







JStorm 是一个分布式实时计算引擎。
JStorm 是一个类似Hadoop MapReduce的系统, 用户按照指定的接口实现一个任务,然后将这个任务递交给JStorm系统,JStorm将这个任务跑起来,并且按7 * 24小时运行起来,一旦中间一个Worker 发生意外故障, 调度器立即分配一个新的Worker替换这个失效的Worker。
因此,从应用的角度,JStorm应用是一种遵守某种编程规范的分布式应用。从系统角度, JStorm是一套类似MapReduce的调度系统。 从数据的角度,JStorm是一套基于流水线的消息处理机制。
实时计算现在是大数据领域中最火爆的一个方向,因为人们对数据的要求越来越高,实时性要求也越来越快,传统的Hadoop MapReduce,逐渐满足不了需求,因此在这个领域需求不断。
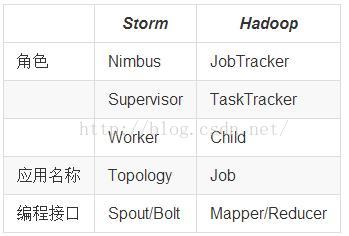
Storm组件和Hadoop组件对比
下面说说我自己对Jstorm的理解,做大数据的同伴对Storm肯定不会陌生,但为啥又出了个JStorm呢,个人理解就是Storm是别人家的,也存在很多的问题,无法满足阿里的自定义需求,于是阿里人就根据自己的需求采用java重写了Storm,并且做了大量的优化和改进,使得稳定性和性能都变得更加出色。(此处应该有鲜花和掌声!!!)
官网上也比较了Storm和Hadoop的组件,但比较的是老版的Hadoop,与新版加入YARN的Hadoop相比,Nimbus相当于ResourceManager,负责任务的调度,Supervisor相当于NodeManager,负责具体的计算,而在Supervisor上运行的worker进程相当于在NodeManager上运行的YarnChild进程,Topology相当于Mapreduce里的job,两者的一个关键的区别是:一个Mapreduce job最终会结束,而一个topology永远会运行(除非你手动kill掉)。
今天在提交topology是遇到了一个问题,所以我又提交了一次,但抛出了如下的异常:
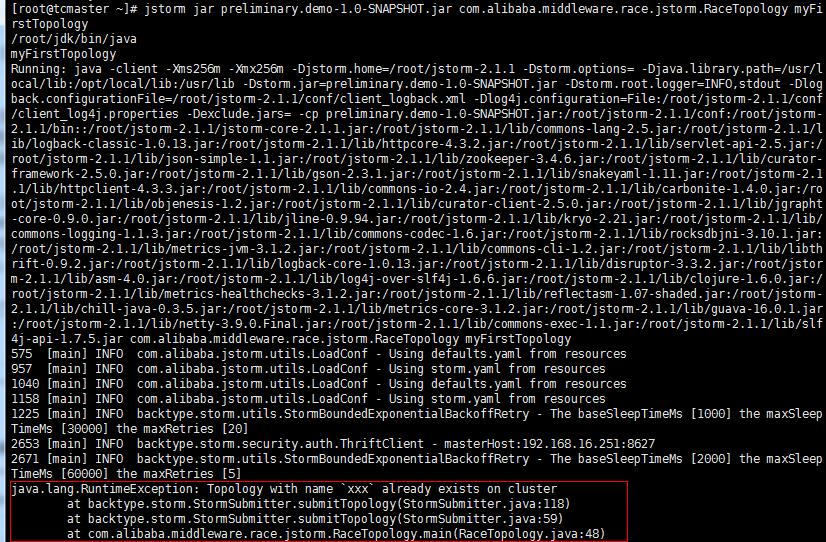
说明在集群众已经存在了同名的topology,导致提交失败。这里需要杀死正在运行的作业。可在终端命令行使用storm kill $topologyName方式杀死运行中的作业。
以此为契机,决定研究下Topology的提交机制。














 3935
3935











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









