







使用新浪sdk里面的demo,安装到手机之后认证的显示界面是

里面总共使用了三种授权认证方式,这里面我只讲解第三种授权认证方式,其他两种方式可以自己研究一下。
本人在使用auth2.0的授权认证过程中,重写了该界面.
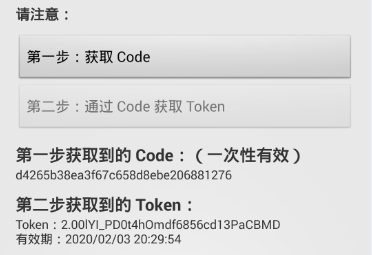
图片中只显示了两个步骤,就是获取code值和Token两个值。
当登录用户打开app应用之后,就是进入当前界面,分别获取这两个值。
当然,这个开放阶段才会给用户看到,发布的时候完全可以跳过这个步骤,直接进入用户的登录界面,让用户输入用户名和密码,并进行授权的界面。这里显示这两个界面是为了对于刚刚着手进行新浪微博客户端开放的开放者进行说明如何进行auth2.0授权认证的。
我们在新浪微博的官方网站里面可以看到进行auth2.0授权认证的步骤,总共分为三步:
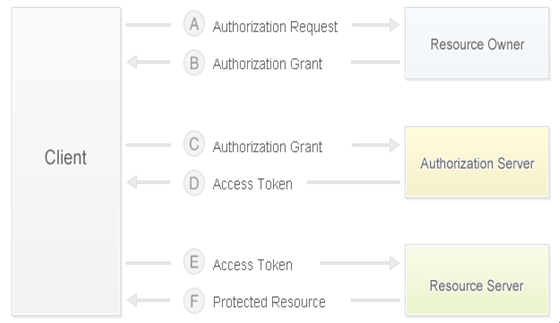
这个图直接使用了新浪微博开放平台所提供的auth2.0的授权认证的步骤图。
这个图中详细介绍了auth2.0认证的过程和各个值的获取。
步骤A:该步是app向新浪微博服务器进行请求,要进行认证授权。对应于点击获取code值这一步操作。
步骤A:该步是app向新浪微博服务器进行请求,要进行认证授权。对应于点击获取code值这一步操作。
步骤B:该步是新浪微博服务器向客户端进行响应,同时服务器返回code值该客户端。
步骤C:该步是app客户端发送获取到的code的值及其他值,向新浪微博服务器发送请求,对应于点击获取Token的操作。
步骤D:该步是新浪微博服务器对客户端进行响应,认证并授权成功,发送Token值给客户端。
步骤E:该步是客户端发送获取的code、Token值等以及其他值向服务器获取被保护的资源。至此用户已经成功利用app成功登录客户端并授权客户端访问到了新浪微博服务器的数据。也就是微博内容。
现在我把效果图展示如下:
获取code值:
获取Token值:
包括返回按钮,刷新,评论、收藏、转发、查看评论等这些功能均是实现了的。
不过有一点要说明,那就是我做这个微博客户端已经很早了,我那时候点赞还不流行,当时没考虑点赞这个功能,所以我这里面实现的时候没有考虑这个功能。各位看官,如果需要自己可以实现一下,如果后期有时间,我把这个功能加进来。^_^
至此大致的效果已经展现出来,给各位看官详细的说明了。不过并没有进行代码的讲解,敬请关注下一讲——auth2.0认证详解。














 437
437











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









