






Preface
这是一篇译文,原文作者是Tomasz Malisiewicz大神,这是他在博客Tombone’s Computer Vision Blog的文章,一发出来就引起这个圈子的广泛关注。微信公众号“机器之心”在第一时间提供了译文,我仔细看了一下,发现这篇译文翻译的有些地方比较拗口,还有遗漏的地方。所以,我在这里还是按照自己的理解翻译一下,时间精力所限,到最后有一节就略过了。希望能够互相学习,共同探讨。
以下是译文。
Deep Learning Trends @ ICLR 2016
Started by the youngest members of the Deep Learning Mafia [1], namely Yann LeCun and Yoshua Bengio, the ICLR conference is quickly becoming a strong contender for the single most important venue in the Deep Learning space. More intimate than NIPS and less benchmark-driven than CVPR, the world of ICLR is arXiv-based and moves fast.

Today’s post is all about ICLR 2016. I’ll highlight new strategies for building deeper and more powerful neural networks, ideas for compressing big networks into smaller ones, as well as techniques for building “deep learning calculators.” A host of new artificial intelligence problems is being hit hard with the newest wave of deep learning techniques, and from a computer vision point of view, there’s no doubt that deep convolutional neural networks are today’s “master algorithm” for dealing with perceptual data.
Deep Powwow in Paradise? ICLR 2016 was held in Puerto Rico.
Whether you’re working in Robotics, Augmented Reality, or dealing with a computer vision-related problem, the following summary of ICLR research trends will give you a taste of what’s possible on top of today’s Deep Learning stack. Consider today’s blog post a reading group conversation-starter.Part I: ICLR vs CVPR
Part II: ICLR 2016 Deep Learning Trends
Part III: Quo Vadis Deep Learning?
由“深度学习帮”最年轻的两位大牛:Yann LeCun与Yoshua Bengio发起的ICLR 会议已经成为深度学习领域最有竞争力的会议。比NIPS会议更加精通这块,也比CVPR更少的以“数据集基准驱动”,ICLR以arXiv为基础,发展的很快。
今天的这篇文章全是关于ICLR 2016的。我将着重突出深度学习领域对于更深更强大神经网络的构建,神经网络压缩问题,以及“神经网络计算器”的构建技术问题。一系列新的人工智能问题正是最新的深度学习技术浪潮所要攻克的难关,从计算机视觉的角度来看,深度卷积神经网络正毫无疑问的成为解决感知数据的“最主流算法”。
当你从事机器人、增强现实行业,或者处理计算机视觉相关的问题,下面对ICLR研究趋势的总结会带你品尝最顶尖深度学习所带来的各种可能性。你可以考虑将这篇文章作为你们阅读小组讨论的引子。
下面是这篇文章的结构:
Part I: ICLR vs CVPR:第一部分,会将ICLR与CVPR进行一次比较;
Part II: ICLR 2016 Deep Learning Trends:第二部分介绍ICLR 2016会议上深度学习的趋势;
Part III: Quo Vadis Deep Learning?:第三部分,深度学习将要往何处去?
Part I: ICLR vs CVPR
Last month’s International Conference of Learning Representations, known briefly as ICLR 2016, and commonly pronounced as “eye-clear,” could more appropriately be called the International Conference on Deep Learning. The ICLR 2016 conference was held May 2nd-4th 2016 in lovely Puerto Rico. This year was the 4th installment of the conference – the first was in 2013 and it was initially so small that it had to be co-located with another conference. Because it was started by none other than the Deep Learning Mafia, it should be no surprise that just about everybody at the conference was studying and/or applying Deep Learning Methods. Convolutional Neural Networks (which dominate image recognition tasks) were all over the place, with LSTMs and other Recurrent Neural Networks (used to model sequences and build “deep learning calculators”) in second place. Most of my own research conference experiences come from CVPR (Computer Vision and Pattern Recognition), and I’ve been a regular CVPR attendee since 2004. Compared to ICLR, CVPR has a somewhat colder, more-emprical feel. To describe the difference between ICLR and CVPR, Yan LeCun, quoting Raquel Urtasun (who got the original saying from Sanja Fidler), put it best on Facebook.
