







这一节是对上面一节分类的图片进行可视化的,前面的部分基本是一样的,就是载入模块、路径、图片、向前分类,具体程序如下:
//需要的模块,设置好路径和绘图参数,全写在前面了
import numpy as np
import matplotlib.pyplot as plt //画图显示用的
import os
import sys
import pickle
import cv2
import Image //画图显示用的
caffe_root='/home/jiaxuan2/caffe-master/'
//caffe file path
sys.path.insert(0,caffe_root+'python')
//sys.path.insert(0,model's name)或者path.append(model's name表示把caffe model加入路径
import caffe
//import caffe
plt.rcParams['figure.figsize']=(10,10)
plt.rcParams['image.interpolation']='neareat'
plt.rcParams['image.cmap']='gray'
//figure.figsize为图像的大小(分别为宽和高,单位为英寸)
//image.interpolation为'nearest'表示当屏幕像素和图像像素不一致时,并没有在像素间计算插入值(可以理解为过渡值),所以如果屏幕像素过高,只是复制距这个像素点最近的像素值,所以每个像素值看起来像是个小方块。
//默认imshow显示采用的cmap为'jet',这里用'gray',所以显示的图像都是灰度图像。
#test the path ,if no download
os.chdir(caffe_root)
#if not os.path.isfile(caffe_root+'models/bvlc_reference_caffenet/bvlc_reference_caffenet.caffemodel'):
# print("Downloading pre-trained CaffeNet model...")
# !../scripts/download_model_binary.py ../models/bvlc_reference_caffenet
#the above means running
caffe.set_mode_gpu()# 选择使用CPU还是GPU
net_file=caffe_root+'models/bvlc_reference_caffenet/deploy.prototxt'
caffe_model=caffe_root+'models/bvlc_reference_caffenet/bvlc_reference_caffenet.caffemodel'
mean_file=caffe_root+'python/caffe/imagenet/ilsvrc_2012_mean.npy'
//两个必须的文件,deploy文件和model,以及数据均值文件,都需要
net=caffe.Net(net_file,caffe_model,caffe.TEST)
//定义网络模型,参数1 网络结构,参数2 model权值, 参数3 测试阶段
transformer = caffe.io.Transformer({'data': net.blobs['data'].data.shape})
//input preprocessing: 'data' is the name of the input blob == net.inputs[0]
transformer.set_transpose('data', (2,0,1))
