_OSABI,用于表明可以执行该文件的操作系统类型,对应的值有:
ELFOSABI_NONE Same as ELFOSABI_SYSV
0 UNIX System V ABI
1 HP-UX ABI
2 NetBSD ABI
3 Linux ABI
4 Solaris ABI
5 IRIX ABI
6 FreeBSD ABI
7 TRU64 UNIX ABI
8 ARM architecture ABI
9 Stand-alone (embedded) ABI
取值0表示可以被UNIX系统加载执行,取值3表示可以被Linux加载执行。
第九字节称为EI_ABIVERSION, 一般取值为0.
从第九字节之后的字节都用于填充,没有实际意义,接下来我们给代码添加e_ident数组的解读功能:
var fs = require('fs');
var fileBuf;
var elfHeader = {};
var EI_NIDENT = 16;
var readOffset = 0;
var eiOSABI = ['UNIX System V ABI', 'UNIX System V ABI', 'HP-UX ABI', 'NetBSD ABI', 'Linux ABI', 'Solaris ABI',
'IRIX ABI', 'FreeBSD ABI', 'TRU64 UNIX ABI', 'ARM architecture ABI', 'Stand-alone (embedded) ABI'];
var fileVersion = ['invalid version', 'current version'];
function digestEIdent(eIdent) {
elfHeader['magic'] = eIdent.toString('ascii', 0, 4);
switch (eIdent[4]) {
case 0:
elfHeader['class'] = 'illegal file';
break;
case 1:
elfHeader['class'] = 'ELF32';
break;
case 2:
elfHeader['class'] = 'ELF64';
break;
}
elfHeader['data'] = 'illegal code format';
if (eIdent[5] === 1) {
elfHeader['data'] = 'little endian';
}
else if (eIdent[5] == 2) {
elfHeader['data'] = 'bigger endian';
}
elfHeader['version'] = eIdent[6];
elfHeader['osabi'] = eiOSABI[eIdent[7]];
elfHeader['abi version'] = eIdent[8];
}
function readFile(fileName) {
fileBuf = fs.readFileSync(fileName);
}
if (process.argv.length >= 4) {
if (process.argv[2] === '-h') {
readFile(process.argv[3]);
var eIdent = fileBuf.slice(0,17);
digestEIdent(eIdent);
console.log(elfHeader);
}
}digestEIdent函数依照上面解释的字节意义,将每个字节读取出来,并把字节对应的意义用字符串表示,然后把他们对应的信息填写到elfHeader对象中,最后把信息再输出到控制台:

大家可以看到,我们的解析跟readelf工具对e_ident数组解析的结果是一致的
接下来是e_type, 它是两字节的数据类型,用于表明当前文件类型,取值如下:
ET_NONE An unknown type.
ET_REL A relocatable file.
ET_EXEC An executable file.
ET_DYN A shared object.
ET_CORE A core file.
如果取值是ET_EXEC(2), 表明文件是可执行文件,如果取值是ET_DYN(3)表明文件是动态链接库,Buffer类提供了接口,专门用来读取两字节数据,它是
readUInt32LE, 该接口的输入参数是读取数据的位移,如果我们要读取e_type,由于e_type的位置偏移是第17字节,因此通过fileBuf.readUInt16LE(17)就可以把它的值读出来,同理,对应的接口 readUInt32LE可以读取4字节的数据。
接下来的两字节数据成为e_machine, 用来表明该可执行文件所对应的CPU类型,它的取值可参见以下链接:
https://refspecs.linuxbase.org/elf/gabi4+/ch4.eheader.html
e_machine在我们给定的文件中,取值为62,对应的含义为:
AMD x86-64 architecture
接下来的四字节数据叫e_version,它只有两个取值,0表示文件无效,1表示有效。Buffer类提供的4字节读取接口是readUInt32LE.
