







松本行弘 是 Ruby语言的作者, 我没有学习Ruby语言, 只是特别崇拜他!
类是对象的模板,相当于对象的雏形。在具有类功能的面向对象编程语言5中,对象都是由作为雏形的类来生成的,对象的性质也是由类来决定的。通过类可以把同一类的对象管理起来。
在有些编程语言中,类并不是必需的。相对于基于类的面向对象语言来说,那些类不是必需的面向对象语言称为
基于原型的语言。有代表性的基于原型的语言有 Self。Ajax 背后的 JavaScript 也是基于原型的语言。
DRY(Don't Repeat Yourself)原则就是彻底避免重复。这一原则对提高程序开发的效率和可靠性非常有效。
子类对象拥有父类所有属性,可以当做父类对象来处理,这种状态称为
LSP(Liscov Substitution Principle)。
实现的共享可以通过多个对象的组合(composition)和委托(delegate)来做到。
组合是把多个对象合成一个对象来处理。委托是把对一个对象的方法调用委派给别的对象。
动态类型的
优点:
- 动态类型编程语言的最大优点是源代码变得很简洁。
我们在编写程序的时候就不用考虑数据类型这些无关本质的部分了,而是可以集中于程序处理的本质部分,编写简洁程序的话,也可以提高生产力。
表达动态类型灵活性的概念是
Duck Typing。(走起路来像鸭子,叫起来也像鸭子,那么它就是鸭子)。
- 动态类型编程语言的另外一个特点是灵活性。
动态类型语言的程序不用指定变量的数据类型。
动态类型编程语言的
最大缺点是不执行就检测不出错误。
元编程
meta
在 Ruby 和其他一些面向对象编程语言中,
类的类称为元类,支撑
别的对象的类对象称为元对象。
元编程是
对程序进行编程的意思。
元编程的
反射(reflection)功能,在编程语言中它是指在程序执行时取出程序的信息或者改变程序信息。
在数据库领域,元编程也很有用。
设计模式
为什么需要
Singleton 模式呢?
比如作为其他对象的雏形而存在的对象(用于 Prototype 模式),以及系统全体只存在唯一一个的对象等,都要用到 Singleton 模式。
为什么需要
Proxy 模式呢?
假设有个生成代价非常大的对象。如果在还不知道是否真正需要该对象的时候就事先生成它的话,可能会带来很大的浪费。但话虽这么说,不生成对象的话什么事也做不了。这时候代理对象就有用武之地了。
比如字处理软件,它利用 Proxy 对象来处理嵌入图像,把嵌入图像的生成处理延迟到需要表示的瞬间才来进行。
Iterator(迭代器)模式提供按顺序访问集合对象中各元素的方法。即使不知道对象的内部构造,也可以按顺序访问其中的每个元素。
Iterator 模式是为集合对象另外准备用来控制循环处理的对象,就像 C++或 Java 一样。我们称这个循环控制对象为 Iterator,也称为游标。
雏形这个词对应的英语是
Prototype。像这样的不用类,而是用原型模式和复制方法的编程语言称为原型模式的编程语言。实际上,Prototype 模式不单是一种设计模式,也许称为一种编程范例才更为合适。