//原来读入的数据形式是H*W*K(0,1,2),但我们需要的是K*H*W(2,0,1)transformer.set_mean('data', np.load(caffe_root + 'python/caffe/imagenet/ilsvrc_2012_mean.npy').mean(1).mean(1))
//计算均值,读数据均值文件
transformer.set_raw_scale('data', 255)
//把0-1的数值转化为0-255
transformer.set_channel_swap('data', (2,1,0))
//关于读入的颜色通道,在caffe中读入是BGR(0,1,2),所以要将RGB转化为BGR(2,1,0)
net.blobs['data'].reshape(50,3,227,227)
//设置batch数为50个图像,表示可以批处理,虽然这里只想分类一张图像
img=caffe.io.load_image(caffe_root + 'examples/images/cat.jpg')
//加载要分类的图片,用caffe.io.load_image,并显示
Image.fromarray(img.astype(np.uint8)).show()
net.blobs['data'].data[...] = transformer.preprocess('data', img)
//进行预处理
out = net.forward()
//前向分类
print("Predicted class is #{}.".format(out['prob'][0].argmax()))
//打印出分类结果的最大值,下面是显示出原先的图片
img1=transformer.deprocess('data', net.blobs['data'].data[0])
#imshow the picture
plt.imshow(img1)
plt.show()
//加载labels,使用 np.loadtxt,读的形式是str,分隔符是 '\t'
imagenet_labels_filename = caffe_root + 'data/ilsvrc12/synset_words.txt'
labels=np.loadtxt(imagenet_labels_filename,str,delimiter='\t')
top_k=net.blobs['prob'].data[0].flatten().argsort()[-1:-6:-1]
print labels[top_k]
//前5个可能概率最大的,flatten,是python里面展平的意思
//argsort是从低到高排序,-1到-6表示反过来的1-5个的意思。[-1:-6:-1],最后一个-1表示倒序处理的意思,第一个参数表示起始点包括起始点,第二个参数表示结束点但不包括结束点。最后一个参数如果为负的话,需要保证第一个参数大于第二个参数,表示依次递减逆序,否则会输出空列表。最后一个参数为正同理。
显示小猫图片如下

下面这部分是对各卷积层和参数一些变量的输出
print [(k, v.data.shape) for k, v in net.blobs.items()]
//网络的特征存储在net.blobs,首先是每层的特征和它们的形状。第一个是batch,第二个是feature map数目,第三和第四是每个神经元中的长和宽。
print [(k, v[0].data.shape) for k, v in net.params.items()]
//参数和bias存储在net.params,显示出各层的参数和形状,第一个是批次,第二个 feature map 数目,第三和第四是每个神经元中图片
输出的结果是这样的,因为没排好就勉强看下