接下来的数据叫e_entry, 用来表示执行文件被系统加载如内存后所在的虚拟地址,当文件被加载如内存,系统会将寄存器EIP指向该地址,开始程序的运行,要注意的是该段数据的长度取决于操作系统的位数,还记得e_ident数组中的第5个字节EI_CLASS吧,如果该字节取值1,表明系统是32位,那么e_entry也是32位的,读取它可以直接使用readUInt32LE接口,EI_CLASS取值为2,那么系统是64位,那么e_entry长度就得是64位,八字节,由于Buffer类没有提供直接读取八字节的接口,因此该功能需要我们自己实现,实现的办法是分别读出两个4字节,然后将第二个4字节左移32位后跟第一个4字节连接起来,从而组成一个8字节数,代码实现如下:
function readUInt64LE(buf, readOffset) {
var lowerPart = buf.readUInt32LE(readOffset);
readOffset += 4;
var higherPart = buf.readUInt32LE(readOffset);
readOffset += 4;
return '0x' + ((higherPart << 32) | lowerPart).toString(16);
}接下来的数据叫程序头表偏移e_phoff(program header table offset), 操作系统通过读取程序头表获取程序的相关信息,以便决定如何加载可执行文件,它的长度和解读方法同上。
接下来的数据叫代码节头表e_shoff,跟上面的程序头表性质类似,也是系统用例加载文件所需要读取的信息,长度和解读方法跟上面一样
接下来的4字节e_flags,用来设置一些与cpu相关的标志位,当前始终设置为0.
接下来的2字节e_ehsize用来表示整个elf文件头的长度。
接下来2字节e_phentsize表示程序头的大小,程序头是一种数据结构,内容如下:
typedef struct {
uint32_t p_type;
Elf32_Off p_offset;
Elf32_Addr p_vaddr;
Elf32_Addr p_paddr;
uint32_t p_filesz;
uint32_t p_memsz;
uint32_t p_flags;
uint32_t p_align;
} Elf32_Phdr;
更多信息可参看链接:
http://man7.org/linux/man-pages/man5/elf.5.html
接下来2字节e_phnum表示程序头表中,包含多少个程序头数据结构。
接下来的2字节e_shentsize表示程序节表的长度
接下来2字节e_shnum表示程序节头表中有多少个元素。
最后的2字节e_shstrndx叫节头表字符索引
大家可能对一些数据段所表示的含义不是很清楚,这些含义是什么已经是加载器和连接器的内容,不属于本文考虑的范围,大家只要懂得如何通过 NodeJS读取二进制数据就可以了,最后我把整个读取代码实现在文件elfreader.js中:
var fs = require('fs');
var fileBuf;
var elfHeader = {};
var EI_NIDENT = 16;
var readOffset = 0;
var eiOSABI = ['UNIX System V ABI', 'UNIX System V ABI', 'HP-UX ABI', 'NetBSD ABI', 'Linux ABI', 'Solaris ABI',
'IRIX ABI', 'FreeBSD ABI', 'TRU64 UNIX ABI', 'ARM architecture ABI', 'Stand-alone (embedded) ABI'];
var eType = ['unknown type', 'relocatable file', 'an executable file', 'a shared file', 'a core file'];
var fileVersion = ['invalid version', 'current version'];
function digestEIdent(eIdent) {
elfHeader['magic'] = eIdent.toString('ascii', 0, 4);
switch (eIdent[4]) {
case 0:
elfHeader['class'] = 'illegal file';
break;
case 1:
elfHeader['class'] = 'ELF32';
break;
case 2:
elfHeader['class'] = 'ELF64';
break;
}
elfHeader['data'] = 'illegal code format';
if (eIdent[5] === 1) {
elfHeader['data'] = 'little endian';
}
else if (eIdent[5] == 2) {
elfHeader['data'] = 'bigger endian';
}
elfHeader['version'] = eIdent[6];
elfHeader['osabi'] = eiOSABI[eIdent[7]];
elfHeader['abi version'] = eIdent[8];
}
function readUInt64LE(buf, readOffset) {