Template Method 模式是:“在父类的一个方法中定义算法的框架,其中几个步骤的具体内容则留给子类来实现。使用 Template Method 模式,可以在不改变算法构造的前提下,在子类中定义算法的一些步骤。”
Observer(观察者)模式是当某个对象的状态发生变化时,依存于该状态的全部对象都自动得到通知,而且为了让它们都得到更新,定义了对象间一对多的依存关系。
Strategy(策略)模式是这样解释的:“定义算法的集合,将各算法封装,使它们能够交换。利用 Strategy 模式,算法和利用这些算法的客户程序可以分别独立进行修改而不互相影响。”
Strategy 模式,就是将容易变化的处理归纳为独立的对象,然后使它们能够互相交换。
开放类和猴子补丁
猴子补丁(monkey patch)的解释是,
在动态语言中,不改变源代码而对功能进行追加和变更。
本来的含义是替换已有的方法(打补丁),现在灵活使用开放类,变更和追加方法全部称为猴子补丁。
开放类是指定义了之后也能任意追加内容的类。(不是修改原来的代码文件)
猴子补丁的目的
使用开放类,不改变原先的代码,替换方法(相当于打补丁)被称为猴子补丁。使用此技术可以完成以下功能。
- 功能追加
- 功能变更
- 修正程序错误
- 钩子
- 缓存(cache)
======================================================
C#使用
部分类和
扩展方法来实现开放类和猴子补丁的功能。
部分类是指可以在多个场所进行分散定义的类。将类的定义分散在多个场所,从而实现了相当于开放类的功能。不过,和开放类相比较,
C#有以下固有的限制:
- 所有的部分类必须加上 partial 这样的专用语(不能在事后对任意的类进行扩展);
- 部分类之间不允许有矛盾(类不能够被覆盖)。
可以说,在开放类实现的各种功能中,部分类实现了可以把类定义分散开来这一特殊功能。
而扩展方法是指允许和调用普通方法一样调用的静态方法(参见图 6-20)。带 this 关键词的 static 方法就好像类中的方法一样被调用。
不过,扩展方法不能给已有的方法加钩子,或是进行替换,因为狭义的猴子补丁不能使用扩展方法。这也是仅仅实现了开放类一部分特有的性质。
======================================================
前景可期的并行编程技术,Actor
线程编程容易变得复杂化,不但因为同步和竞争容易引起问题,而且一旦发生问题,症状会因时机不同而变化,以致于很难处理。
并行编程,要求有更高的抽象度和对人类而言更简单的编程模型。Curl Hewitt 提倡的
“Actor Model”(参与者模式)或许会成为这个问题的答案。
何谓Actor
还是来看 Actor 是什么吧。所谓 Actor,是(仅)通过消息(message)进行通信的实体。
单从这个定义来看,好像与面向对象语言的对象也没什么区别,但其实还是有的。
向对象发送消息(方法调用),调用开始后,会一直等到返回结果,是一种同步方式。而
向 Actor 发送消息,仅仅是发送消息而不等返回结果,是一种异步方式。