上个月,国际会议“Learning Representation”,简称 ICLR 2016(通常发音“eye-clear”),更合适的名称是深度学习国际会议。ICLR 2016会议与5月2日到5月4日在可爱的波多黎各举办。今年是这个会议的第四年了 —— 第一次举办是在2013年,并且开始规模很小,得与其他会议共用一个地方。因为这是由深度学习帮派举办的会议,所以毫无疑问的每个在会议上的都是学习使用深度学习方法的。卷积神经网络(统治了图像识别领域)在会议上到处可见,第二名的就是LSTM以及其他递归神经网络(RNN,用来对序列数据进行建模,以及创建“深度学习计算器”)。我的大多数会议经验来自于CVPR(Computer Vision and Pattern Recognition),我从2004年开始就是CVPR参会的常客。相比较于ICLR,CVPR给人更加冰冷冷,更加注重实证的感觉。为了形容ICLR以及CVPR之间的区别,Yan LeCun引用Raquel Urtasun 的话(最开始是从Sanja Fidler传来的),并把它推送到了Facebook上:
The ICLR 2016 conference was my first official powwow that truly felt like a close-knit “let’s share knowledge” event. 3 days of the main conference, plenty of evening networking events, and no workshops. With a total attendance of about 500, ICLR is about 1/4 the size of CVPR. In fact, CVPR 2004 in D.C. was my first conference ever, and CVPRs are infamous for their packed poster sessions, multiple sessions, and enough workshops/tutorials to make CVPRs last an entire week. At the end of CVPR, you’ll have a research hangover and will need a few days to recuperate. I prefer the size and length of ICLR.
ICLR 2016会议是我第一次感觉到这是一场严谨的“让我们来分享知识”的正式会议。3天的主会议,有许多晚上的网络活动,没有研讨会。总共参会人数大约500人,ICLR的规模只有CVPR的1/4。实际上,2004年在D. C.举办的CVPR是我第一次参加这种会议,CVPR因为它们海报展览会、各种各样的其他会议,以及足够多的研讨会,能让CVPR持续一周。在CVPR的最后,你会感觉到一种“宿醉”的感觉,也会使你花费数天来“恢复原状”。我更喜欢ICLR的会议规模以及持续的时间长度。
CVPR and NIPS, like many other top-tier conferences heavily utilizing machine learning techniques, have grown to gargantuan sizes, and paper acceptance rates at these mega conferences are close to 20%. It not necessarily true that the research papers at ICLR were any more half-baked than some CVPR papers, but the amount of experimental validation for an ICLR paper makes it a different kind of beast than CVPR. CVPR’s main focus is to produce papers that are ‘state-of-the-art’ and this essentially means you have to run your algorithm on a benchmark and beat last season’s leading technique. ICLR’s main focus it to highlight new and promising techniques in the analysis and design of deep convolutional neural networks, initialization schemes for such models, and the training algorithms to learn such models from raw data.
CVPR以及NIPS,像其他许多使用机器学习的顶级会议一样,已经成长为规模巨大的会议,并且这些顶级会议的论文录取率接近20%. ICLR上的论文比CVPR上的论文“不成熟”,这并不一定正确。CVPR着重与论文的实验效果要达到“state-of-the-art”,这就意味着你需要将你的算法在标准数据集上测试,并且效果要超过上一赛季领先的算法。ICLR着重的强调的是深度卷积神经网络的新的分析与设计,对于模型的初始化设计,以及从原始数据训练这些模型的训练算法。
Deep Learning is Learning Representations
Yann LeCun and Yoshua Bengio started this conference in 2013 because there was a need to a new, small, high-quality venue with an explicit focus on deep methods. Why is the conference called “Learning Representations?” Because the typical deep neural networks that are trained in an end-to-end fashion actually learn such intermediate representations. Traditional shallow methods are based on manually-engineered features on top of a trainable classifier, but deep methods learn a network of layers which learns those highly-desired features as well as the classifier. So what do you get when you blur the line between features and classifiers? You get representation learning. And this is what Deep Learning is all about.
