







结合上面两篇博文的内容,首先提一下hadoop的安装和配置。
Hadoop-利用java API操作HDFS文件
Hadoop-MapReduce初步应用-统计单词个数
上面两篇文章中提到了如何安装和配置hadoop。以及一些视频资料的下载。这两篇文章包括本文的代码示例均是伪分布下hadoop的开发完成的。
下面开始本文中题目所说的web日志信息的挖掘。
首先给出web日志文件的下载:请猛戳这里!
有了该文件之后,可以打开看看里面的内容,内容示例如下:
222.68.172.190 - - [18/Sep/2013:06:49:57 +0000] \"GET /images/my.jpg HTTP/1.1\" 200 19939 \"http://www.angularjs.cn/A00n\" \"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/29.0.1547.66 Safari/537.36\"这是正常情况下一条web信息日志所记录的信息。(关于这里使用到的日志信息,请参考原创作者:海量Web日志分析 用Hadoop提取KPI统计指标 | 粉丝日志)
首先最终原创作者的成果。非常感谢前辈!前辈的项目使用的是eclipse结合Maven开发的工程项目。
本人在原创作者的基础上,没有使用Maven,仅仅使用eclipse工具下java工程项目进行的。后期项目完成以后,会附上下载地址供大家下载学习交流。
在开发写代码之前,需要把日志文件上传到HDFS文件系统中,HDFS上传命令如下:

我这里吧文件上传到HDFS根目录下。
下面开发代码,有了上面的日志信息以后,就需要对日志信息就行解析,比较好的方式就是使用解析类完成,代码如下;
private String remote_addr;// 记录客户端的ip地址
private String remote_user;// 记录客户端用户名称,忽略属性"-"
private String time_local;// 记录访问时间与时区
private String request;// 记录请求的url与http协议
private String status;// 记录请求状态;成功是200
private String body_bytes_sent;// 记录发送给客户端文件主体内容大小
private String http_referer;// 用来记录从那个页面链接访问过来的
private String http_user_agent;// 记录客户浏览器的相关信息
private boolean valid = true;// 判断数据是否合法
private static KPI parser(String line) {
System.out.println(line);
KPI kpi = new KPI();
String[] arr = line.split(" ");
if (arr.length > 11) {
kpi.setRemote_addr(arr[0]);
kpi.setRemote_user(arr[1]);
kpi.setTime_local(arr[3].substring(1));
kpi.setRequest(arr[6]);
kpi.setStatus(arr[8]);
kpi.setBody_bytes_sent(arr[9]);
kpi.setHttp_referer(arr[10]);
if (arr.length > 12) {
kpi.setHttp_user_agent(arr[11] + " " + arr[12]);
} else {
kpi.setHttp_user_agent(arr[11]);
}
if (Integer.parseInt(kpi.getStatus()) >= 400) {// 大于400,HTTP错误
kpi.setValid(false);
}
} else {
kpi.setValid(false);
}
return kpi;
}这里使用parser方法进行解析。解析得到八个信息值。
有了这些信息值以后,就可以根据这些信息值就行统计。原创作者在代码中完成了四项统计工作。
分别统计了访问网站的独立IP的统计,网页访问次数的统计,一天之内每小时的访问次数统计,和访问网站的浏览器类型的统计。
关于统计的信息说明以及如何统计,原创博文中说明的很详细了,链接在此,请点击:海量Web日志分析 用Hadoop提取KPI统计指标 作者的博文写的真是通俗易懂。在此我就不罗嗦了。
下面给出日志解析工具类的完成代码如下:
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.HashSet;
import java.util.Locale;
import java.util.Set;
/*
* KPI Object
* 日志文件每一行作为一条记录,该类完成每一行日志的解析
*/
public class KPI {
private String remote_addr;// 记录客户端的ip地址
private String remote_user;// 记录客户端用户名称,忽略属性"-"
private String time_local;// 记录访问时间与时区
private String request;// 记录请求的url与http协议
private String status;// 记录请求状态;成功是200
private String body_bytes_sent;// 记录发送给客户端文件主体内容大小
private String http_referer;// 用来记录从那个页面链接访问过来的
private String http_user_agent;// 记录客户浏览器的相关信息
private boolean valid = true;// 判断数据是否合法
private static KPI parser(String line) {
System.out.println(line);
KPI kpi = new KPI();
String[] arr = line.split(" ");
if (arr.length > 11) {
kpi.setRemote_addr(arr[0]);
kpi.setRemote_user(arr[1]);
kpi.setTime_local(arr[3].substring(1));
kpi.setRequest(arr[6]);
kpi.setStatus(arr[8]);
kpi.setBody_bytes_sent(arr[9]);