作为并行处理的机制,大家都知道线程。多个控制流同时运行的线程,非常简单和容易实现,如果协调和同步方面不需要花费很大成本的话,就能够得到很高的性能。
另一方面,Actor 基本上仅仅通过消息进行信息交换。因为不能直接共享同一个值,信息传达上就要多花些代价。
但是,为了避免线程间资源竞争,需要动用锁或者队列等各种方法来保护对资源的访问。
所谓
资源竞争,是指多个线程同时访问同一资源(变量、设备等),由于时机不同,执行结果变得不确定,或者程序状态变得不完整。
Actor 有一个大的优点是安全,但更大的优点是“易懂”。Actor 根据消息进行处理,必要的话,会向其他 Actor 传递消息,或者向源 Actor 返回消息。
这与现实世界中人与人之间的相处没有大的差别。现实世界中,别人在想什么你不知道,想要求什么时,需要通过某种手段传达“消息”。
另外,通过消息接受某种要求的人,与提出要求的人独立开展工作。工作完成之后,发送“完成”的消息返回给提出要求的人。对于我们而言,这种方法非常自然,整体处理流程也容易把握。Actor 原意是演员,正如这个字面意思,Actor(演员)与其他 Actor(演员)通过台词(消息)对白,完成他的角色,将剧情(程序)进行下去。
简单总结一下,理论上要达到最高性能,一般认为线程更优秀。但如果不注意使用线程的话,会出现与时机相关的很麻烦的问题。在计算机性能日渐提高的今天,与理论上最高性能的可能性相比,由 Actor 实现的安全性和易懂性更引人注目。
===========================================================
我关心的不是 Erlang 应用的Actor,不是Ruby应用的Actor , 也不是Scale基于JVM的Actor(Akka )。 而是.Net 中的Actor使用:
- Orleans https://github.com/dotnet/orleans 是微软推出的类似Scala Akka的Actor模型。
- Akka的.Net 版本 http://getakka.net/
===========================================================
在这本书中 不止一处提到了
YAML 这个语言。 Unity中序列化的实现方式。
活用记号和缩进的 YAML,比 JSON更简洁。考虑一下是否采用易读、易编辑的数据格式 YAML 吧,应该不错的。但正如其名,YAML 不是标记语言
内存管理与垃圾收集
垃圾收集算法基本上是如下 4 类,还有几种变形。
- 引用计数方式。
- 标记和扫除方式。
- 标记和紧缩方式。
- 复制方式。
垃圾收集的基本算法大致可以归结为以上 4 种,并在此基础上有各种变形。
此外,还有把基本算法组合起来的几种技术,这里介绍其中几个具有代表性的技术。
- 分代垃圾收集
- 保守垃圾收集
- 增量垃圾收集
- 并行垃圾收集
- 位图标志
引用计数方式
引用计数方式在垃圾收集算法中具有最简单最容易实现的特征。与下面要介绍的标记和扫除方式并列,都是在早期(1960 年)发明的。
以下是它的基本原理。
