







1.Dense
全连接层(对上一层的神经元进行全部连接,实现特征的非线性组合)
keras.layers.core.Dense(units, activation=None, use_bias=True, kernel_initializer='glorot_uniform', bias_initializer='zeros', kernel_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, bias_constraint=None)
Dense就是常用的全连接层,所实现的运算是output = activation(dot(input, kernel)+bias)。其中activation是逐元素计算的激活函数,kernel````是本层的权值矩阵,bias为偏置向量,只有当use_bias=True```才会添加。
如果本层的输入数据的维度大于2,则会先被压为与kernel相匹配的大小。
-
units:大于0的整数,代表该层的输出维度。
-
activation:激活函数,为预定义的激活函数名(参考激活函数),或逐元素(element-wise)的Theano函数。如果不指定该参数,将不会使用任何激活函数(即使用线性激活函数:a(x)=x)
-
use_bias: 布尔值,是否使用偏置项
# as first layer in a sequential model:
model = Sequential()
model.add(Dense(32, input_shape=(16,))) #input_shape=(16,)等价于input_dim=16
# now the model will take as input arrays of shape (*, 16) ,输入维度=16
# and output arrays of shape (*, 32) ,输出维度=32
# after the first layer, you don't need to specify
# the size of the input anymore:
model.add(Dense(32)) #这一层的input_shape=(32,)
全连接层(Fully Connected layer)就是使用了softmax激励函数作为输出层的多层感知机(Multi-Layer Perceptron),其他很多分类器如支持向量机也使用了softmax。“全连接”表示上一层的每一个神经元,都和下一层的每一个神经元是相互连接的。
卷积层和池化层呢个的输出代表了输入图像的高级特征,全连接层的目的就是用这些特征进行分类,类别基于训练集。比如图14所示的图像分类任务,有四种可能的类别。(注意,图14没有显示出所有的神经元节点)
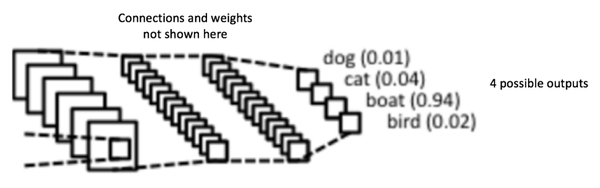
图14:全连接层——每个节点都与相邻层的所有节点相连
除了分类以外,加入全连接层也是学习特征之间非线性组合的有效办法。卷积层和池化层提取出来的特征很好,但是如果考虑这些特征之间的组合,就更好了。
全连接层的输出概率之和为1,这是由激励函数Softmax保证的。Softmax函数把任意实值的向量转变成元素取之0-1且和为1的向量。
2.Reshape
用来将输入shape转换为特定的shape
# as first layer in a Sequential model
model = Sequential()
model.add(Reshape((3, 4), input_shape=(12,)))
# now: model.output_shape == (None, 3, 4) ,None任意正整数
# note: `None` is the batch dimension ,批次大小,就是每次样本数量
# as intermediate layer in a Sequential model ,中间层
model.add(Reshape((6, 2)))
# now: model.output_shape == (None, 6, 2)
# also supports shape inference using `-1` as dimension ,推断inference ,自动判断大小
model.add(Reshape((-1, 2, 2)))
# now: model.output_shape == (None, 3, 2, 2),3*2*2=12
3.BatchNormalization
该层在每个batch上将前一层的激活值重新规范化,即使得其输出数据的均值接近0,其标准差接近1
由于在训练神经网络的过程中,每一层的 params是不断更新的,由于params的更新会导致下一层输入的分布情况发生改变,所以这就要求我们进行权重初始化,减小学习率。这个现象就叫做internal covariate shift。虽然可以通过whitening来加速收敛,但是需要的计算资源会很大。而Batch Normalizationn的思想则是对于每一组batch,在网络的每一层中,分feature对输入进行normalization,对各个feature分别normalization,即对网络中每一层的单个神经元输入,计算均值和方差后,再进行normalization。对于CNN来说normalize “Wx+b”而非 “x”,也可以忽略掉b,即normalize “Wx”,而计算均值和方差的时候,是在feature map的基础上(原来是每一个feature)
详细参考:http://blog.csdn.net/meanme/article/details/48679785
4.Activation
激活层对一个层的输出施加激活函数
5.Dropout
为输入数据施加Dropout。Dropout将在训练过程中每次更新参数时随机断开一定百分比(rate)的输入神经元,Dropout层用于防止过拟合。
6.UpSampling2D
上采样,扩大矩阵,可以用于复原图像等。

keras.layers.convolutional.UpSampling2D(size=(2, 2), data_format=None)
将数据的行和列分别重复size[0]和size[1]次
7.Conv2D
keras.layers.convolutional.Conv2D(filters, kernel_size, strides=(1, 1), padding='valid', data_format=None, dilation_rate=(1, 1), activation=None, use_bias=True, kernel_initializer='glorot_uniform', bias_initializer='zeros', kernel_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, bias_constraint=None)
二维卷积层,即对图像的空域卷积。该层对二维输入进行滑动窗卷积,当使用该层作为第一层时,应提供input_shape参数。例如input_shape = (128,128,3)代表128*128的彩色RGB图像(data_format='channels_last').