kpi.setHttp_referer(arr[10]);
if (arr.length > 12) {
kpi.setHttp_user_agent(arr[11] + " " + arr[12]);
} else {
kpi.setHttp_user_agent(arr[11]);
}
if (Integer.parseInt(kpi.getStatus()) >= 400) {// 大于400,HTTP错误
kpi.setValid(false);
}
} else {
kpi.setValid(false);
}
return kpi;
}
/**
* 按page的pv分类
*/
public static KPI filterPVs(String line) {
KPI kpi = parser(line);
Set<String> pages = new HashSet<String>();
pages.add("/about");
pages.add("/black-ip-list/");
pages.add("/cassandra-clustor/");
pages.add("/finance-rhive-repurchase/");
pages.add("/hadoop-family-roadmap/");
pages.add("/hadoop-hive-intro/");
pages.add("/hadoop-zookeeper-intro/");
pages.add("/hadoop-mahout-roadmap/");
if (!pages.contains(kpi.getRequest())) {
kpi.setValid(false);
}
return kpi;
}
/**
* 按page的独立ip分类
*/
public static KPI filterIPs(String line) {
KPI kpi = parser(line);
Set<String> pages = new HashSet<String>();
pages.add("/about");
pages.add("/black-ip-list/");
pages.add("/cassandra-clustor/");
pages.add("/finance-rhive-repurchase/");
pages.add("/hadoop-family-roadmap/");
pages.add("/hadoop-hive-intro/");
pages.add("/hadoop-zookeeper-intro/");
pages.add("/hadoop-mahout-roadmap/");
if (!pages.contains(kpi.getRequest())) {
kpi.setValid(false);
}
return kpi;
}
/**
* PV按浏览器分类
*/
public static KPI filterBroswer(String line) {
return parser(line);
}
/**
* PV按小时分类
*/
public static KPI filterTime(String line) {
return parser(line);
}
/**
* PV按访问域名分类
*/
public static KPI filterDomain(String line){
return parser(line);
}
@Override
public String toString() {
StringBuilder sb = new StringBuilder();
sb.append("valid:" + this.valid);
sb.append("\nremote_addr:" + this.remote_addr);
sb.append("\nremote_user:" + this.remote_user);
sb.append("\ntime_local:" + this.time_local);
sb.append("\nrequest:" + this.request);
sb.append("\nstatus:" + this.status);
sb.append("\nbody_bytes_sent:" + this.body_bytes_sent);
sb.append("\nhttp_referer:" + this.http_referer);
sb.append("\nhttp_user_agent:" + this.http_user_agent);
return sb.toString();
}
public String getRemote_addr() {
return remote_addr;
}
public void setRemote_addr(String remote_addr) {
this.remote_addr = remote_addr;
}
public String getRemote_user() {
return remote_user;
}
public void setRemote_user(String remote_user) {
this.remote_user = remote_user;
}
public String getTime_local() {
return time_local;
}
public Date getTime_local_Date() throws ParseException {
SimpleDateFormat df = new SimpleDateFormat("dd/MMM/yyyy:HH:mm:ss", Locale.US);
return df.parse(this.time_local);
}
public String getTime_local_Date_hour() throws ParseException{
SimpleDateFormat df = new SimpleDateFormat("yyyyMMddHH");
return df.format(this.getTime_local_Date());
}
public void setTime_local(String time_local) {
this.time_local = time_local;
}
public String getRequest() {
return request;
}
public void setRequest(String request) {
this.request = request;