Yann LeCun与Yoshua Bengio从2013年开始ICLR会议,因为有必要开始一个新的、小范围的、高质量的会议,集中在深度有关的方法上。那为什么这个会议叫做“学习表征(Learning Representation)”呢?因为典型的深度神经网络是以端到端的方式训练,学习到的实际上正是中间表征(intermediate representation)。传统的浅层方法是基于人工设计特征之上的一种可训练的分类器(《机器之心》将其译为:“传统的浅层方法是以可训练分类器之上、人工处理过的特征为基础”),但是深层的方法是一个层级网络,学习到的不仅包括我们渴求的特征,还学习分类器。所以,当特征与分类器之间的界限变得模糊的时候,你得到了什么呢?你得到的是表征学习。而这就是所谓的深度学习。
ICLR Publishing Model: arXiv or bust
At ICLR, papers get posted on arXiv directly. And if you had any doubts that arXiv is just about the single awesomest thing to hit the research publication model since the Gutenberg press, let the success of ICLR be one more data point towards enlightenment. ICLR has essentially bypassed the old-fashioned publishing model where some third party like Elsevier says “you can publish with us and we’ll put our logo on your papers and then charge regular people $30 for each paper they want to read.” Sorry Elsevier, research doesn’t work that way. Most research papers aren’t good enough to be worth $30 for a copy. It is the entire body of academic research that provides true value, for which a single paper just a mere door. You see, Elsevier, if you actually gave the world an exceptional research paper search engine, together with the ability to have 10-20 papers printed on decent quality paper for a $30/month subscription, then you would make a killing on researchers and I would endorse such a subscription. So ICLR, rightfully so, just said fuck it, we’ll use arXiv as the method for disseminating our ideas. All future research conferences should use arXiv to disseminate papers. Anybody can download the papers, see when newer versions with corrections are posted, and they can print their own physical copies. But be warned: Deep Learning moves so fast, that you’ve gotta be hitting refresh or arXiv on a weekly basis or you’ll be schooled by some grad students in Canada.
在ICLR,论文直接在arXiv上发表公布出来。如果你对自从Gutenberg Press(古登堡计划)以来,arXiv已经成为唯一最棒的冲击出版模式的论文发布方法还存有怀疑,那让ICLR的成功再来开悟你吧。ICLR绕过了旧的论文发行模式,如有个第三方机构如Elsevier,现在它对你说“你可以和我们一起发行论文,我们会把我们的logo放在你的论文上,之后收取想看论文的人30美元”。对不起,Elsevier,做研究那样是行不通的。大部分的研究论文不值每份拷贝就收30美元。学术研究的整体才有真正的价值,论文仅仅是一扇门而已。你看,Elsevier,如果你能够提供给大家一个满意的学术论文搜索引擎,同时可以以每月30美元的订阅费提供高质量纸张印刷的论文集,那么你就为研究者提供了一项杀手级的服务,那么我会认可这个订阅。所以理所当然的,ICLR说,去你妹的,我们都用arXiv来传播我们的idea。未来所有的研究会议都应该用arXiv来发布传播论文。任何人可以下载,当论文有更正的时候也可以查看最新的版本,他们也可以自己打印出来。但是请注意,深度学习发展的如此之快,你得每周访问或者刷新arXiv,否则的化,你就会被一些加拿大的研究生教育了。
Attendees of ICLR
Google DeepMind and Facebook’s FAIR constituted a large portion of the attendees. A lot of startups, researchers from the Googleplex, Twitter, NVIDIA, and startups such as Clarifai and Magic Leap. Overall a very young and vibrant crowd, and a very solid representation by super-smart 28-35 year olds.
Google DeepMind团队和Facebook的FAIR实验室团队构成了参会者的大多数。很多来自Googleplex、Twitter以及Nvidia的研究者,以及如Clarifai、Magic Leap的创业公司的研究者。总的来说,这是一个年轻聪明的群体,28-35岁非常聪明的人代表了这个群体的大多数。
Part II: Deep Learning Themes @ ICLR 2016
Incorporating Structure into Deep Learning
Raquel Urtasun from the University of Toronto gave a talk about Incorporating Structure in Deep Learning. See Raquel’s Keynote video here. Many ideas from structure learning and graphical models were presented in her keynote. Raquel’s computer vision focus makes her work stand out, and she additionally showed some recent research snapshots from her upcoming CVPR 2016 work.

来自多伦多大学的Raquel Urtasun发表了有关将结构与深度学习结合的演讲。具体的见这里的 Raquel’s Keynote演讲视频 。许多有关结构学习与图模型的ideas在她的Keynote里都有。Raquel在计算机视觉领域的专注使她脱颖而出,她在ICLR这里也展示了一些她在CVPR2016上的研究内容。
One of Raquel’s strengths is her strong command of geometry, and her work covers both learning-based methods as well as multiple-view geometry. I strongly recommend keeping a close look at her upcoming research ideas. Below are two bleeding edge papers from Raquel’s group – the first one focuses on soccer field localization from a broadcast of such a game using branch and bound inference in a MRF.
