










上一节我们实现了将if 条件判断跳转指令编译成了对于的java字节码,在介绍if 指令时,我们提到了goto指令,也就是直接跳转到jvm字节码的某个部分去执行。结合这两条指令,我们就可以实现把C语言的循环指令,例如for, while编译成对应的jvm字节码。基本原理很简单,我们先用if对应的指令判断循环条件是否成立,如果成立,那么执行循环体内的代码,然后利用goto跑到循环代码的起始处,再次判断循环条件是否成立。
完成本节代码后,我们可以把下面的C语言代码编译成java字节码,使之能在jvm上正常运行:
void main () {
int a[3];
int b[3];
int i;
int t;
for (i = 0; i < 3; i++) {
a[i] = i;
}
for (i = 0; i < 3; i++) {
t = (2 - i);
b[t] = a[i];
}
i = 0;
while(i<3) {
printf("value of b[%d] is %d", i, b[i]);
i++;
}
}
要正确的将上面C代码编译成java字节码,首先需要做的是让数组在定义的时候就直接编译成字节码,而不是当数组被赋值的时候才编译成字节码,也就是说编译器一旦读取到代码int a[3]; 就必须用jvm指令生成构造数组的字节码了,而不能等到读取a[i] = i 的时候才去生成字节码。
语句int a[3];对应的几条语法规则是:
Def -> Specifiers DecList Semi
DefList -> Def
DefList -> Def DefList
Statement -> DefListDef 表示的是变量定义,Specifiers 表示变量定义时的类型关键字,例如int, char等,DecList 表示由逗号隔开的变量名, Semi表示分号。例如语句:
int a, b , c, d;
其中int 对应Specifier, “a, b, c, d” 对应 DecList, 最后的‘;’对应Semi。整条语句对应的就是Def.由单条或多条变量定义语句集合而成的集体就可以定义为DefList, 例如:
int a;
int b;
int c;
上面三条语句,每一条都对应Def, 三条合在一起对应DefList, 而DefList又可以直接转化为Statement非终结符。
根据上面的分析,在构造执行树时,代码需要多增加几个执行节点所以在CodeTreeBuilder中增加以下代码:
public ICodeNode buildCodeTree(int production, String text) {
ICodeNode node = null;
Symbol symbol = null;
ICodeNode child = null;
switch (production) {
case CGrammarInitializer.Specifiers_DeclList_Semi_TO_Def:
/*
* 当解析到变量定义时,例如int a[3]; 走到这里
* 我们为变量定义增加一个执行节点,目的是在数组变量定义出现时,立马生成jvm指令,
* 而不要等到第一次读写数组时,才去为数组的创建生成jvm指令
*/
node = ICodeFactory.createICodeNode(CTokenType.DEF);
symbol = (Symbol)valueStack.get(valueStack.size() - 2); //获得数组变量的Symbol对象
node.setAttribute(ICodeKey.SYMBOL, symbol);
break;
case CGrammarInitializer.Def_To_DefList:
node = ICodeFactory.createICodeNode(CTokenType.DEF_LIST);
node.addChild(codeNodeStack.pop());
break;
case CGrammarInitializer.DefList_Def_TO_DefList:
node = ICodeFactory.createICodeNode(CTokenType.DEF_LIST);
node.addChild(codeNodeStack.pop());
node.addChild(codeNodeStack.pop());
break;
....