参数
-
filters:卷积核的数目(即输出的维度)
-
kernel_size:单个整数或由两个整数构成的list/tuple,卷积核的宽度和长度。如为单个整数,则表示在各个空间维度的相同长度。
-
strides:单个整数或由两个整数构成的list/tuple,为卷积的步长。如为单个整数,则表示在各个空间维度的相同步长。任何不为1的strides均与任何不为1的dilation_rata均不兼容
-
padding:补0策略,为“valid”, “same” 。“valid”代表只进行有效的卷积,即对边界数据不处理。“same”代表保留边界处的卷积结果,通常会导致输出shape与输入shape相同,因为卷积核移动时在边缘会出现大小不够的情况。
-
activation:激活函数,为预定义的激活函数名(参考激活函数),或逐元素(element-wise)的Theano函数。如果不指定该参数,将不会使用任何激活函数(即使用线性激活函数:a(x)=x)
-
dilation_rate:单个整数或由两个个整数构成的list/tuple,指定dilated convolution中的膨胀比例。任何不为1的dilation_rata均与任何不为1的strides均不兼容。
-
data_format:字符串,“channels_first”或“channels_last”之一,代表图像的通道维的位置。该参数是Keras 1.x中的image_dim_ordering,“channels_last”对应原本的“tf”,“channels_first”对应原本的“th”。以128x128的RGB图像为例,“channels_first”应将数据组织为(3,128,128),而“channels_last”应将数据组织为(128,128,3)。该参数的默认值是
~/.keras/keras.json中设置的值,若从未设置过,则为“channels_last”。 -
use_bias:布尔值,是否使用偏置项
-
kernel_initializer:权值初始化方法,为预定义初始化方法名的字符串,或用于初始化权重的初始化器。参考initializers
-
bias_initializer:权值初始化方法,为预定义初始化方法名的字符串,或用于初始化权重的初始化器。参考initializers
-
kernel_regularizer:施加在权重上的正则项,为Regularizer对象
-
bias_regularizer:施加在偏置向量上的正则项,为Regularizer对象
-
activity_regularizer:施加在输出上的正则项,为Regularizer对象
-
kernel_constraints:施加在权重上的约束项,为Constraints对象
-
bias_constraints:施加在偏置上的约束项,为Constraints对象
卷积的根本目的是从输入图片中提取特征。
在下右图中,假如每个神经元只和10×10个像素值相连,那么权值数据为1000000×100个参数,减少为原来的千分之一。而那10×10个像素值对应的10×10个参数,其实就相当于卷积操作。

如下图所示,展示了一个33的卷积核在55的图像上做卷积的过程。每个卷积都是一种特征提取方式,就像一个筛子,将图像中符合条件(激活值越大越符合条件)的部分筛选出来。
参考:http://www.36dsj.com/archives/24006

model.add(Conv2D(64, 5, strides=2, input_shape=(28,28,1),padding='same', activation=LeakyReLU(alpha=0.2)))
5为卷积核大小,共有64个卷积核(卷积核矩阵的具体值是随机生成的吗?,参考:https://zhuanlan.zhihu.com/p/25754846),strides=2,每次移动步长为2,28/2=14,用大小为5的卷积核移动14次得到的就是一个14*14的矩阵,采用64个不同的卷积核(为了抽取不同的特征)可以得到14*14*16的特征。
