







Preface
今天下午把Caffe Tutorial中的Blobs, Layers, and Nets: anatomy of a Caffe model这一节阅读了一遍。先在这里进行大概的总结(现在意识到了总结的用处),以后随着深度的进行慢慢加深。
优点:
1. 速度快。Google Protocol Buffer数据标准为Caffe提升了效率。
2. 学术论文采用此模型较多。不确定是不是最多,但接触到的不少论文都与Caffe有关(R-CNN,DSN,最近还有人用Caffe实现LSTM)缺点:
1. 曾更新过重要函数接口。有人反映,偶尔会出现接口变换的情况,自己很久前写的代码可能过了一段时间就不能和新版本很好地兼容了。(现在更新速度放缓,接口逐步趋于稳定)
2. 对于某些研究方向来说的人并不适合,这个需要对Caffe的结构有一定了解。
确实,我目前看的Semantic Image Segmentation相关的Paper,几乎都是用caffe实现的。所以,我目前着重于caffe。也玩过Tensorflow,不过速度似乎好慢。
OK,言归正传。
Blob
Blob是caffe中基本的数据结构,用来存储与交流数据。并且它可以在CPU与GPU之间同步数据,提供了统一的存储接口来处理数据。
像图像数据(batches of images)、神经网络参数(model parameters)以及神经网络进行Back propagation运算进行学习时产生的导数数据(derivatives for optimization),都可以用Blob结构来存储与交流。
Blob结构从数学上来说,是一个N维数组,按照C-contiguous方式来存储。
这里的C-contiguous fashion,我google了一下,指的就是内存存储是连续的,不间断的存储的。具体的解释见下面两个网址:
1. What is the difference between contiguous and non-contiguous arrays?
2. C Contiguous Memory
具体的来讲,上面的N维数组中的N,是4。例如对于一批如下图像数据:
图像的数量number: N
图像的通道数channel: K
图像的高度height: H
图像的宽度width: W于是其Blob数据结构为:N* K * H * W。当然,实际物理存储上,是按照行占优(row-major)方式存储的。
因此,对于(n, k, h, w)的位置,其物理内存地址即为:
((n×K+k)×H+h)×W+w
Blob存储的数据分为两类:data,diff,前者指的是我们在网络间正常交流的数据,如图像像素数据之类的;后者指的是Back propagation进行学习时,运算得到的梯度数据。
由于这些数据可以在CPU上计算、也可以在GPU上运算,因此,要想获取这些数据分别有两种方式。拿在CPU上运算的data数据举例:
const Dtype* cpu_data() const; //不可改变数据值
Dtype* mutable_cpu_data(); //可以改变数据值这在源码中:~/caffe/include/caffe/blob.hpp 中,体现如下:
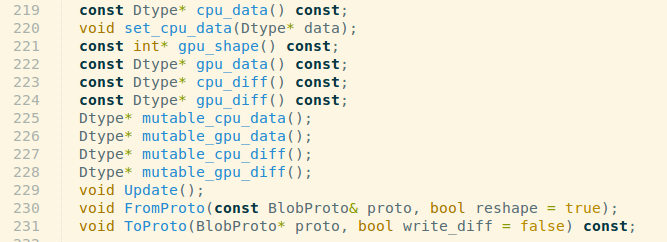
这样设计的原因是,caffe为了在CPU与GPU之间同步数据时,隐藏同步的细节以及尽可能减小数据传输的量,于是使用了SyncedMem类。这里的一个建议是,如果不需要改变数据的值,尽可能的使用const访问的方式。
还有就是,Tutorial上提到一点,对于纯粹应用的人;来说应该没多大关系。我还是看了一下,写的是当实际操作中,有GPU存在的时候,一开始数据已经从硬盘读到CPU中,此时系统内核会调用GPU来计算,同时,CPU中不会将数据传送到下一个网络中了,“为了保持高层的表现性能略过低层的细节信息”,这句话的意思我不太懂,原句是:
ignoring low-level details while maintaining a high level of performance
最后所有的网络层都有GPU的实现,所有的中间数据以及计算的梯度数据都会存储在GPU中。这部分不是太懂,可能涉及到操作系统的知识,等弄懂了再来细细补充~
Layer computation and connections
在Blob之后,就是关键的Layer层了,这是组成神经网络模型的基础,也是进行计算求解的基础。
Layers层中要进行许多运算:
- convolve filters:卷积层,进行卷积
- pool:池化层,进行池化
- take inner products:进行内积运算
- apply nonlinearities like rectified linear, sigmoid:进行非线性映射,如ReLU函数(非线性校正单元)、Sigmoid函数
- normalize:归一化
- load data:载入数据
- compute losses like softmax and hinge:计算损失函数,如softmax、hinge
在Tutorial中Layer这个页面中,详细地讲解了Layer中的不同的Layer、其间的运算细节。
所有的Layer层都可以由底层得到输入数据,进行计算,再向前输出计算数据。
每一层定义了3种重要的计算:setup(初始化)、forward(向前传播)、backward(向后传播)。
1. Setup:在神经网络一开始初始化的时候,对本层的网络进行初始化以及初始化其连接。
2. Forward:从当前这层网络的下一层得到输入数据,经过计算(网络间的权值,进行加权计算),得到运算结果并送往下一神经网络层。
3. Backward:得到由上一神经网络层计算的梯度输出结果,在本层对其进行梯度计算,传输给下一层进行计算。这里我多说一句,实际上,梯度下降运用到的一个数学理论就是求导中的链式求导法则(chain rule)。正因为这个法则,所以造成了后向传播容易造成了著名的Vanishing gradient problem(梯度消失)以及gradient explosion(梯度爆炸)问题。
在caffe中,Forward与Backward各有两种实现版本,一种是用于CPU计算,另一种是用于GPU计算。如果你不用GPU的实现版本,神经网络层的计算会用CPU的版本,CPU版本就类似于一种备用吧。caffe在CPU与GPU计算之间的切换十分的灵活方便,GPU计算更快,仅在CPU与GPU之间传输数据与复制数据时需要额外的消费。
Net definition and operation
caffe中的神经网络是由一系列连接的Layer组成的 a directed acyclic graph(DAG,有向无环图) 。
caffe会在进行前向传播forward与后向传播backward的时候,对DAG中的所有层进行记录(bookkeeping),以确保正确。一个典型的网络是从底端的读入数据层(data layer)开始,以要进行特定任务(如图像分类与重建)的损失层(losslLayer)结束。
caffe是由一个纯文本模块化语言来定义描述神经网络层与它们之间的联系的。如下一个简单的逻辑回归分类器:
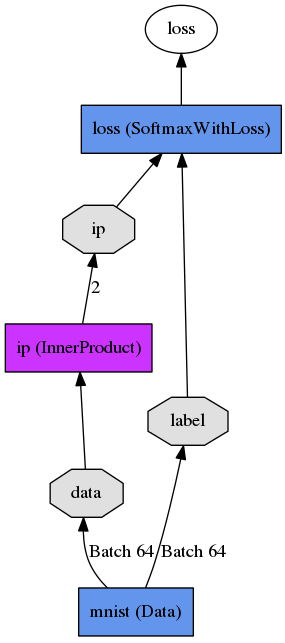
其纯文本描述为:
name:"LogReg"
layer{
name:"mnist"
type:"Data"
top:"data"
top:"label"
data_param{
source:"Input_leveldb"