首先,各对象知道自己被从几个地方引用着(被引用数、引用计数器)。然后,在引用增减的同时也相应地改变被引用数。引用计数器变成 0 的对象,也就明确地表明它不再被其他对象所引用,可以释放它所占用的内存区域(参见图 14-18)。
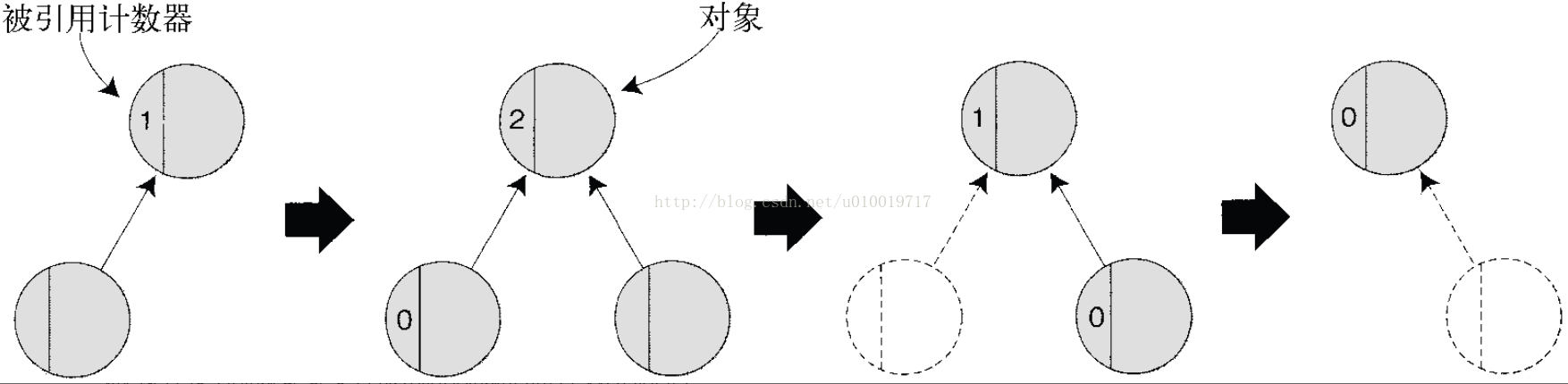
图 14-18 引用计数方式的原理,各对象内藏有被引用计数器,计数器变成 0 的对象将被释放
分析一个对象将来是否还会被用到,理解程序的意图来执行垃圾收集是不可能的事情。但是,如果一个对象不再被其他对象所引用,今后就确实不再会被用到。垃圾收集算法的基本功能就是找出这些不再被引用的对象。
引用计数方式的最大优点就是容易实现。这种方式得到广泛的使用,(包括我在内的)前几年的 C++程序员几乎都曾经实现过类似的引用计数器方式。
进一步讲,它最大的好处在于当引用数变成 0 的同时对象也就随之释放。在其他的垃圾收集方式中,当引用数变成 0 之后,对象什么时候被释放,都还是一个未知数,而引用计数器方式可以同时进行释放处理。暂停时间短也是它的优点。
另一方面,它有 3 个缺点。最大的缺点是它不能释放有循环引用关系的对象群。图 14-19 中的对象 a、b、c 不再被外面其他对象所引用,但因为它们自己互相引用,引用计数器不会变成 0,这样的对象就永远不会被释放。
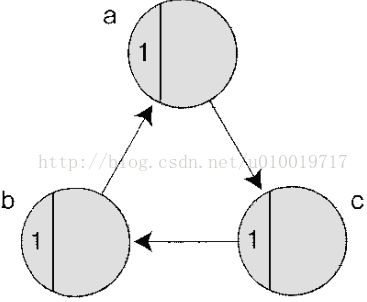
图 14-19 引用计数器方式无法处理的对象示例,因为有循环引用,引用计数器不会变为 0,会带来内存泄漏
引用计数器方式也有其与生俱来的缺点。因为在引用增减的时候有必要同时正确维护引用计数器的增减,忘了这一点就会带来悬挂指针或内存泄漏问题。在语言处理系统本身管理引用计数器的场合,还不太容易出问题,而程序员自己管理引用计数器的做法,没想到竟成为程序错误的温床。
最后 1 个缺点是,引用计数器的管理与并行处理不相容。如果多个进程同时增减一个引用计数器的话,就会发生引用计数器的值不一致的现象(从而成为内存故障的原因)。为避免这一问题,需要在操作引用计数器的时候进行排他处理,但在频繁发生引用操作的同时进行排他处理的话,会带来巨大的(时间)开销。
总之,这种原理简单实现也简单的引用计数器方式,缺点很多,最近已经不怎么用了。
现在,采用引用计数器方式的主要语言处理系统有 Perl 和 Python。为了回避循环引用问题,它们都组合了其他垃圾收集方式。这些语言基本上以引用计数器方式来进行垃圾收集,只有在极个别的情况下,才通过别的垃圾收集算法来处理引用计数器不能回收的对象。
14.3.6 标记和扫除方式
标记和扫除方式是和引用计数器方式同样古老的垃圾收集算法,相关论文都同样发表于 1960 年。
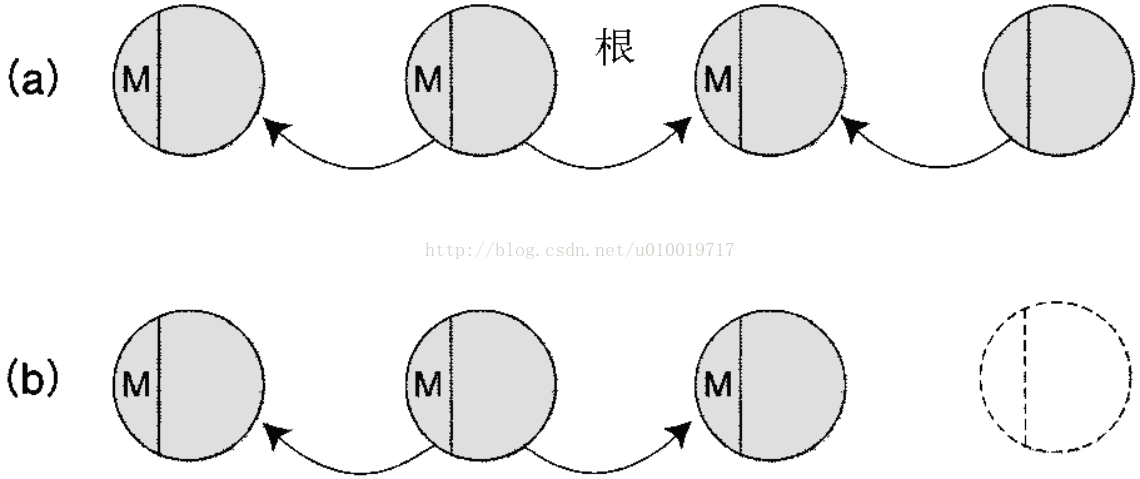
图 14-20 标记和扫除方式的原理。(a)从根开始按顺序给所有被引用的对象加上标记(M);(b)没有标记的对象被释放
标记和扫除方式从有可能成为对象引用元的变数(根)开始,给被引用的对象加上标记,表明它“活着”。这种方式然后再给标记对象所引用的对象,还有其再引用的对象,也都递归地加上引用标记(参见图 14-20a)。