}
public String getStatus() {
return status;
}
public void setStatus(String status) {
this.status = status;
}
public String getBody_bytes_sent() {
return body_bytes_sent;
}
public void setBody_bytes_sent(String body_bytes_sent) {
this.body_bytes_sent = body_bytes_sent;
}
public String getHttp_referer() {
return http_referer;
}
public String getHttp_referer_domain(){
if(http_referer.length()<8){
return http_referer;
}
String str=this.http_referer.replace("\"", "").replace("http://", "").replace("https://", "");
return str.indexOf("/")>0?str.substring(0, str.indexOf("/")):str;
}
public void setHttp_referer(String http_referer) {
this.http_referer = http_referer;
}
public String getHttp_user_agent() {
return http_user_agent;
}
public void setHttp_user_agent(String http_user_agent) {
this.http_user_agent = http_user_agent;
}
public boolean isValid() {
return valid;
}
public void setValid(boolean valid) {
this.valid = valid;
}
public static void main(String args[]) {
String line = "222.68.172.190 - - [18/Sep/2013:06:49:57 +0000] \"GET /images/my.jpg HTTP/1.1\" 200 19939 \"http://www.angularjs.cn/A00n\" \"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/29.0.1547.66 Safari/537.36\"";
System.out.println(line);
KPI kpi = new KPI();
//每一行内容,按空格分割成数组中保存
String[] arr = line.split(" ");
//保存访问的ip地址
kpi.setRemote_addr(arr[0]);
//保存访问的用户,该值在文件中基本无效,该值为-
kpi.setRemote_user(arr[1]);
//保存访问时间
kpi.setTime_local(arr[3].substring(1));
//保存访问的请求地址
kpi.setRequest(arr[6]);
//保存访问的请求状态,正常情况,该值为200
kpi.setStatus(arr[8]);
//保存服务器响应的字节数
kpi.setBody_bytes_sent(arr[9]);
//保存从何处访问来
kpi.setHttp_referer(arr[10]);
//保存浏览器或者客户单信息
kpi.setHttp_user_agent(arr[11] + " " + arr[12]);
System.out.println(kpi);
try {
SimpleDateFormat df = new SimpleDateFormat("yyyy.MM.dd:HH:mm:ss", Locale.US);
System.out.println(df.format(kpi.getTime_local_Date()));
System.out.println(kpi.getTime_local_Date_hour());
System.out.println(kpi.getHttp_referer_domain());
} catch (ParseException e) {
e.printStackTrace();
}
}
}代码中包含了main方法,可以进行测试,测试日志的解析是否正确无误,测试结果如下:
/**
* 222.68.172.190 - - [18/Sep/2013:06:49:57 +0000] "GET /images/my.jpg HTTP/1.1" 200 19939 "http://www.angularjs.cn/A00n" "Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/29.0.1547.66 Safari/537.36"
* valid:true
* remote_addr:222.68.172.190
* remote_user:-
* time_local:18/Sep/2013:06:49:57
* request:/images/my.jpg
* status:200
* body_bytes_sent:19939
* http_referer:"http://www.angularjs.cn/A00n"
* http_user_agent:"Mozilla/5.0 (Windows
* 2013.09.18:06:49:57
* 2013091806
* www.angularjs.cn
*/有了上面的解析工具类,下面就可以利用MapReduce完成信息的统计。
- 网站资源的访问次数的统计
首先看网站每个页面的访问次数的统计,在类中,详细给出了功能性的注释,具体看代码:
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
import org.apache.hadoop.mapred.TextInputFormat;
import org.apache.hadoop.mapred.TextOutputFormat;
/**
* 页面访问量统计MapReduce
* 统计每个页面的访问次数
* 完成的功能类似于单词统计:
* 以每个访问网页的资源路径为键,经过mapreduce任务,