batch_size:64
}
}
layer{
name:"ip"
type:"InnerProduct"
bottom:"data"
top:"ip"
inner_product_param{
num_output:2
}
}
layer{
name:"loss"
type:"SoftmaxWithLoss"
bottom:"ip"
bottom:"label"
top:"loss"
}这里要说明一下的是,像上面的这幅图片,是caffe里面自带的画图工具实现的。就是/cafferoot/python/draw_net.py这个python文件,怎么运行呢?是这样的,首先需要自定义好纯文本描述网络结构的文件,如这里的LogReg.prototxt,之后就可以如下输入命令:
$ python draw_net.py /home/chenxp/programtest/LogReg.prototxt /home/chenxp/test.png --rankdir BT以上命令中,/home/chenxp/programtest/LogReg.prototxt是你写好的网络结构的文件,/home/chenxp/test.png是输出图片的路径以及图片名,最后的--rankdir BT是指定输出网络的方向,默认是LR,即从左到右,我指定的是BT,意思是从下往上绘制神经网络结构图。
模块的初始化是由Net::Init()函数来进行的,初始化做两件事:
1. 创造Blob数据块与Layer层,初步搭起网络结构图的大致架构;
2. 调用神经网络层的SetUp()初始化函数。
除了以上这两件“大事”,初始化工作浏览网络架构,验证正确性,在初始化的时候,网络会在终端里打印出初始化期间的日志信息(截取自Tutorial):
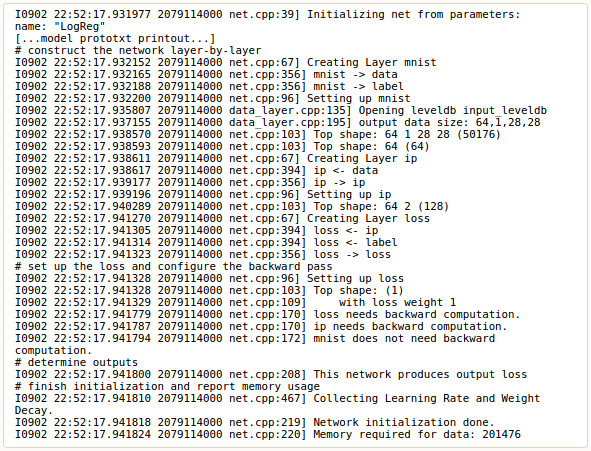
注意到这里网络的构建过程是与设备无关的(device agnostic),之前提到过,在神经网络模型定义的时候,Blob与Layer层隐藏了实现了细节。在网络构建完成后,通过定义在caffe::mode()的转换函数来决定网络是用CPU跑还是GPU跑,通过Caffe::set_mode()来设定。神经网络层通过CPU计算得到的结果与通过GPU计算得到的结果是一样的(由计算机的数值误差决定,但是可以通过测试来预防避免)。
Conclusion
今天上午看了一会儿SVM、CRF方面的,最后还是想,把最近研究的Fully Convolutional Network研究透,准备自己着手训练一组数据,先试试看。因为不知怎么的,我测试FCN-32s Fully Convolutional Semantic Segmentation on PASCAL-Context的时候,当stride是32的时候,即fcn-32s-pascalcontext.caffemodel,可以测试出结果,虽然不是很好:
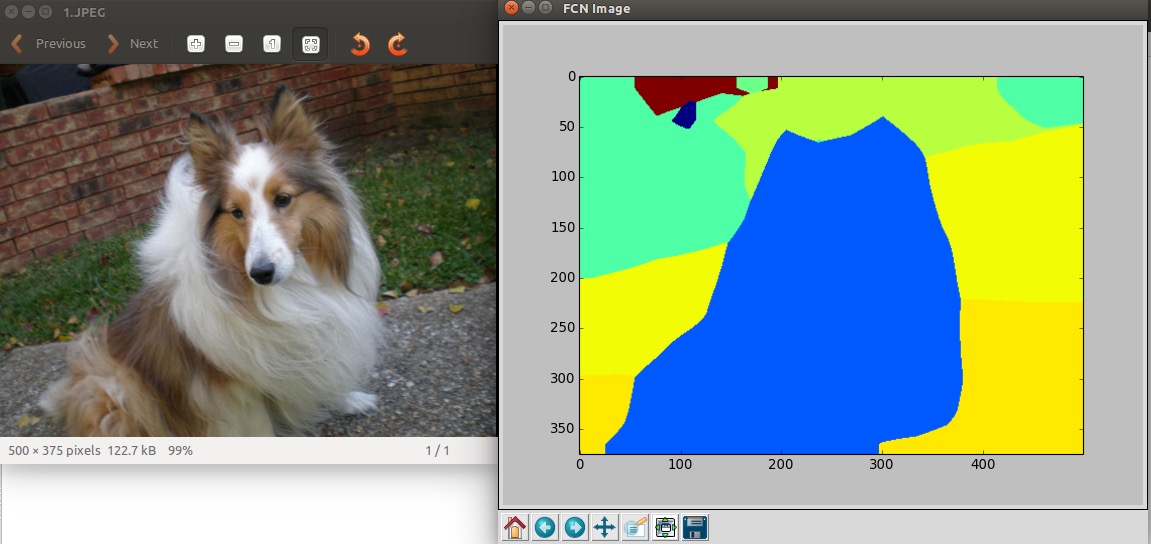
但是,当我用fcn-16s-pascalcontext.caffemodel以及其他stride的caffemodel时,基本出不了结果。但是我看Github上还有有人跑出良好的结果的,我想是不是需要自己训练一下。所以,这两天把caffe好好研究一下,目标可以自己写出eval.py,deploy.prototxt这些文件,部署自己的caffe~
今天看的其实还没到源码部分,caffe的源码写的很规范,很棒,一定要看看,所以这一页会补上源码部分的分析,稍后~^_^














 800
800











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