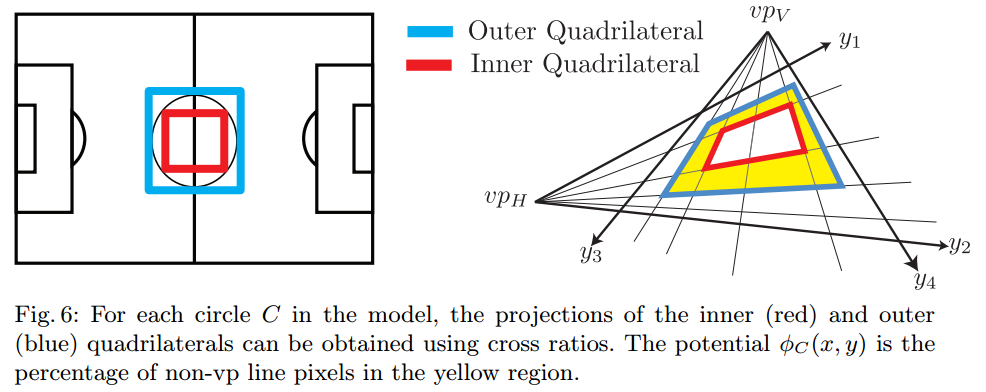
Soccer Field Localization from a Single Image. Namdar Homayounfar, Sanja Fidler, Raquel Urtasun. in arXiv:1604.02715.
Raquel的强项之一就是几何学,她的工作既涵盖了基于学习的方法(learning-based methods),也包含了多视角几何的方法(multiple-view geometry)。我强烈建议要关注研究她将来的ideas。下面是两篇来自 Raquel 组的顶尖论文 —— 第一篇集中于用MRF中的分支界限法进行推论(branch and bound inference),根据球赛广播定位足球场的位置。
The second upcoming paper from Raquel’s group is on using Deep Learning for Dense Optical Flow, in the spirit of FlowNet, which I discussed in my ICCV 2015 hottest papers blog post. The technique is built on the observation that the scene is typically composed of a static background, as well as a relatively small number of traffic participants which move rigidly in 3D. The dense optical flow technique is applied to autonomous driving.
Deep Semantic Matching for Optical Flow, 2016 CVPR. Min Bai, Wenjie Luo, Kaustav Kundu, Raquel Urtasun. In arXiv:1604.01827.
Raquel 组的第二篇即将发表的文章是将深度学习用在密集光流上(Dense Optical Flow),这项工作受启发于 FlowNet,这个 FlowNet,我在我的 ICCV 2015 最火论文展示这篇文章里讨论过。这项技术建立在一个观察事实之上:场景是由一个静态背景以及一些相对背景较小在3维中快速运动的物体组成。密集光流技术(dense optical flow technique)被用在自动驾驶上。
Reinforcement Learning
Sergey Levine gave an excellent Keynote on deep reinforcement learning and its application to Robotics[3]. See Sergey’s Keynote video here. This kind of work is still the future, and there was very little robotics-related research in the main conference. It might not be surprising, because having an assembly of robotic arms is not cheap, and such gear is simply not present in most grad student research labs. Most ICLR work is pure software and some math theory, so a single GPU is all that is needed to start with a typical Deep Learning pipeline.

An army of robot arms jointly learning to grasp somewhere inside Google.
华盛顿大学的Sergey Levine给了一个精彩的有关深度增强学习(deep reinforcement learning)以及其在机器人上的应用的演讲。可以见这里的Sergey Levine的演讲录像。这种类型的工作仍是超前的(still the future),同时在主要会议上关于机器人的研究也非常的少。这并不令人惊讶,因为拥有这样的机器人组装手臂并不便宜,这种装配还没有在研究生实验室出现。大部分 ICLR 上的工作都在软件以及数学理论上,因为一个 GPU 就足够开始一个典型的深度学习工作。
Take a look at the following interesting work which shows what Alex Krizhevsky, the author of the legendary 2012 AlexNet paper which rocked the world of object recognition, is currently doing. And it has to do with Deep Learning for Robotics, currently at Google.
Learning Hand-Eye Coordination for Robotic Grasping with Deep Learning and Large-Scale Data Collection. Sergey Levine, Peter Pastor, Alex Krizhevsky, Deirdre Quillen. In arXiv:1603.02199.