* 最终得到每一个资源路径的访问次数
*/
public class KPIPV {
public static class KPIPVMapper extends MapReduceBase implements Mapper<Object, Text, Text, IntWritable> {
private IntWritable one = new IntWritable(1);
private Text word = new Text();
@Override
public void map(Object key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException {
KPI kpi = KPI.filterPVs(value.toString());
if (kpi.isValid()) {
/**
* 以页面的资源路径为键,每访问一次,值为1
* 作为map任务的输出
*/
word.set(kpi.getRequest());
output.collect(word, one);
}
}
}
public static class KPIPVReducer extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
@Override
public void reduce(Text key, Iterator<IntWritable> values, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException {
int sum = 0;
while (values.hasNext()) {
sum += values.next().get();
}
result.set(sum);
output.collect(key, result);
}
}
public static void main(String[] args) throws Exception {
/**
* 对应于HDFS中文件所在的位置路径
*/
String input = "hdfs://centos:9000/access.log.10";
/**
* 对应HDFS中的输出文件。文件不能事先存在。否则出错
*/
String output = "hdfs://centos:9000/out_kpipv";
JobConf conf = new JobConf(KPIPV.class);
conf.setJobName("KPIPV");
// conf.addResource("classpath:/hadoop/core-site.xml");
// conf.addResource("classpath:/hadoop/hdfs-site.xml");
// conf.addResource("classpath:/hadoop/mapred-site.xml");
//设置map输出的键类型,对应于map的输出以资源路径字符串作为键
conf.setMapOutputKeyClass(Text.class);
//设置map输出的值类型,对应于map输出,值为1
conf.setMapOutputValueClass(IntWritable.class);
//设置reduce的输出键类型,和map相同
conf.setOutputKeyClass(Text.class);
//设置reduce的输出值类型,和map相同,不过是累加的值
conf.setOutputValueClass(IntWritable.class);
//设置map类
conf.setMapperClass(KPIPVMapper.class);
//设置合并函数,该合并函数和reduce完成相同的功能,提升性能,减少map和reduce之间数据传输量
conf.setCombinerClass(KPIPVReducer.class);
//设置reduce类
conf.setReducerClass(KPIPVReducer.class);
//设置输入文件类型,默认TextInputFormat,该行代码可省略
conf.setInputFormat(TextInputFormat.class);
//设置输出文件类型,默认TextOutputFormat,该行代码可省略
conf.setOutputFormat(TextOutputFormat.class);
//设置输入文件路径
FileInputFormat.setInputPaths(conf, new Path(input));
//设置输出文件路径。该路径不能存在,否则出错!!!
FileOutputFormat.setOutputPath(conf, new Path(output));
//运行启动任务
JobClient.runJob(conf);
System.exit(0);
}
}代码中给出了大部分的注释,网站网页的访问次数,通过统计日志文件的每一行记录,统计每一行日志的访问网站的资源路径为键,相同的资源路径累加1,最后即可得到访问网站网页的访问次数。
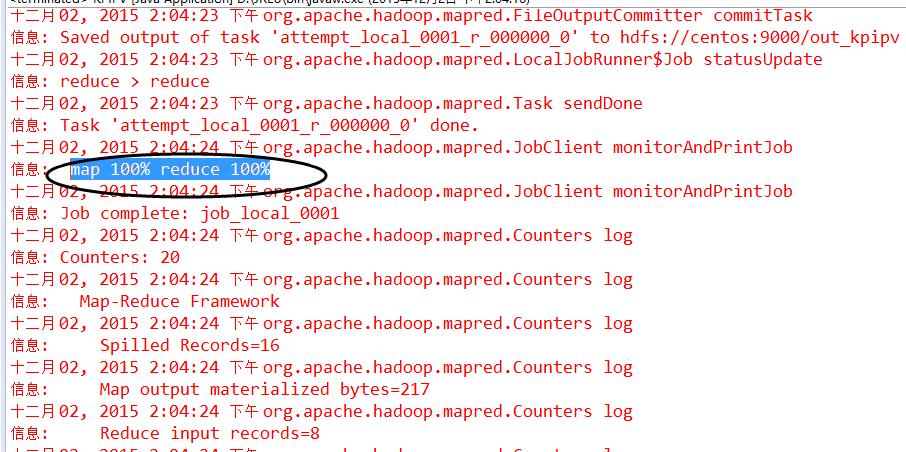
运行代码,控制台日志信息输出正常,无异常信息。下面看看HDFS文件的输出情况:
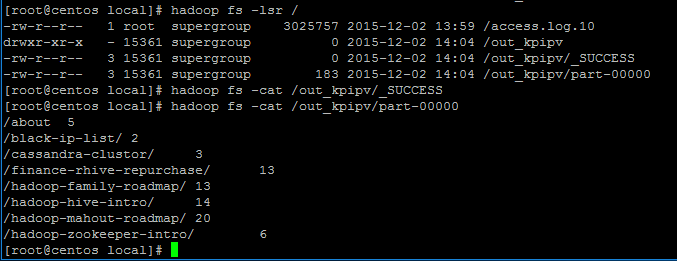
out_kpipv输出文件已经被创建,同时,该文件下还有一个_SUCCESS文件和part-00000文件。分别打开文件查看内容发现,_SUCCESS文件里面没有内容,part-00000文件内记录了结果信息。
前面是资源路径,后面的数字对应该资源路径被访问的次数。
- 访问网站的独立IP统计
代码如下:
import java.io.IOException;
import java.util.HashSet;
import java.util.Iterator;
import java.util.Set;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
import org.apache.hadoop.mapred.TextInputFormat;
import org.apache.hadoop.mapred.TextOutputFormat;
/**
* 统计每个资源路径的ip访问MapReduce
* map以资源路径为键,以ip为值输出
* reduce完成以资源路径为键,ip统计值为值写入到结果文件中。
*
* 完成的功能类似于单词统计!!