这样从根开始不管是直接还是间接,只要把所有引用的对象都加上标记的话,那没有标记的对象就是没有被引用的,也就是“已经死了”。
然后,在所有的对象中找出没有标记的对象,把它们作为垃圾扫除出去(参见图 14-20b)。
这种标记和扫除方式虽然很古老,但确实非常优秀,现在也还被多种处理系统所采用。
但它也有缺点。当对象数目较多的时候,性能容易恶化。在标记的时候(标记阶段)要访问生存着的所有对象,在回收成为垃圾的对象时(扫除阶段),按顺序访问所有的对象,找出其中“已经死了”的对象。在寻找垃圾和扫除的过程中,基本上不能进行其他处理,垃圾收集时间长的话,会影响到本来的处理工作。
采用标记和扫除方式的语言有很多。我最熟悉的 Ruby 就是个代表性的例子。除了当对象数目多的时候有时会有问题外,大都执行得很好。
14.3.7 标记和紧缩方式
标记和紧缩方式是标记和扫除方式的变形。标记处理是一样的,后阶段有所不同。
标记和扫除方式按顺序检查所有的对象来进行扫除,标记和紧缩方式移动生存中的对象位置来腾出空间(参见图 14-21)。
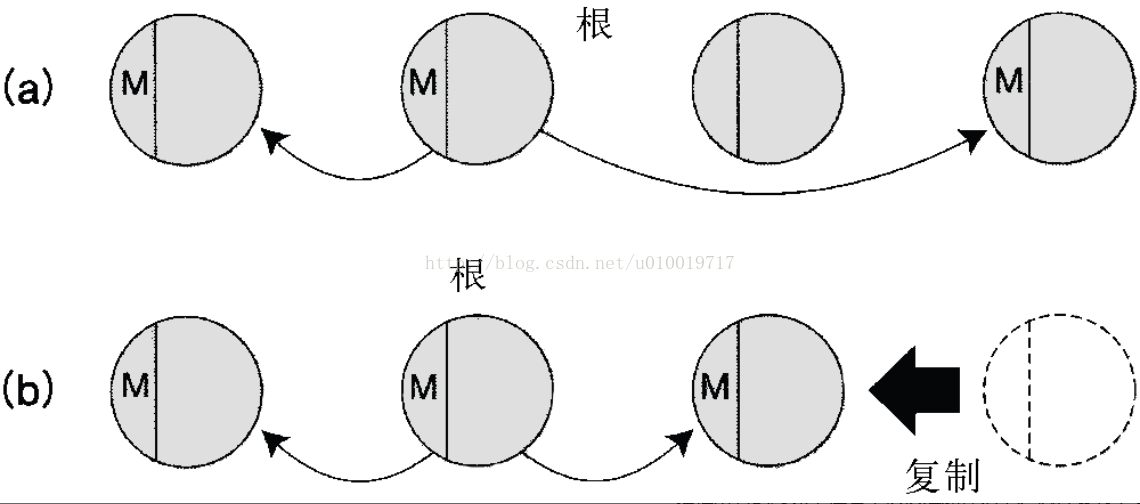
图 14-21 标记和紧缩方式的原理。(a)对象的顺序虽然有所不同,标记处理与图 14-20 是一样的;(b)移动生存中的对象,腾出空间
标记和紧缩方式最大的特征,也是它的优越之处,是把空间集中起来(紧缩)。紧缩的结果是把没有释放而活下来的对象都集中到了一个地方。这样,内存访问就集中到一个局部区域,这可以提高缓存功能的效率。对象的分配也只是把指针移动一下就完成了,降低了对象分配的开销,这也是它的好处。
这种方式的缺点是,把生存着的对象全部复制的紧缩开销,容易比标记和扫除方式中执行扫除的开销还要大。还因为对象被移动位置了,不能应用下文讲述的保守垃圾收集,这也是它的一个缺点。
一部分 Lisp 处理系统采用的是标记和紧缩方式,Java 处理系统(作为多个垃圾收集算法中的一个)也实现有标记和紧缩方式。
14.3.8 复制方式
像标记和扫除方式、标记和紧缩方式这样“标记之后释放死了的对象”的算法,标记时间与活着的对象数成比例,扫除(或者紧缩)时间与总对象数成比例。因此,在分配有非常多的对象,其中几乎所有对象都要被释放的场合,扫除的开销会变高,在性能方面很不利。与标记时间一样,要是能够有一种算法,只需要与生存着的对象成比例的开销就可以回收内存区域的话,岂不是很好吗?
基于这种想法的算法是复制方式。复制方式与标记和扫除方式一样,从根开始扫描所有的对象,但它不仅仅是加标记,还执行复制(参见图 14-22)。
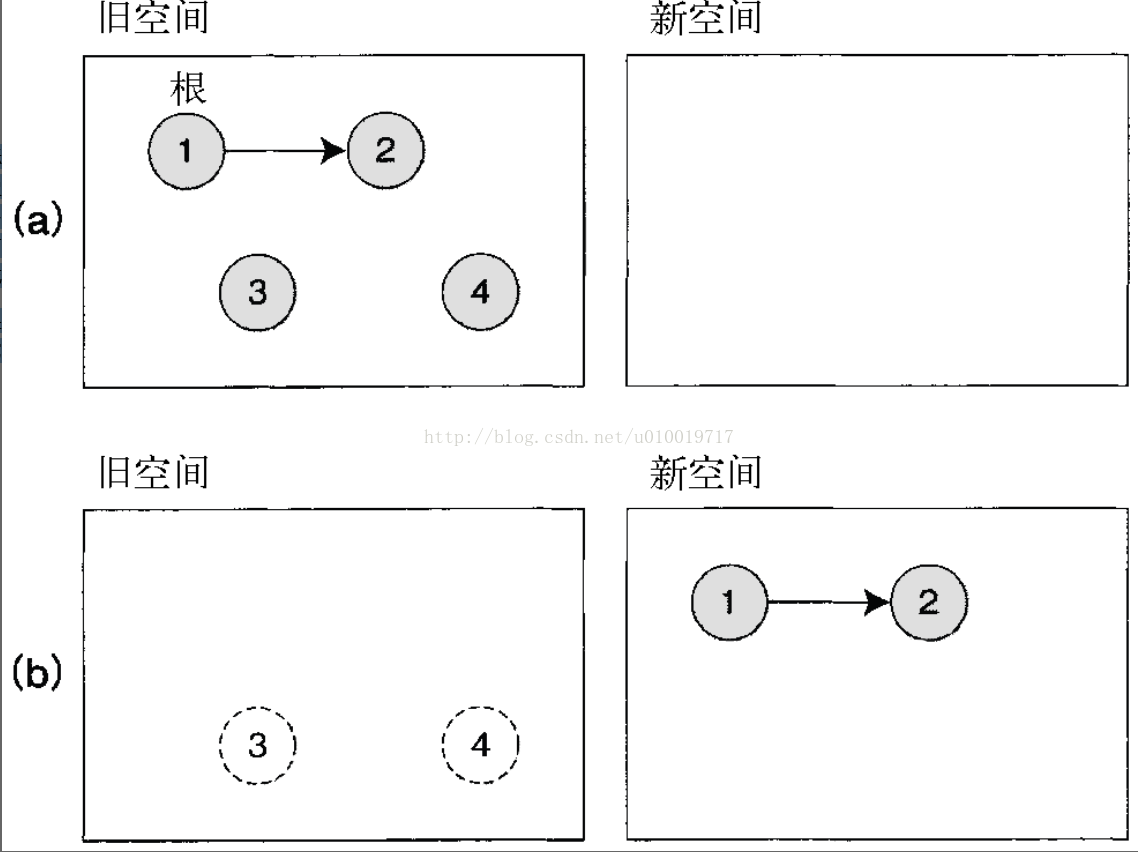
图 14-22 复制方式的原理。(a)在旧空间里分配对象;(b)旧空间填满的时候,从根开始
复制方式把内存空间分成旧空间和新空间两大块,总是在旧空间中分配对象。旧空间爆满的时候,从根开始扫描对象,把对象复制到新空间。这时,复制后的引用也要随之更新。
