







这段时间看了一些关于循环神经网络的资料,也了解了一些框架中对RNN的封装。觉得还是要在非深度学习框架下用最直接的方式过一遍RNN的例子才能更好地理解RNN和其中用到的一系列算法(bptt,sgd,adam等)这篇博客主要结合一个简单的例子理解RNN内部的结构以及bptt算法的过程。还有个小心思,最近CNN相当的火爆,我不信RNN在序列问题上干不过CNN?(开玩笑的。。。其实想有些创新,就要了解原理)
参考资料
http://www.wildml.com/2015/09/recurrent-neural-networks-tutorial-part-1-introduction-to-rnns/
http://cs231n.github.io/neural-networks-case-study/
https://gist.github.com/karpathy/d4dee566867f8291f086
http://cs231n.github.io/optimization-2/#staged
https://www.youtube.com/watch?v=cO0a0QYmFm8&feature=youtu.be&list=PLlJy-eBtNFt6EuMxFYRiNRS07MCWN5UIA&t=836
http://blog.csdn.net/linmingan/article/details/50958304
http://www.wildml.com/2015/10/recurrent-neural-networks-tutorial-part-3-backpropagation-through-time-and-vanishing-gradients/
http://www.wildml.com/2015/10/recurrent-neural-network-tutorial-part-4-implementing-a-grulstm-rnn-with-python-and-theano/
循环神经网络
循环神经网络的思想是利用序列信息。在传统神经网络中,输入之间相互独立。但是对于很多任务,这不是一个好的想法。如果要预测一个句子中下一个出现的单词,我们希望知道哪些词语已经出现过。循环神经网络被叫做“循环”,是因为网络对序列中的每个元素采取同样地操作,这些操作要用到前一步计算的结果。另一种对于循环神经网络的理解是网络有个“记忆单元”,可以捕捉到目前为止的信息。理论上循环神经网络可以发挥任意长序列的信息,但是在实践中,网络往往只能得到较短序列的信息。
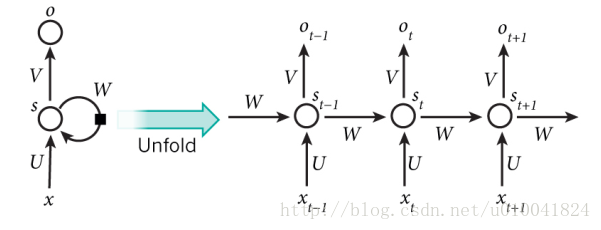
从图中可以看到循环神经网络展开后的状态。例如,如果一个句子包含5个单词,那这个循环神经网络展开后就会有5层,每层的输入对应一个单词。图中,Xt代表着t时刻的输入。在自然语言处理相关任务中输入往往是单词的词向量表示。
St是t时刻隐藏层的状态。他是网络的记忆单元。他的计算需要当前时刻的输入以及前一时刻隐藏层的状态,可表示为St = F(U*Xt + W*St-1)。F函数通常为tanh或者ReLU。St-1在第一时刻通常被初始化为0。想想也是这个道理,对于一个句子,开始的时候我们一无所知,记忆为0,随着一个个单词的读入,我们逐渐掌握很多信息。
Ot是t时刻的输出。通常有 Ot = softmax(V*St)。其实,并不是每个时刻都需要有输出,需要看具体任务。比如,情感分析只要输出最后一个Ot。机器翻译就需要有不同时刻的输出。
我们需要注意的是:
1)St作为网络t时刻的记忆单元,捕捉之前时刻中的信息。Ot的计算只是依靠t时刻的记忆。
2)U,V,W作为网络的参数,需要经过训练得到。并且,U,V,W在时间维度上共享权值。对!没错图中t-1时刻,t时刻,t+1时刻。。。的UVW是同样一组参数。所以,网络的计算过程中,只有每一步的输入是不同的。这样,减少了需要训练的参数的个数。
3) 这篇文章Gradients for an RNN介绍了RNN中梯度的推导过程,我看到过的最值得推荐的资料!!
训练循环神经网络
训练循环神经网络和训练普通的神经网络相似,但是需要用到bptt算法。因为循环神经网络的参数是随时间维度共享的,所以每次输出的梯度不仅需要当前的步骤还需要之前的步骤。例如为了求4时刻的梯度,我们需要计算之前3个时刻的梯度。下面语言模型的例子中展示了bptt算法的过程,再详细介绍。
一个用numpy写的rnn语言模型例子
1)这个例子的功能是在语料上训练,预测下一个出现的字符。
2)通过这个例子可以了解bptt算法实现过程。
代码:
#coding:utf-8
import numpy as np
data = open('input.txt','r').read()
#得到data中的所有字符
chars = list(set(data))
data_size, vocab_size = len(data), len(chars)
print('data has %d characters, %d unique.' % (data_size, vocab_size))
#字典,字符和数字一一对应,输入时用数字代表字符
char_to_ix = {ch:i for i,ch in enumerate(chars)}
ix_to_char = {i:ch for i,ch in enumerate(chars)}
#超参数
#隐层大小
hidden_size = 128
#句子长度
seq_length = 25
#学习率
learning_rate = 1e-1
#模型参数
#输入到隐层矩阵,形状为(hidden_size, vocab_size)为了方便计算,下同
Wxh = np.random.randn(hidden_size, vocab_size)*0.01
#隐层到隐层矩阵
Whh = np.random.randn(hidden_size, hidden_size)*0.01
#隐层到输出矩阵
Why = np.random.randn(vocab_size, hidden_size)*0.01
#隐层及输出层偏置
bh = np.zeros((hidden_size, 1))
by = np.zeros((vocab_size, 1))
#最重要部分,损失函数,包括前向传播,后向计算误差,bptt算法