*/
public class KPIIP {
public static class KPIIPMapper extends MapReduceBase implements Mapper<Object, Text, Text, Text> {
private Text word = new Text();
private Text ips = new Text();
@Override
public void map(Object key, Text value, OutputCollector<Text, Text> output, Reporter reporter) throws IOException {
KPI kpi = KPI.filterIPs(value.toString());
if (kpi.isValid()) {
/**
* 以请求的资源路径为键
* 以ip为值
*/
word.set(kpi.getRequest());
ips.set(kpi.getRemote_addr());
output.collect(word, ips);
}
}
}
public static class KPIIPReducer extends MapReduceBase implements Reducer<Text, Text, Text, Text> {
private Text result = new Text();
private Set<String> count = new HashSet<String>();
@Override
public void reduce(Text key, Iterator<Text> values, OutputCollector<Text, Text> output, Reporter reporter) throws IOException {
/**
* 以资源路径为键
* 以相同资源路径的ip值的个数,添加入set集合中作为值
* 写入到结果文件中
*/
while (values.hasNext()) {
count.add(values.next().toString());
}
//结果集中存放的是独立ip的个数
result.set(String.valueOf(count.size()));
output.collect(key, result);
}
}
public static void main(String[] args) throws Exception {
String input = "hdfs://centos:9000/access.log.10";
String output = "hdfs://centos:9000/out_kpiip";
JobConf conf = new JobConf(KPIIP.class);
conf.setJobName("KPIIP");
// conf.addResource("classpath:/hadoop/core-site.xml");
// conf.addResource("classpath:/hadoop/hdfs-site.xml");
// conf.addResource("classpath:/hadoop/mapred-site.xml");
conf.setMapOutputKeyClass(Text.class);
conf.setMapOutputValueClass(Text.class);
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(Text.class);
conf.setMapperClass(KPIIPMapper.class);
conf.setCombinerClass(KPIIPReducer.class);
conf.setReducerClass(KPIIPReducer.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(input));
FileOutputFormat.setOutputPath(conf, new Path(output));
JobClient.runJob(conf);
System.exit(0);
}
}有了第一个mapreduce的完成,下面的三个类你会发现大同小异,所以代码中没有给出注释,注释部分请参考第一个网站资源访问次数的统计部分。网站的独立ip的统计,是根据日志文件中每一条日志信息中访问资源的ip的个数进行统计的。以资源路径为键,不同的ip值进行累加即可得出结果。
运行代码结果如下:

out_kpiip文件夹被创建,下面看该文件夹下的内容:
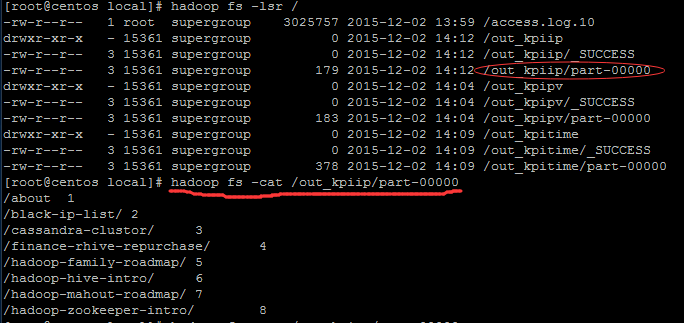
输出结果文件中,前面对应资源路径,后面数字对应独立ip的个数。
- 每小时访问网站的次数统计
代码如下:
import java.io.IOException;
import java.text.ParseException;