}有了节点后,我们也要添加相应的执行器,于是在项目中分别增加两个类,代码如下:
public class DefListExecutor extends BaseExecutor {
@Override
public Object Execute(ICodeNode root) {
int production = (int)root.getAttribute(ICodeKey.PRODUCTION);
switch (production) {
case CGrammarInitializer.Def_To_DefList:
executeChild(root,0);
break;
case CGrammarInitializer.DefList_Def_TO_DefList:
executeChild(root, 0);
executeChild(root, 1);
break;
}
return root;
}
}
public class DefExecutor extends BaseExecutor {
@Override
public Object Execute(ICodeNode root) {
int production = (int)root.getAttribute(ICodeKey.PRODUCTION);
switch (production) {
case CGrammarInitializer.Specifiers_DeclList_Semi_TO_Def:
Symbol symbol = (Symbol)root.getAttribute(ICodeKey.SYMBOL);
Declarator declarator = symbol.getDeclarator(Declarator.ARRAY);
if (declarator != null) {
if (symbol.getSpecifierByType(Specifier.STRUCTURE) == null) {
//如果是结构体数组,这里不做处理
ProgramGenerator.getInstance().createArray(symbol);
}
}
break;
}
return root;
}
}当编译器解析语句int a[3]; 时,编译器会先调用DefListExecutor.Execute, 由于DefExecutor是DefListExecutor下层的一个节点,因此在DefListExecutor.Execute中会调用DefExecutor.Execute,在里面编译器会判断,当前解析的变量定义语句是否是对数组元素的定义,如果是,那么调用ProgramGenerator.getInstance().createArray(symbol); 直接生成创建数组变量的jvm字节码,因此上面代码运行后,一旦编译器解析到语句int a[3];时,它会立马生成创建数组对象的jvm字节码:
sipush 3
newarray int
astore 2如果忘记了jvm如何创建数组对象,可以查看以前章节了解。
第二步要实现的是对数组元素进行赋值,以前讲解C语言数组元素的编译时,只针对很简单的情况进行处理,例如a[2] = 1; 也就是对数组元素赋值时,元素的下标是常量,赋值的也是常量,现在我们需要处理更复杂的形式,例如i = a[j];
a[j] = i; b[i] = a[j]; 第一种情况是把数组元素赋值给另一个变量,同时数组元素的下标也是变量,第三种情况是把一个数组元素赋值给另一个数组元素,并且两个数组元素的下标都是变量。
当前编译器在读取数组元素时,只支持下标是数字常量,同时一旦读取到数组元素例如a[2]时,他就会立马生成相应的数组元素读取字节码,但对于a[i] = j; 这种类型的语句时,是不必要对a[j]去产生读取字节码的,编译器只需要把变量j的值直接存储到数组中第i个元素就可以了,因此我们必须对数组元素的读取代码进行相关修改,在UnaryNodeExecutor.java中:
case CGrammarInitializer.Unary_LB_Expr_RB_TO_Unary:
child = root.getChildren().get(0);
symbol = (Symbol)child.getAttribute(ICodeKey.SYMBOL);
child = root.getChildren().get(1);
//change here
int index = (Integer)child.getAttribute(ICodeKey.VALUE);
Object idxObj = child.getAttribute(ICodeKey.SYMBOL);
try {
Declarator declarator = symbol.getDeclarator(Declarator.ARRAY);
if (declarator != null) {
Object val = declarator.getElement(index);
root.setAttribute(ICodeKey.VALUE, val);
ArrayValueSetter setter = null;
if (idxObj == null) {
setter = new ArrayValueSetter(symbol, index);
} else {
setter = new ArrayValueSetter(symbol, idxObj);
}
root.setAttribute(ICodeKey.SYMBOL, setter);
root.setAttribute(ICodeKey.TEXT, symbol.getName());
//change here
/*
//create array object on jvm