递归地执行从旧空间到新空间的复制,结束的时候就会把所有活着的对象都移动到新空递归地执行从旧空间到新空间的复制,结束的时候就会把所有活着的对象都移动到新空间。不再被引用的对象都遗留在旧空间,旧空间就可以整个地弃之不用,也就避免了扫除的开销。从这之后再把新空间作为这次的旧空间来继续同样的处理。
复制方式最大的优点是,垃圾收集开销只与活着的对象数成比列。与标记和紧缩方式一样,对象的分配开销低也是它的优点。
它还有“局部性”的优点。复制方式按顺序把引用的对象复制到新空间,关系近的对象会被分配在相近的内存空间上,这称为局部性。
我们知道,关系近的对象同时被访问的可能性也高。计算机上因为有缓存,内存空间相接近的访问有可能具有较好的性能,局部性高的程序具有提高性能的优势。
另一方面,复制方式也有缺点。复制方式要复制所有活着的对象,几乎具有与标记和紧缩方式同样的缺点。
一部分 Lisp 处理系统采用单纯的复制方式。还有,很多 Java 虚拟机把复制方式与其他方式组合起来,提供下文所述的分代垃圾收集。
14.3.9 多种多样的垃圾收集算法
垃圾收集的基本算法大致可以归结为以上 4 种,并在此基础上有各种变形。
此外,还有把基本算法组合起来的几种技术,这里介绍其中几个具有代表性的技术。
- 分代垃圾收集
- 保守垃圾收集
- 增量垃圾收集
- 并行垃圾收集
- 位图标志
这些技术的组合也是有可能的。
14.3.10 分代垃圾收集
首先来讲解垃圾收集技术中最有名最重要的分代垃圾收集(generational GC)。
分代垃圾收集的基本思想是利用程序和对象的性质。一般的程序都有这样一个性质,几乎所有的对象都在比较短的时间里变成垃圾,存活时间超过一定程度的对象总是拥有更长的寿命。
寿命长的对象更容易活下来,寿命短的对象会在更短的时间内变成垃圾,因为这一性质,就可以重点对分配之后还没有怎么经过时间的“年轻的”对象进行扫描,这样的话不用扫描全部对象就可能高效率地回收垃圾。
具体来说,分代垃圾收集把对象的内存空间分成两个,分别是容纳年轻对象的“新代”用的区域和容纳长寿对象的“旧代”用的区域。有的实现按 3 代以上进行划分,这里为了简单说明,只考虑两代的情况。
如果前面关于对象寿命的假设成立的话,仅仅扫描容纳年轻对象的新代空间,就可能以非常高的比例大量回收成为垃圾的对象,这种只扫描新代区域的回收称为轻垃圾收集。
但是,单纯地只对新代区域扫描,释放的算法是不能达到良好效果的,因为存在有旧代区域对新代区域的引用。
如果只扫描新代区域的话,就没有检查旧代区域对新代区域的引用,只被旧代区域引用的年轻对象就可能被误判为“已经死掉了”。这就会带来内存问题。
分代垃圾收集解决这一问题的办法是,监视对象的更新,在旧代区域引用新代区域发生的同时,就把这一引用的记录例程以及对象的更新场所全都记录下来,这个检查例程叫作写屏障(write barrier)。记录旧代区域对新代区域的引用称为记录集(remembered set)。
旧代区域中对象一般具有寿命比较长的倾向,但绝不是说它“总也不死”。随着程序的执行,旧代区域中也会积聚起垃圾。旧代区域中垃圾不回收的话,也会发生内存泄漏,所以需要不时地扫描包括旧代区域在内的所有区域,进行全面的垃圾收集。以所有区域为对象的垃圾收集称为全垃圾收集或重垃圾收集。