import java.util.Iterator;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
import org.apache.hadoop.mapred.TextInputFormat;
import org.apache.hadoop.mapred.TextOutputFormat;
/**
* 用户每小时访问量统计
*/
public class KPITime {
public static class KPITimeMapper extends MapReduceBase implements Mapper<Object, Text, Text, IntWritable> {
private IntWritable one = new IntWritable(1);
private Text word = new Text();
@Override
public void map(Object key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException {
KPI kpi = KPI.filterBroswer(value.toString());
if (kpi.isValid()) {
try {
word.set(kpi.getTime_local_Date_hour());
output.collect(word, one);
} catch (ParseException e) {
e.printStackTrace();
}
}
}
}
public static class KPITimeReducer extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
@Override
public void reduce(Text key, Iterator<IntWritable> values, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException {
int sum = 0;
while (values.hasNext()) {
sum += values.next().get();
}
result.set(sum);
output.collect(key, result);
}
}
public static void main(String[] args) throws Exception {
String input = "hdfs://centos:9000/access.log.10";
String output = "hdfs://centos:9000/out_kpitime";
JobConf conf = new JobConf(KPITime.class);
conf.setJobName("KPITime");
// conf.addResource("classpath:/hadoop/core-site.xml");
// conf.addResource("classpath:/hadoop/hdfs-site.xml");
// conf.addResource("classpath:/hadoop/mapred-site.xml");
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
conf.setMapperClass(KPITimeMapper.class);
conf.setCombinerClass(KPITimeReducer.class);
conf.setReducerClass(KPITimeReducer.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(input));
FileOutputFormat.setOutputPath(conf, new Path(output));
JobClient.runJob(conf);
System.exit(0);
}
}每小时访问网站的次数统计是以每小时时间为键,每小时时间段内的访问次数进行累加即可得到结果。
运行代码如下:
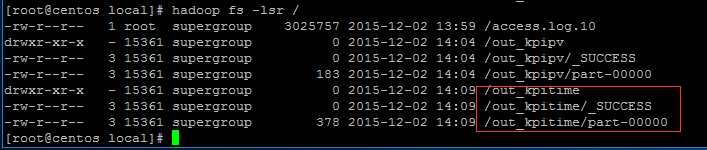
out_kpitime文件夹创建。下面查看文件夹内容:
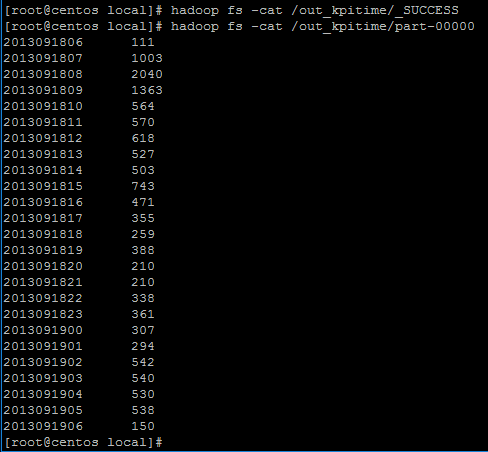
可以看到日志文件前面一行对应2013年9月18日这一天每一小时的时间信息,后面的数字对应该一小时内网站的访问次数。
- 访问网站的浏览器类型统计
import java.io.IOException;
import java.util.Iterator;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapred.JobClient;
import org.apache.hadoop.mapred.JobConf;
import org.apache.hadoop.mapred.MapReduceBase;