def lossFun(inputs, targets, hprev):
xs, hs, ys, ps = {}, {}, {}, {}
hs[-1] = np.copy(hprev)
loss = 0
#前向计算预测值
for t in range(len(inputs)):
xs[t] = np.zeros((vocab_size, 1))
xs[t][inputs[t]] = 1
'''
公式
h[t] = tanh(Wxh * x[t] + Whh * h[t-1] + bh)
y[t] = Why * h[t] + by
p[t] = sigmoid(y[t])
loss = -targets*log(p)
'''
hs[t] = np.tanh(np.dot(Wxh, xs[t]) + np.dot(Whh, hs[t-1]) + bh)
ys[t] = np.dot(Why, hs[t]) + by
ps[t] = np.exp(ys[t]) / np.sum(np.exp(ys[t]))
loss += -np.log(ps[t][targets[t],0])
#后向进行梯度下降
#d开头变量用于存储各自变量的梯度
dWxh, dWhh, dWhy = np.zeros_like(Wxh), np.zeros_like(Whh), np.zeros_like(Why)
dbh, dby = np.zeros_like(bh), np.zeros_like(by)
dhnext = np.zeros_like(hs[0])
for t in reversed(range(len(inputs))):
dy = np.copy(ps[t])
dy[targets[t]] -= 1
dWhy += np.dot(dy, hs[t].T)
dby += dy
dh = np.dot(Why.T, dy) + dhnext
dhraw = (1 - hs[t]*hs[t])*dh
dbh += dhraw
dWxh += np.dot(dhraw, xs[t].T)
dWhh += np.dot(dhraw, hs[t-1].T)
dhnext = np.dot(Whh.T, dhraw)
#防止梯度爆炸,控制梯度在-5到5之间
for dparam in [dWxh, dWhh, dWhy, dbh, dby]:
np.clip(dparam, -5, 5, out=dparam)
return loss, dWxh, dWhh, dWhy, dbh, dby, hs[len(inputs)-1]
#用于测试
#根据当前输入字符,产生后面的200个字符
def sample(h, seed_ix, n):
x = np.zeros((vocab_size), 1))
x[seed_ix] = 1
ixes = []
for t in xrange(n):
h = np.tanh(np.dot(Wxh, x) + np.dot(Whh, h) + bh)
y = np.dot(Why, h) + by
p = np.exp(y) / np.sum(np.exp(y))
ix = np.random.choice(range(vocab_size), p=p.ravel())
x = np.zeros((vocab_size, 1))
x[ix] = 1
ixes.append(ix)
return ixes
n, p = 0, 0
#用于Adagrad算法的变量
mWxh, mWhh, mWhy = np.zeros_like(Wxh), np.zeros_like(Whh), np.zeros_like(Why)
mbh, mby = np.zeros_like(bh), np.zeros_like(by)
smooth_loss = -np.log(1.0/vocab_size)*seq_length
while True:
if p+seq_length+1 >= len(data) or n == 0:
hprev = np.zeros((hidden_size,1))
p = 0
inputs = [char_to_ix[ch] for ch in data[p:p+seq_length]]
targets = [char_to_ix[ch] for ch in data[p+1:p+seq_length+1]]
if n%100 == 0:
sample_ix = sample(hprev, inputs[0], 200)
txt = ''.join(ix_to_char[ix] for ix in sample_ix)
print('----\n %s \n----' % (txt, ))
loss, dWxh, dWhh, dWhy, dbh, dby, hprev = lossFun(inputs, targets, hprev)
smooth_loss = smooth_loss * 0.999 + loss * 0.001
if n%100 == 0:
print('iter %d, loss: %f'%(n,smooth_loss))
#Adagrad算法,随机梯度下降法的改进
for param, dparam, mem in zip([Wxh, Whh, Why, bh, by], [dWxh, dWhh, dWhy, dbh, dby], [mWxh, mWhh, mWhy, mbh, mby]):
mem += dparam * dparam
param += -learning_rate * dparam / np.sqrt(mem + 1e-8)
p += seq_length
n += 1
实验结果


例子中bptt算法公式过程

整个公式一气呵成!
总结
这篇文章简单介绍了循环神经网络的基本结构和算法。通过一个小例子,看懂了RNN中的很多细节,然后这只是基础的部分。我们都知道原始的RNN梯度消失问题比较严重,他的变种lstm,gru能够稍微减轻这个问题。还有很多要研究的问题。最重要的应当是RNN的应用问题。后面博主会继续关注~














 6864
6864











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