if (symbol.getSpecifierByType(Specifier.STRUCTURE) == null) {
//如果是结构体数组,这里不做处理,留给下一步处理
// ProgramGenerator.getInstance().createArray(symbol);
if (idxObj != null) {
ProgramGenerator.getInstance().readArrayElement(symbol, idxObj);
} else {
ProgramGenerator.getInstance().readArrayElement(symbol, index);
}
}
*/
}
....当编译器解读到a[i]时,上面的代码会被执行,我们把其中一部分代码注释掉了,通过前面章节的讲述,我们知道注释部分的代码是生成读取数组元素的字节码的,我们将其注释掉,目的就是为了让编译器不要一看到a[i]就立刻生成数组元素的读取字节码。同时语句:
int index = (Integer)child.getAttribute(ICodeKey.VALUE);
Object idxObj = child.getAttribute(ICodeKey.SYMBOL);目的是判断数组元素下标是数字常量还是变量,如果是常量例如a[2]那么index变量的值就是2,如果是变量a[i],那么idxObj就对应变量i的Symbol对象。ArrayValueSetter对象是用来负责对数组变量赋值的,因此它也做相应修改:
public class ArrayValueSetter implements IValueSetter{
private Symbol symbol;
private int index = 0;
private Object indexObj = null;
@Override
public void setValue(Object obj) {
Declarator declarator = symbol.getDeclarator(Declarator.ARRAY);
try {
declarator.addElement(index, obj);
if (indexObj == null) {
ProgramGenerator.getInstance().writeArrayElement(symbol, index, obj);
} else {
ProgramGenerator.getInstance().writeArrayElement(symbol, indexObj, obj);
}
System.out.println("Set Value of " + obj.toString() + " to Array of name " + symbol.getName() + " with index of " + index);
} catch (Exception e) {
// TODO Auto-generated catch block
System.err.println(e.getMessage());
e.printStackTrace();
System.exit(1);
}
}
public ArrayValueSetter(Symbol symbol, Object index) {
this.symbol = symbol;
if (index instanceof Integer) {
this.index = (int)index;
} else {
this.indexObj = index;
}
}
@Override
public Symbol getSymbol() {
// TODO Auto-generated method stub
return symbol;
}
//change here
public Object getIndex() {
if (indexObj != null) {
return indexObj;
}
return index;
}
}它判断数组元素的下标到底是常量还是变量,根据不同情况调研ProgramGenerator的不同接口来生成相应代码,我们继续看看相应代码的改动:
public void readArrayElement(Symbol symbol, Object index) {
Declarator declarator = symbol.getDeclarator(Declarator.ARRAY);
if (declarator == null) {
return;
}
int idx = getLocalVariableIndex(symbol);
//change here
this.emit(Instruction.ALOAD, ""+idx);
if (index instanceof Integer) {
this.emit(Instruction.SIPUSH, ""+index);
} else if (index instanceof Symbol) {
int i = this.getLocalVariableIndex((Symbol)index);
this.emit(Instruction.ILOAD, ""+i);
}
this.emit(Instruction.IALOAD);
}
public void writeArrayElement(Symbol symbol, Object index, Object value) {
Declarator declarator = symbol.getDeclarator(Declarator.ARRAY);
if (declarator == null) {
return;
}
int idx = getLocalVariableIndex(symbol);
if (symbol.hasType(Specifier.INT)) {