blob:是网络特征,【名称,(batch(一次处理多少),feature map的个数,图片size=n*n)】
params:是各层参数和形状,【名称,(输出channel,输入channel,size=n*n)】
结果

然后下面是可视化的一个子函数,把filter放在一个正方形图片里面
//下面是定义了一个子函数,作用是把各层输出的feature map都放在一个正方形的图片里面,相当于写了一个存放的子函数,#输入为格式为数量,高,宽,(3维度),最终展示是在一个方形上
def vis_square(data, padsize=1, padval=0):
data -= data.min()
data /= data.max()
//将各个图片normalization
//n先开方再平方取到正方形的大小
n = int(np.ceil(np.sqrt(data.shape[0])))
padding = ((0, n ** 2 - data.shape[0]), (0, padsize), (0, padsize)) + ((0, 0),) * (data.ndim - 3)
//pad的作用是把不足的框用0补上
data = np.pad(data, padding, mode='constant', constant_values=(padval, padval))
//将filters放进正方形里面
data = data.reshape((n, n) + data.shape[1:]).transpose((0, 2, 1, 3) + tuple(range(4, data.ndim + 1)))
data = data.reshape((n * data.shape[1], n * data.shape[3]) + data.shape[4:])
print data.shape
plt.imshow(data)
plt.show()//显示,服务器上 plt.imshow显示不出来,要加上plt.show(),或者用opencv的这个显示,cv2.imwrite("./out1.jpg",im)前面是存放路径,后面是图片
然后进行可视化,个卷积层和pooling层
//according to the net.params or net.blobs
//the parameters are a list of [weights, biases]
filters = net.params['conv1'][0].data
vis_square(filters.transpose(0, 2, 3, 1))
//这里要转换是因为vis_square函数定义(output_mun,height,width,channels)
//输出的数量是filter的数量,输出96个filter
//params存储网络中间层的网络参数,conv1层的参数尺寸为(96, 3, 11, 11),params['conv1'][0].data为conv1的权重参数,filters转置后的尺寸为(96, 11, 11, 3),符合vis_square函数中data的定义(n, height, width, channels)。
//选择第四张图片(其实那一张都是一样的,因为50张图片是一样的),过滤后输出96张feature map
feat = net.blobs['conv1'].data[4, :96]
vis_square(feat, padval=1)
//输出第一张图片前36张feature map
feat = net.blobs['conv1'].data[0, :36]
vis_square(feat, padval=1)
//#第二个卷积层:有 128 个滤波器,每个尺寸为 5X5X48。我们只显示前面 48 个滤波器,每一个滤波器为一行。