import org.apache.hadoop.mapred.Mapper;
import org.apache.hadoop.mapred.OutputCollector;
import org.apache.hadoop.mapred.Reducer;
import org.apache.hadoop.mapred.Reporter;
import org.apache.hadoop.mapred.TextInputFormat;
import org.apache.hadoop.mapred.TextOutputFormat;
/**
* 浏览器统计MapReduce
*
*/
public class KPIBrowser {
public static class KPIBrowserMapper extends MapReduceBase implements Mapper<Object, Text, Text, IntWritable> {
private IntWritable one = new IntWritable(1);
private Text word = new Text();
@Override
public void map(Object key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException {
KPI kpi = KPI.filterBroswer(value.toString());
if (kpi.isValid()) {
word.set(kpi.getHttp_user_agent());
output.collect(word, one);
}
}
}
public static class KPIBrowserReducer extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
@Override
public void reduce(Text key, Iterator<IntWritable> values, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException {
int sum = 0;
while (values.hasNext()) {
sum += values.next().get();
}
result.set(sum);
output.collect(key, result);
}
}
public static void main(String[] args) throws Exception {
String input = "hdfs://centos:9000/access.log.10";
String output = "hdfs://centos:9000/out_kpibrowser";
JobConf conf = new JobConf(KPIBrowser.class);
conf.setJobName("KPIBrowser");
// conf.addResource("classpath:/hadoop/core-site.xml");
// conf.addResource("classpath:/hadoop/hdfs-site.xml");
// conf.addResource("classpath:/hadoop/mapred-site.xml");
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
conf.setMapperClass(KPIBrowserMapper.class);
conf.setCombinerClass(KPIBrowserReducer.class);
conf.setReducerClass(KPIBrowserReducer.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(input));
FileOutputFormat.setOutputPath(conf, new Path(output));
//启动任务
JobClient.runJob(conf);
System.exit(0);
}
}直接看结果:
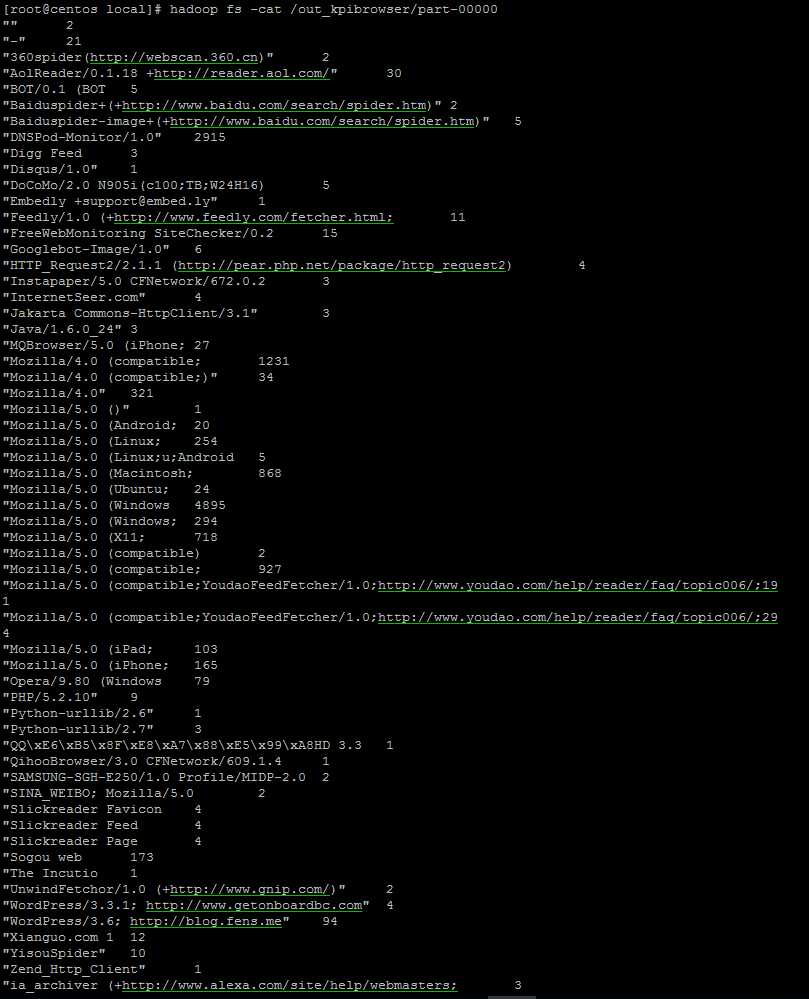
结果中输出了各种客户端对网站的访问情况。
结束!
原作者的文章地址:http://blog.fens.me/hadoop-mapreduce-log-kpi/
原作者的代码使用eclipse和maven结合使用的。我在此基础上,没有使用maven,而是使用eclipse创建java工程完成。
本项目的代码地址:请猛戳这里(欢迎关注我的GITHUB)
项目使用eclipse构建。方便易用,代码注释详细。














 2057
2057











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