现在看一下 Alex Krizhevsky ,就是在2012年 ImageNet 比赛上,发明 AlexNet,一举震惊了物体检测领域的人。看一下他现在正在做的下面有趣的工作。他正在 Google 做基于深度学习的机器人的工作。
基于深度学习以及大规模数据的用于机器人抓取的手眼协调学习. Sergey Levine, Peter Pastor, Alex Krizhevsky, Deirdre Quillen. In arXiv:1603.02199.
For those of you who want to learn more about Reinforcement Learning, perhaps it is time to check out Andrej Karpathy’s Deep Reinforcement Learning: Pong From Pixels tutorial. One thing is for sure: when it comes to deep reinforcement learning, OpenAI is all-in.
对于那些像更多的了解增强学习的人,是时候去学习 Karpathy 的深度增强学习教程:Pong From Pixels。有一件事可以肯定:当深度增强学习到来之际,OpenAI就全面到来了。
Compressing Networks
While NVIDIA might be today’s king of Deep Learning Hardware, I can’t help the feeling that there is a new player lurking in the shadows. You see, GPU-based mining of bitcoin didn’t last very long once people realized the economic value of owning bitcoins. Bitcoin very quickly transitioned into specialized FPGA hardware for running the underlying bitcoin computations, and the FPGAs of Deep Learning are right around the corner. Will NVIDIA remain the King? I see a fork in NVIDIA’s future. You can continue producing hardware which pleases both gamers and machine learning researchers, or you can specialize. There is a plethora of interesting companies like Nervana Systems, Movidius, and most importantly Google, that don’t want to rely on power-hungry heatboxes known as GPUs, especially when it comes to scaling already trained deep learning models. Just take a look at Fathom by Movidius or the Google TPU.

Model Compression: The WinZip of Neural Nets?
当 NVIDIA 的显卡也许是现今的深度学习硬件王者,我隐约感觉到暗处有一个潜伏的新玩家。你看,当人们意识到拥有比特币的价值,基于 GPU 的比特币挖掘就持续不了了。比特币很快地过渡到专业化的硬件 FPGA(用于运行底层的比特币计算)上,深度学习 FPGA 也近在眼前了。NVIDIA 还会是王者吗?我看到 NVIDIA 面临着抉择,你可以继续生产既满足游戏玩家又满足机器学习研究者的硬件,或者你可以专业化。有许多有趣的公司,如 Nervana Systems,Movidius,以及最重要的 Google,他们不想依赖耗费量巨大的 GPU,特别是当扩展已经训练好的深度学习模型时。可以看一下 Movidius 的 Fathom,或者 Google 的 TPU。
But the world has already seen the economic value of Deep Nets, and the “software” side of deep nets isn’t waiting for the FPGAs of neural nets. The software version of compressing neural networks is a very trendy topic. You basically want to take a beefy neural network and compress it down into smaller, more efficient model. Binarizing the weights is one such strategy. Student-Teacher networks where a smaller network is trained to mimic the larger network are already here. And don’t be surprised if within the next year we’ll see 1MB sized networks performing at the level of Oxford’s VGGNet on the ImageNet 1000-way classification task.
2016 ICLR上 深度网络压缩论文的总结, By Han et al.
但是,产业界已经看到了深度网络的经济价值,同时,深度网络的“软件”这边期望的并不是神经网络的 FPGA 的硬件。将神经网络压缩成软件版本是一个非常热门的话题。你想要将一个健壮的神经网络,将其压缩成更小、更有效率的模型。权重的二值化是一种策略。Student-Teacher 网络将小的网络训练去模仿较大的已经存在的网络。所以如果明年我们看到仅有1MB 大小的网络模型在 ImageNet 1000类分类任务比赛中,其表现效果与 Oxford 的 VGGNet 相当时,不要惊讶。
This year’s ICLR brought a slew of Compression papers, the three which stood out are listed below.
今年 ICLR 上有很多的网络压缩的文章,以下是其中突出的三篇。第一篇赢得了今年 ICLR 的“最佳论文奖”,可以看 Han 的网络压缩的演讲视频。
Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding. Song Han, Huizi Mao, and Bill Dally. In ICLR 2016. This paper won the Best Paper Award. See Han give the Deep Compression talk.
Neural Networks with Few Multiplications. Zhouhan Lin, Matthieu Courbariaux, Roland Memisevic, Yoshua Bengio. In ICLR 2016.