filters = net.params['conv2'][0].data
vis_square(filters[:48].reshape(48**2, 5, 5))
//第二层输出 256 张 feature,这里显示 36 张。
feat = net.blobs['conv2'].data[4, :36]
vis_square(feat, padval=1)
//同上,只是换张图片
feat = net.blobs['conv2'].data[0, :36]
vis_square(feat, padval=1)
//第三个卷积层:全部 384 个 feature map
feat = net.blobs['conv3'].data[4]
vis_square(feat, padval=0.5)
//第四个卷积层:全部 384 个 feature map
feat = net.blobs['conv4'].data[4]
vis_square(feat, padval=0.5)
//第五个卷积层:全部 256 个 feature map
feat = net.blobs['conv5'].data[4]
vis_square(feat, padval=0.5)
//第五个 pooling 层:我们也可以观察 pooling 层
feat = net.blobs['pool5'].data[4]
vis_square(feat, padval=1)
结果的图片,放不下了,放几张意思意思:
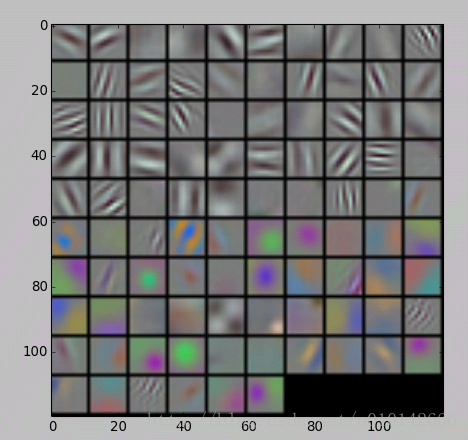
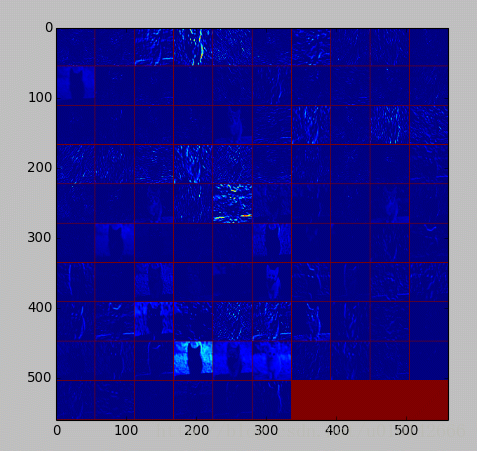
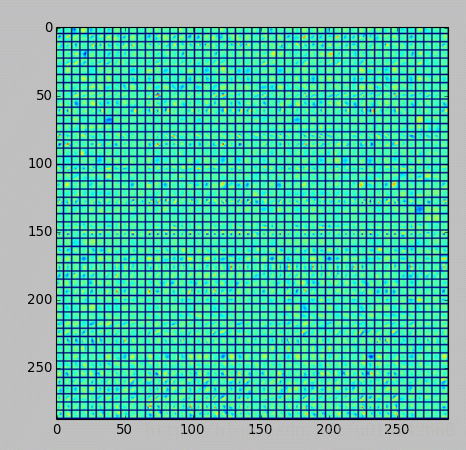
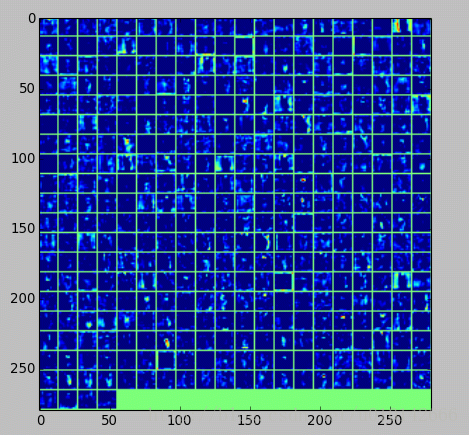
最后是全连接层,先是全连接层4096个神经元的输出值,下面的图是对这些输出值的统计直方图,对于fc6大多数神经元响应值在40以下,比fc7要小。全连接层前后相连,越往后神经元值越不会均匀分布,通过神经元之间的竞争,最后一层全连接层prob产生的尖峰为优胜神经元,该优胜神经元决定了对象属于哪一类。
//第六层(第一个全连接层)输出后的直方分布:
feat = net.blobs['fc6'].data[4]
plt.subplot(2, 1, 1)
plt.plot(feat.flat)
plt.subplot(2, 1, 2)
_ = plt.hist(feat.flat[feat.flat > 0], bins=100)
plt.show()
//第七层(第二个全连接层)输出后的直方分布:可以看出值的分布没有这么平均了。
feat = net.blobs['fc7'].data[4]
plt.subplot(2, 1, 1)
plt.plot(feat.flat)
plt.subplot(2, 1, 2)
_ = plt.hist(feat.flat[feat.flat > 0], bins=100)
plt.show()
//输出优胜神经元
feat = net.blobs['prob'].data[0]
plt.plot(feat.flat)
plt.show()
结果的图是这样的
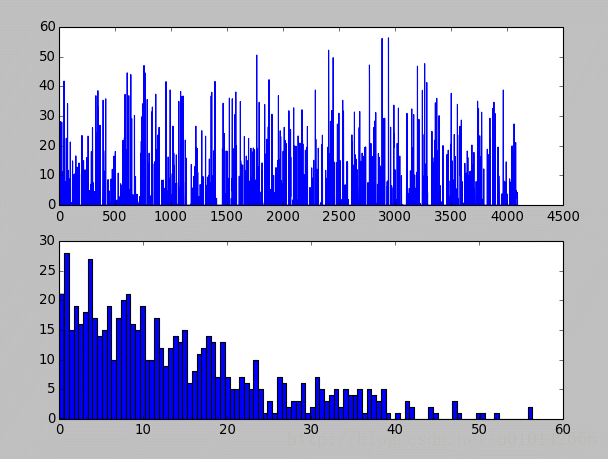
fc6的
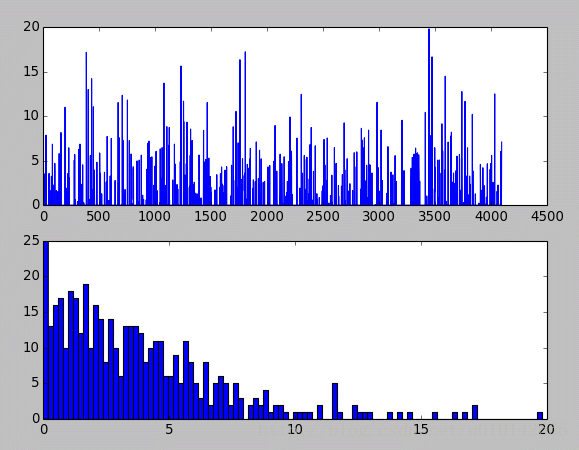
fc7的
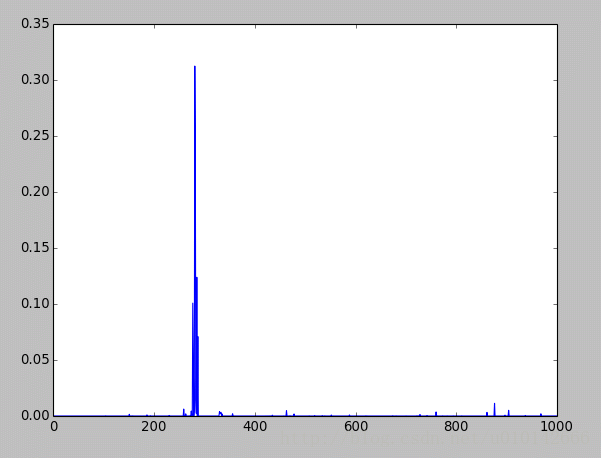
最后的层的














 7248
7248











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