model.add(Conv2D(128, 5, strides=2, input_shape=(28,28,1),padding='same', activation=LeakyReLU(alpha=0.2)))
model.add(Conv2D(256, 5, strides=2, padding='same', activation=LeakyReLU(alpha=0.2)))
model.add(Conv2D(512, 5, strides=1, padding='same', activation=LeakyReLU(alpha=0.2)))
因为strides=1所以得到的大小还是4*4,共有512的特征

8.Conv2DTranspose
keras.layers.convolutional.Conv2DTranspose(filters, kernel_size, strides=(1, 1), padding='valid', data_format=None, activation=None, use_bias=True, kernel_initializer='glorot_uniform', bias_initializer='zeros', kernel_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, bias_constraint=None)
该层是转置的卷积操作(反卷积)。需要反卷积的情况通常发生在用户想要对一个普通卷积的结果做反方向的变换。例如,将具有该卷积层输出shape的tensor转换为具有该卷积层输入shape的tensor。同时保留与卷积层兼容的连接模式。
当使用该层作为第一层时,应提供input_shape参数。例如input_shape = (3,128,128)代表128*128的彩色RGB图像
参数
-
filters:卷积核的数目(即输出的维度)
-
kernel_size:单个整数或由两个个整数构成的list/tuple,卷积核的宽度和长度。如为单个整数,则表示在各个空间维度的相同长度。
-
strides:单个整数或由两个整数构成的list/tuple,为卷积的步长。如为单个整数,则表示在各个空间维度的相同步长。任何不为1的strides均与任何不为1的dilation_rata均不兼容
-
padding:补0策略,为“valid”, “same” 。“valid”代表只进行有效的卷积,即对边界数据不处理。“same”代表保留边界处的卷积结果,通常会导致输出shape与输入shape相同。
-
activation:激活函数,为预定义的激活函数名(参考激活函数),或逐元素(element-wise)的Theano函数。如果不指定该参数,将不会使用任何激活函数(即使用线性激活函数:a(x)=x)
-
dilation_rate:单个整数或由两个个整数构成的list/tuple,指定dilated convolution中的膨胀比例。任何不为1的dilation_rata均与任何不为1的strides均不兼容。
-
data_format:字符串,“channels_first”或“channels_last”之一,代表图像的通道维的位置。该参数是Keras 1.x中的image_dim_ordering,“channels_last”对应原本的“tf”,“channels_first”对应原本的“th”。以128x128的RGB图像为例,“channels_first”应将数据组织为(3,128,128),而“channels_last”应将数据组织为(128,128,3)。该参数的默认值是
~/.keras/keras.json中设置的值,若从未设置过,则为“channels_last”。 -
use_bias:布尔值,是否使用偏置项
图中,我们使用了卷积的倒数,即转置卷积(transposed convolution),从 100 维的噪声(满足 -1 至 1 之间的均匀分布)中生成了假图像。如在 DCGAN 模型中提到的那样,去掉微步进卷积,这里我们采用了模型前三层之间的上采样来合成更逼真的手写图像。在层与层之间,我们采用了批量归一化的方法来平稳化训练过程。以 ReLU 函数为每一层结构之后的激活函数。最后一层 Sigmoid 函数输出最后的假图像。第一层设置了 0.3-0.5 之间的 dropout 值来防止过拟合。具体代码如下。