以上说明的分代垃圾收集的原理如图 14-23 所示。
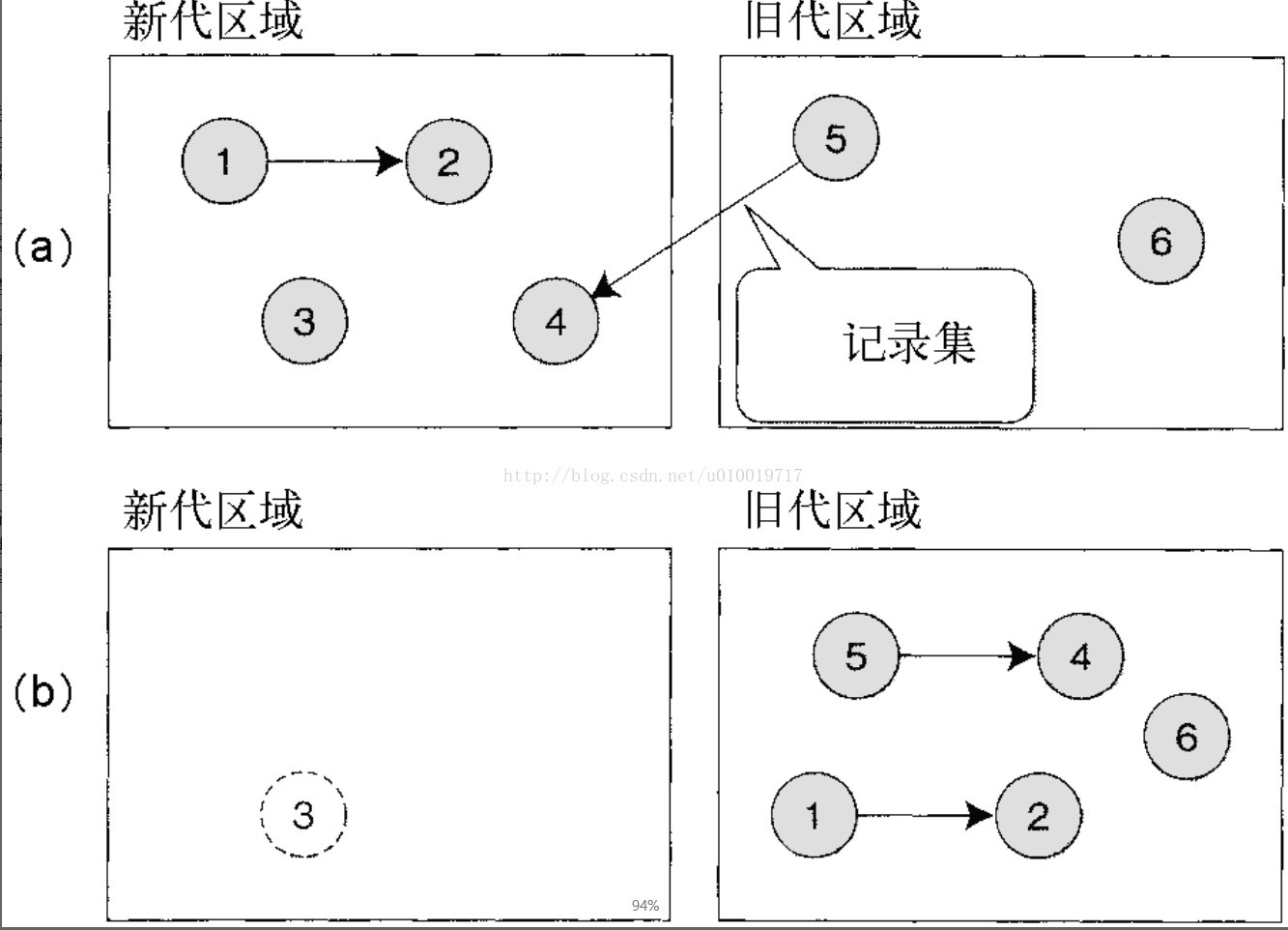
图 14-23 分代垃圾收集的原理。(a)把寿命短的新代区域与寿命长的旧代区域分隔开来管理对象,用记录集来记录两者之间的引用;(b)新代区域中有引用关系的对象移到旧代区域中,释放没有引用关系的对象
分代垃圾收集减少了扫描对象的个数,有缩短平均暂停时间的效果。但是,因为要执行全垃圾收集,最大暂停时间不会得到明显改善。
对于对象寿命假说成立的程序而言,因为减少了扫描对象,吞吐量可以得到巨大改善。但是程序的行为,如把对象分成几代,在什么条件下进行重垃圾收集等,会对性能有非常大的影响。
分代垃圾收集利用对象寿命倾向这一性质是一个非常有趣的主意。除引用计数器方式之外,分代方法可以与许多其他垃圾收集结合起来使用,一般与复制方式相结合得比较多。
最近几乎所有的 Java 都实现有分代垃圾收集。另外,函数型语言 OCaml(Objective Caml)也采用了分代垃圾收集。
14.3.11 保守垃圾收集
像 C 这种本来没有垃圾收集的语言,编译之后没有保留区别整数和指针的信息。因为 CPU 对两者不加区分,所以也就没有这个必要。通常,垃圾收集的实现需要明确区分引用(指针),而 C 和 C++没有这样的功能,在这样的环境下实现垃圾收集的技巧之一称为保守垃圾收集(conservative GC)。
其基本思想就是如果碰巧有整数的值与引用相同的话,该对象就有可能被引用,也就当它是活着的。保守就是倾向于安全的意思。与此相对,能够明确区别引用的环境下的垃圾收集称为精确垃圾收集(exact GC)。
因为倾向于安全一面,保守垃圾收集在 C 或 C++这样没有垃圾收集功能的语言中也可以得到实现,这是它的优点,但反过来,本来应该回收的对象却在意料之外保留下来不能回收,这是它的缺点。还有,它不能与复制垃圾收集这样需要移动对象的垃圾收集算法组合使用。
Ruby 采用的是保守垃圾收集。局部变量可以按照通常语言的访问路径来处理,系统堆栈部分是当作指针数组来扫描的。Ruby 大部分是用 C 编写的,因为有了保守垃圾收集,C 库的实现变得非常简单。 实际上,Python 和 Perl 因为采用的是引用计数器,C 例程内部的引用数管理非常复杂,偶然忘记增减就会发生内存问题。在这一点上,用 C 编写 Ruby 扩展库的时候,基本上不用操心内存管理,好处十分明显。
Ruby 以外有一个名为 Boehm GC( http://www.hpl.hp.com/pesonal/Hans_Boehm/gc/ )的库。它为 C 和 C++增加了垃圾收集功能。Boehm GC 也同时实现了分代垃圾收集。Boehm GC 不仅用于 C 和 C++,在 Scheme 处理系统 Gauche(http://pratical-scheme.net/gauche/)等多种语言处理系统中,也作为垃圾收集功能得到广泛的应用。
14.3.12 增量垃圾收集
在实时性要求高的程序中,相对于吞吐量而言,更重视的是最大暂停时间。比如在机器人姿势控制程序中,如果因为垃圾收集而使控制暂停哪怕是 0.1 秒,机器人就会摔倒。或者是在汽车的刹车控制程序中,如果因为垃圾收集而使反应变慢的话,真是不堪设想。