this.emit(Instruction.ALOAD, ""+idx);
if (index instanceof Integer) {
this.emit(Instruction.SIPUSH, ""+index);
} else {
int i = this.getLocalVariableIndex((Symbol)index);
this.emit(Instruction.ILOAD, ""+i);
}
}
/*
* 如果是数组元素直接相互赋值,例如b[i] = a[j]
* 那么必须为a[j]读取生成相应的字节码
*/
if (value instanceof ArrayValueSetter) {
ArrayValueSetter setter = (ArrayValueSetter)value;
Object idxObj = setter.getIndex();
Symbol arraySym = setter.getSymbol();
if (idxObj instanceof Integer) {
int i = (int)idxObj;
this.readArrayElement(arraySym, i);
} else {
this.readArrayElement(arraySym, idxObj);
}
}
if (value instanceof Integer) {
int val = (int)value;
this.emit(Instruction.SIPUSH, ""+val);
} else if (value instanceof Symbol) {
ProgramGenerator generator = ProgramGenerator.getInstance();
int i = generator.getLocalVariableIndex((Symbol)value);
generator.emit(Instruction.ILOAD, "" + i);
}
this.emit(Instruction.IASTORE);
}readArrayElement负责为数组元素的读取生成字节码,而writeArrayElement负责为数组元素的读入生成字节码,它们跟以前唯一的不同在于对数组元素下标的判断,原来只处理下标是数字常量时的情况,现在代码判断如果下标是变量的话,它会使用iload指令把下标变量加载到堆栈上,然后根据下标变量的值去读取或写入数组元素。上面代码完成后,对于语句a[i] = 2; 假设数组变量a在处于具备变量队列第0个位置,变量i处于具备变量队列第1个位置,那么该语句生成jvm字节码的情况如下:
aload 0 ;把数组变量a加载到堆栈
iload 1 ;把下标变量i加载到堆栈
sipush 2 ;把常量2加载到堆栈
iastore ;把常量2存储到a[i]在writeArrayElement中还处理了数组元素相互赋值的情况,也就是b[j] = a[i]这种情况。该函数在解析该赋值语句时,会先把b[j]加载到堆栈上,然后把a[i]读入堆栈,最后再通过iastore指令把a[i]的值存入b[j], 假设数组变量b处于局部变量队列第2位,变量j处于局部变量队列第3位,那么b[i]=a[i]被编译成java字节码时情况如下:
aload 2 ;把b对象加载到堆栈上
iload 3 ;把变量j加载到堆栈上
aload 0 ;把a对象加载到堆栈上
iload 1 ;把变量i加载到堆栈上
iaload ;把a[i]的值加载到堆栈上
iastore ;把a[i]的值存储到b[j]接着我们看看如何处理i = a[j]; 也就是把数组第j个元素的值赋予给变量i的情况。当编译器执行该语句时,Symbol.setValue会被调用,Symbol对应变量i,setValue传入的值就是在UnaryNodeExecutor中生成的ArrayValueSetter对象,我们看相应代码:
public void setValue(Object obj) {
....
if (obj instanceof ArrayValueSetter) {
/*
* 处理 i = a[2] 这种用数组元素赋值的情形,此时要把数组元素的读取生成jvm字节码
*/
ArrayValueSetter setter = (ArrayValueSetter)obj;
Symbol symbol = setter.getSymbol();
Object index = setter.getIndex();
if (symbol.getSpecifierByType(Specifier.STRUCTURE) == null) {
//如果是结构体数组,这里不做处理,留给下一步处理
if (index instanceof Symbol) {
ProgramGenerator.getInstance().readArrayElement(symbol, index);
int i = (int)((Symbol)index).getValue();
try {
this.value = symbol.getDeclarator(Declarator.ARRAY).getElement(i);
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
} else {
int i = (int)index;
try {
this.value = symbol.getDeclarator(Declarator.ARRAY).getElement(i);
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
ProgramGenerator.getInstance().readArrayElement(symbol, i);
}
}
}
....