self.G = Sequential()
dropout = 0.4
depth = 64+64+64+64
dim = 7
# In: 100
# Out: dim x dim x depth
self.G.add(Dense(dim*dim*depth, input_dim=100))
self.G.add(BatchNormalization(momentum=0.9))
self.G.add(Activation('relu'))
self.G.add(Reshape((dim, dim, depth)))
self.G.add(Dropout(dropout))
# In: dim x dim x depth
# Out: 2*dim x 2*dim x depth/2
self.G.add(UpSampling2D()) #扩大一倍14
self.G.add(Conv2DTranspose(int(depth/2), 5, padding='same'))
self.G.add(BatchNormalization(momentum=0.9))
self.G.add(Activation('relu'))
self.G.add(UpSampling2D()) #扩大一倍28
self.G.add(Conv2DTranspose(int(depth/4), 5, padding='same'))
self.G.add(BatchNormalization(momentum=0.9))
self.G.add(Activation('relu'))
self.G.add(Conv2DTranspose(int(depth/8), 5, padding='same')) #这层没有上采样
self.G.add(BatchNormalization(momentum=0.9))
self.G.add(Activation('relu'))
# Out: 28 x 28 x 1 grayscale image [0.0,1.0] per pix
self.G.add(Conv2DTranspose(1, 5, padding='same')) #卷积核数为1,还原为1张图片
self.G.add(Activation('sigmoid'))
self.G.summary()
return self.G
9.Flatten
Flatten层用来将输入“压平”,即把多维的输入一维化,常用在从卷积层到全连接层的过渡。Flatten不影响batch的大小。
model = Sequential()
model.add(Convolution2D(64, 3, 3, border_mode='same', input_shape=(3, 32, 32)))
# now: model.output_shape == (None, 64, 32, 32)
model.add(Flatten())
# now: model.output_shape == (None, 65536)=64*32*32,压平了
10.LeakyReLU
keras.layers.advanced_activations.LeakyReLU(alpha=0.3)
LeakyRelU是修正线性单元(Rectified Linear Unit,ReLU)的特殊版本,当不激活时,LeakyReLU仍然会有非零输出值,从而获得一个小梯度,避免ReLU可能出现的神经元“死亡”现象。即,f(x)=alpha * x for x < 0, f(x) = x for x>=0
参数
- alpha:大于0的浮点数,代表激活函数图像中第三象限线段的斜率
11.ReLU
参考:https://zhuanlan.zhihu.com/p/25754846
如图3所示,每个卷积操作之后,都有一个叫ReLU的附加操作。ReLU的全称是纠正线性单元(Rectified Linear Unit),是一种非线性操作,其输出如下:
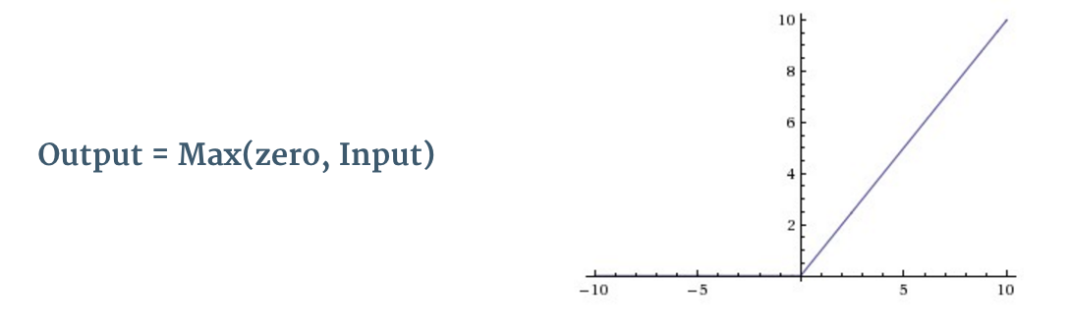
图8:ReLU
ReLU是以像素为单位生效的,其将所有负值像素替换为0。ReLU的目的是向卷积网络中引入非线性,因为真实世界里大多数需要学习的问题都是非线性的(单纯的卷积操作时线性的——矩阵相乘、相加,所以才需要额外的计算引入非线性)。
图9可以帮助我们清晰地理解,ReLU应用在图6得到的特征映射上,输出的新特征映射也叫“纠正”特征映射。(黑色被抹成了灰色)
 图9:ReLU
图9:ReLU
其他非线性方程比如tanh或sigmoid也可以替代ReLU,但多数情况下ReLU的表现更好。
12.MaxPooling2D
空间池化(也叫亚采样或下采样)降低了每个特征映射的维度,但是保留了最重要的信息。空间池化可以有很多种形式:最大(Max),平均(Average),求和(Sum)等等。
以最大池化为例,我们定义了空间上的邻域(2x2的窗)并且从纠正特征映射中取出窗里最大的元素。除了取最大值以额外,我们也可以取平均值(平均池化)或者把窗里所有元素加起来。实际上,最大池化已经显示了最好的成效。
图10显示了对纠正特征映射的最大池化操作(在卷积+ReLU之后),使用的是2x2的窗。
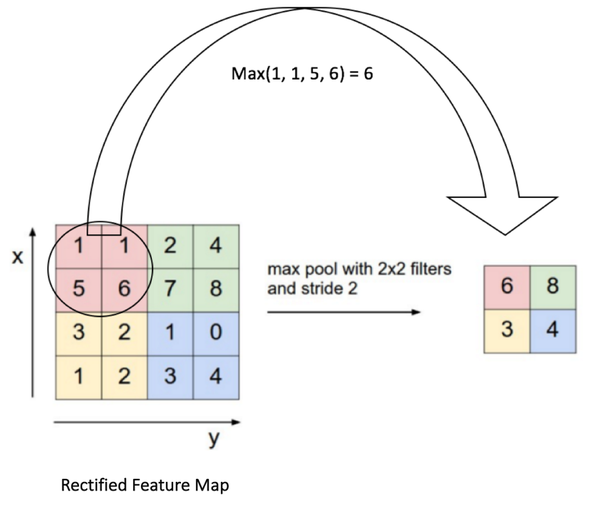
图10:最大池化
池化的功能室逐步减少输入表征的空间尺寸。特别地,池化
- 使输入表征(特征维度)更小而易操作
- 减少网络中的参数与计算数量,从而遏制过拟合
- 增强网络对输入图像中的小变形、扭曲、平移的鲁棒性(输入里的微小扭曲不会改变池化输出——因为我们在局部邻域已经取了最大值/平均值)。
- 帮助我们获得不因尺寸而改变的等效图片表征。这非常有用,因为这样我们就可以探测到图片里的物体,不论那个物体在哪。
13 反向传播训练
联合起来——反向传播训练
综上,卷积+池化是特征提取器,全连接层是分类器。
注意图15,因为输入图片是条船,所以目标概率对船是1,其他类别是0.
- 输入图像 = 船
- 目标向量 = [0, 0, 1 ,0]
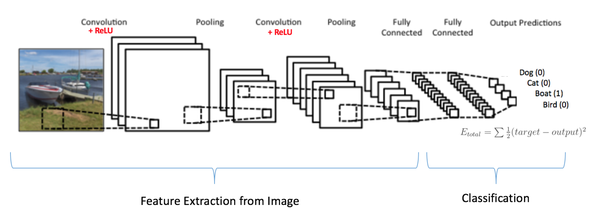
图15:训练卷积神经网络
卷积网络的训练过程可以概括如下:
- Step 1: 用随机数初始化所有的滤波器和参数/权重
-
Step 2: 网络将训练图片作为输入,执行前向步骤(卷积,ReLU,池化以及全连接层的前向传播)并计算每个类别的对应输出概率。
- 假设船图的输出概率是[0.2, 0.4, 0.1, 0.3]
- 因为第一个训练样本的权重都是随机的,所以这个输出概率也跟随机的差不多
-
Step 3: 计算输出层的总误差(4类别之和)
- 总误差=∑12(目标概率−输出概率)2总误差=∑12(目标概率−输出概率)2
-
Step 4: 反向传播算法计算误差相对于所有权重的梯度,并用梯度下降法更新所有的滤波器/权重和参数的值,以使输出误差最小化。
- 权重的调整程度与其对总误差的贡献成正比。
- 当同一图像再次被输入,这次的输出概率可能是[0.1, 0.1, 0.7, 0.1],与目标[0, 0, 1, 0]更接近了。
- 这说明我们的神经网络已经学习着分类特定图片了,学习的方式是调整权重/滤波器以降低输出误差。
- 如滤波器个数、滤波器尺寸、网络架构这些参数,是在Step 1之前就已经固定的,且不会在训练过程中改变——只有滤波矩阵和神经元突触权重会更新。
以上步骤训练了卷积网络——本质上就是优化所有的权重和参数,使其能够正确地分类训练集里的图片。
当一个新的(前所未见的)的图片输入至卷积网络,网络会执行前向传播步骤并输出每个类别的概率(对于新图像,输出概率用的也是训练过的权重值)。如果我们的训练集足够大,网络就有望正确分类新图片,获得良好的泛化(generalization)能力。
-














 349
349











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