var lowerPart = buf.readUInt32LE(readOffset);
readOffset += 4;
var higherPart = buf.readUInt32LE(readOffset);
readOffset += 4;
return '0x' + ((higherPart << 32) | lowerPart).toString(16);
}
function readElfHeader(buf) {
var eIdent = buf.slice(readOffset, readOffset + EI_NIDENT);
digestEIdent(eIdent);
readOffset += EI_NIDENT;
elfHeader['type'] = eType[buf.readUInt16LE(readOffset)];
readOffset += 2;
if (buf.readUInt16LE(readOffset) === 0x003e) {
elfHeader['machine'] = "AMD x86-64 architecture";
}
else {
elfHeader['machine'] = buf.readUInt16LE(readOffset);
}
readOffset += 2;
elfHeader['file version'] = fileVersion[buf.readUInt32LE(readOffset)];
readOffset += 4;
if (elfHeader['class'] === 'ELF64') {
elfHeader['entry point address'] = readUInt64LE(buf, readOffset);
readOffset += 8;
}
else {
elfHeader['entry point address'] = buf.readUInt32LE(readOffset);
readOffset += 4;
}
if (elfHeader['class'] === 'ELF64') {
elfHeader['program header offset from file'] = readUInt64LE(buf, readOffset);
readOffset += 8;
}
else {
elfHeader['program header offset from file'] = buf.readUInt32LE(readOffset);
readOffset += 4;
}
if (elfHeader['class'] === 'ELF64') {
elfHeader['section header offset from file'] = readUInt64LE(buf, readOffset);
readOffset += 8;
}
else {
elfHeader['section header offset from file'] = buf.readUInt32LE(readOffset);
readOffset += 4;
}
elfHeader['flags'] = buf.readUInt32LE(readOffset);
readOffset += 4;
elfHeader['size of this header'] = buf.readUInt16LE(readOffset);
readOffset += 2;
elfHeader['size of program headers'] = buf.readUInt16LE(readOffset);
readOffset += 2;
elfHeader['number of program header'] = buf.readUInt16LE(readOffset);
readOffset += 2;
elfHeader['size of section header'] = buf.readUInt16LE(readOffset);
readOffset += 2;
elfHeader['number of section header'] = buf.readUInt16LE(readOffset);
readOffset += 2;
elfHeader['section header string table index'] = buf.readUInt16LE(readOffset);
readOffset += 2;
console.log(elfHeader);
}
function readFile(fileName) {
fileBuf = fs.readFileSync(fileName);
}
if (process.argv.length >= 4) {
readFile(process.argv[3]);
if (process.argv[2] === '-h') {
readElfHeader(fileBuf);
}
}
程序执行后结果如下:
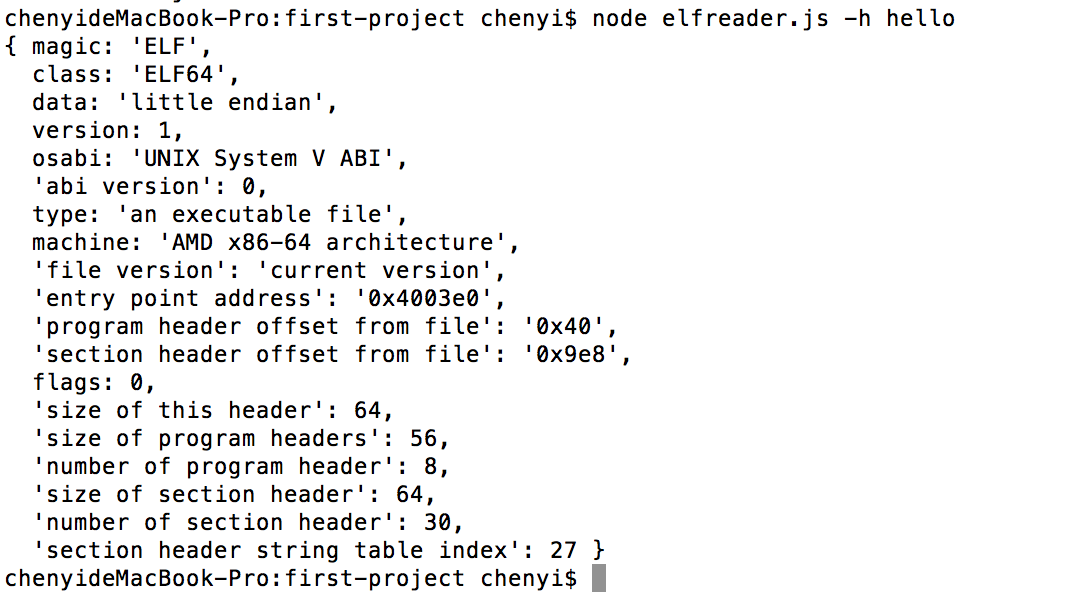
程序的运行结果跟开始使用的readelf 工具所显示的结果是一致的














 1200
1200











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