}当用数组元素对变量赋值时,上面if条件判断中的代码会被执行。它先生成数组元素读取的jvm指令,把数组元素加载到堆栈上,接着再把堆栈上的数值元素值存储到变量所在的局部变量队列上,对于语句 i = a[j], 假设变量i在局部变量队列第1处,数组对象a在局部变量队列第0处,变量j在局部变量队列的第2处,那么该语句被编译成的jvm指令为:
aload 0 ;将变量a加载到堆栈上
iload 2 ;将变量j加载到堆栈上
iaload ;将a[j]的值加载到堆栈上
istore 1 ;把a[j]的值赋值给变量i接下来我们看看如何编译for, while等循环语句.以下是一段带有for指令的C语言程序,我们看看编译器是如何把它编译成jvm字节码的:
for (i = 0; i < 3; i++) {
a[i] = i;
}上面代码编译后得到结果如下:
sipush 0
istore 3 ; i = 0
loop0:
iload 3
sipush 3
if_icmpge branch0 ;判断 i < 3
aload 2 ;加载数组变量a
iload 3 ;加载元素下标i
iload 3 ;加载用于赋值给数组元素的变量i
iastore ;把变量i的值存入到a[i]
iload 3 ;加载变量i
sipush 1 ;把常量1压入堆栈
iadd ;实现i++
istore 3 ;把i+1后的值存入变量i
goto loop0 ;跳转到循环开头
branch0:当编译器读取到指令for时,会进入到StatemenentExecutor中,我们看看生成上面字节码的代码实现:
public Object Execute(ICodeNode root) {
int production = (int)root.getAttribute(ICodeKey.PRODUCTION);
ICodeNode node;
switch (production) {
case CGrammarInitializer.LocalDefs_TO_Statement:
executeChild(root, 0);
break;
case CGrammarInitializer.FOR_OptExpr_Test_EndOptExpr_Statement_TO_Statement:
//execute OptExpr
executeChild(root, 0);
if (BaseExecutor.isCompileMode) {
generator.emitLoopBranch();
String branch = generator.getCurrentBranch();
isLoopContinute(root, LoopType.FOR);
generator.emitComparingCommand();
executeChild(root, 3);
executeChild(root, 2);
String loop = generator.getLoopBranch();
generator.emitString(Instruction.GOTO + " " + loop);
generator.emitString("\n" + branch + ":\n");
generator.increaseLoopCount();
generator.increaseBranch();
}
while(BaseExecutor.isCompileMode == false && isLoopContinute(root, LoopType.FOR)) {
//execute statment in for body
executeChild(root, 3);
//execute EndOptExpr
executeChild(root, 2);
}
break;
....
}executeChild(root, 0);用来实现for循环的变量初始化,也就是for(i=0;i<3;i++)中的i=0这条赋值语句的字节码,generator.emitLoopBranch();用来生成字节码的入口地址,也就是上面字节码中的”loop0:”,isLoopContinute(root, LoopType.FOR);用来生成循环判断条件,也就是i<3;这条语句的字节码,generator.emitComparingCommand();用来生成”if_icmpge branch0”这条分支跳转语句,executeChild(root, 3); executeChild(root, 2); 用来将for循环体内的代码编译成字节码。
String loop = generator.getLoopBranch();
generator.emitString(Instruction.GOTO + " " + loop);这两条语句的作用是生成”goto loop0” 这条指令。
generator.emitString("\n" + branch + ":\n");上面代码的作用用于生成字节码中最后的”branch0:”这条地址指令。当我们要把for指令编译成字节码时,原来的模拟执行功能就不能运行,要不然会破坏代码生成的正确性。
同理,while循环的编译也在StatementExecutor中实现,相关代码如下:
case CGrammarInitializer.While_LP_Test_Rp_TO_Statement:
//change here
if (BaseExecutor.isCompileMode) {
generator.emitLoopBranch();
String branch = generator.getCurrentBranch();
/*
* 先判断循环条件
*/
executeChild(root, 0);
generator.emitComparingCommand();
executeChild(root, 1);
String loop = generator.getLoopBranch();
generator.emitString(Instruction.GOTO + " " + loop);
generator.emitString("\n" + branch + ":\n");
generator.increaseLoopCount();
generator.increaseBranch();
}
while (BaseExecutor.isCompileMode == false && isLoopContinute(root, LoopType.WHILE)) {
executeChild(root, 1);
}
break;其实现原理跟for指令的代码生成原理差不多,因此就不过多解释了。更多细节和代码调试讲解,请参看视频用java开发C语言编译器。
上面的代码全部实现后,能够把给定的C语言全部编译成如下字节码:
.class public CSourceToJava
.super java/lang/Object
.method public static main([Ljava/lang/String;)V
sipush 3
newarray int
astore 2
sipush 3
newarray int
astore 1
sipush 0
istore 3
loop0:
iload 3
sipush 3
if_icmpge branch0
aload 2
iload 3
iload 3
iastore
iload 3
sipush 1
iadd
istore 3
goto loop0
branch0:
sipush 0
istore 3
loop1:
iload 3
sipush 3
if_icmpge branch1
sipush 2
iload 3
isub
istore 0
aload 1
iload 0
aload 2
iload 3
iaload
iastore
iload 3
sipush 1
iadd
istore 3
goto loop1
branch1:
sipush 0
istore 3
loop2:
iload 3
sipush 3
if_icmpge branch2
aload 1
iload 3
iaload
istore 4
aload 1
iload 3
iaload
istore 5
getstatic java/lang/System/out Ljava/io/PrintStream;
ldc "value of b["
invokevirtual java/io/PrintStream/print(Ljava/lang/String;)V
getstatic java/lang/System/out Ljava/io/PrintStream;
iload 5
invokevirtual java/io/PrintStream/print(I)V
getstatic java/lang/System/out Ljava/io/PrintStream;
ldc "] is "
invokevirtual java/io/PrintStream/print(Ljava/lang/String;)V
getstatic java/lang/System/out Ljava/io/PrintStream;
iload 4
invokevirtual java/io/PrintStream/print(I)V
getstatic java/lang/System/out Ljava/io/PrintStream;
ldc "
"
invokevirtual java/io/PrintStream/print(Ljava/lang/String;)V
iload 3
sipush 1
iadd
istore 3
goto loop2
branch2:
return
.end method
.end class
上面的字节码进一步编译并用java虚拟机执行后,情况如下:
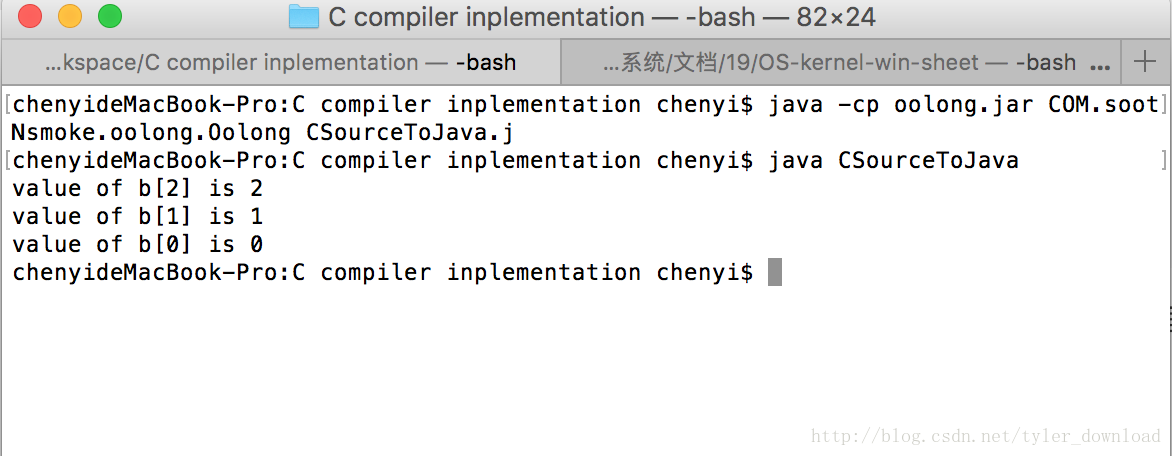
从运行结果可以看出,在虚拟机上运行的字节码确实与原来C语言的目的一样,把数组b中的内容赋值并打印出来了。有了循环指令的编译实现后,我们就可以完成最终章,把实现快速排序的C语言程序全部编译成java字节码,当完成这个内容后,我们整个历时将近两年的java开发编译器课程就将画上完美的句号。
关于本节更详实的视频讲解,请参看视频用java开发C语言编译器
更多技术信息,包括操作系统,编译器,面试算法,机器学习,人工智能,请关照我的公众号:














 336
336











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