在这类程序中,垃圾收集带来的中断时间必须是可以预测的。比如可能有类似这样的限制条件:即使是最差的情况,垃圾收集也必须在 10 毫秒内完成。
普通的垃圾收集算法都不能保证这一点。因为暂停时间会随着对象数量和状态而改变。为保证实时性,不需要等垃圾收集完全执行结束,而是要把垃圾收集处理细分成许多细小的片段,每次执行一点,这叫增量垃圾收集。
增量垃圾收集在垃圾收集处理过程中程序也在同时执行,引用有可能会改变。结果是垃圾收集的一致性就不能得到保证。增量垃圾收集为避免这样的问题,采用了与保守垃圾收集相同的写屏蔽技术。
嵌入式处理系统采用的是增量垃圾收集。有名的 Io (http://iolanguage.com/)和 Lua (http://www.lua.org/)都实现了增量垃圾收集。
14.3.13 并行垃圾收集
最新配有多个 CPU 核心的多核电脑开始普及起来。不仅是服务器,美国 Intel 公司的 Core 2 Duo 是个人电脑 CPU,使多核电脑变得不再稀奇。
在这样的多核环境下,灵活运用线程可以最大限度地发挥多个 CPU 的能力。并行垃圾收集就是要最大限度地利用多个 CPU 的能力。
并行垃圾收集的基本原理与增量垃圾收集大致是一样的,都是利用写屏蔽来维护当前状态的信息。有的并行垃圾收集的实现生成垃圾收集专用线程,把垃圾收集设计成总是与普通处理并行执行。
美国 Sun 公司的 Hotspot JVM 等实现了并行垃圾收集。
14.3.14 位图标记
以 Linux 为首的 UNIX 系列操作系统在使用 fork 系统调用复制过程的时候,内存空间并不进行复制而是直接共享。
其中任何一个过程要往内存里写数据的时候,操作系统的虚拟内存系统都会捕捉到这一要求,某个页面要写入数据时则复制该页面
3。这个写时复制(copy-on-write)功能可以减少不必要的页的复制,从而节约内存空间,改善性能。
3 页是虚拟内存管理内存的单位。
不过,垃圾收集与这一为写而复制的功能兼容性不好。给引用对象设置标记的方式会因设置标记而复制包含有该对象的内存页。
复制方式也同样会产生大量写内存的操作。生成子进程处理的程序,会在发生垃圾收集的瞬间引起操作系统复制大量的内存页。利用子进程的程序常常会因为这个内存页复制而引发性能问题。
位图标记是在利用标记的垃圾收集中消减操作系统内存页复制的方法。它不在对象里设置被引用的标记,而是利用外部位图区域(管理用内存区域)来保存引用标记。
结果,只有标记用的位图部分会发生内存页复制,从而避免了复制没有实际更新的对象所在的内存页。
Ruby 的垃圾收集也有了实现位图标记的补丁
4。Web 应用程序环境在有的情况下可以改善性能。
4 详细请引用 http://www.rubyist.net/~matz/20080205.html#p01。














 78
78











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