8-Bit Approximations for Parallelism in Deep Learning. Tim Dettmers. In ICLR 2016.
Unsupervised Learning
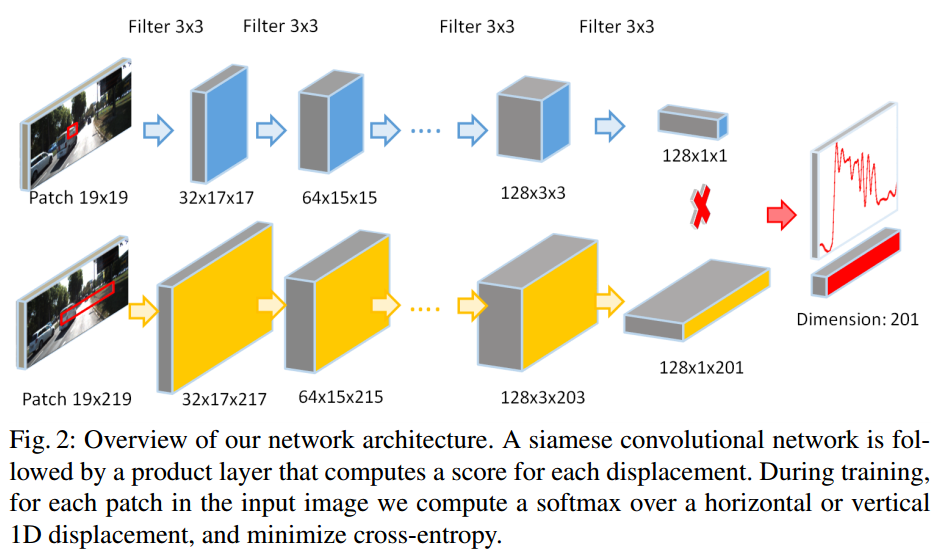
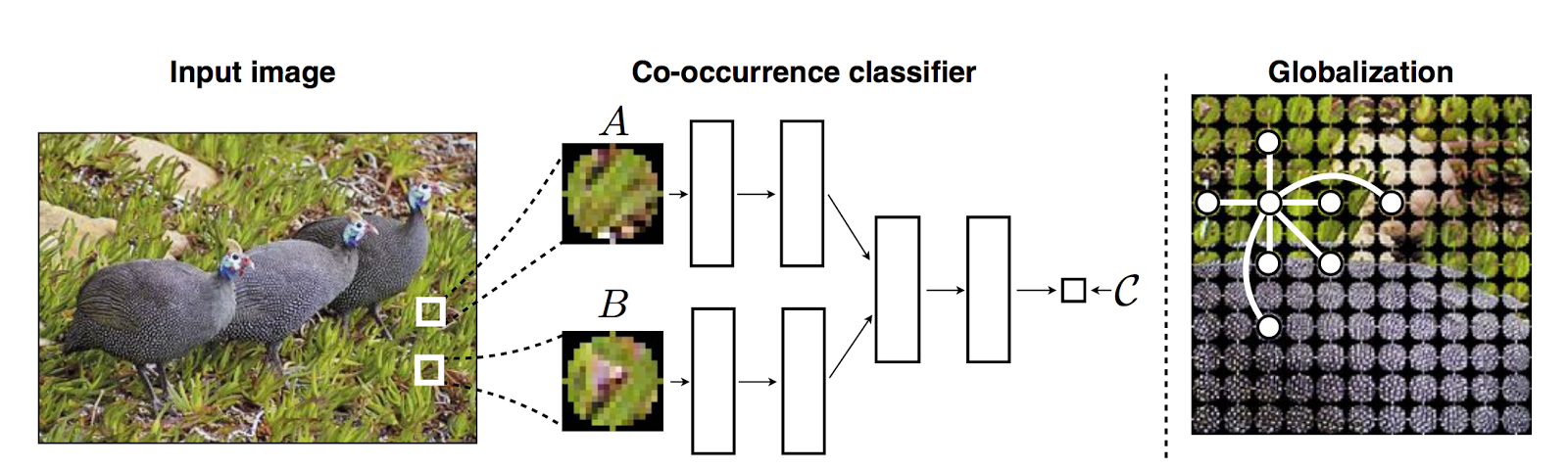
Philip Isola presented a very Efrosian paper on using Siamese Networks defined on patches to learn a patch similarity function in an unsupervised way. This patch-patch similarity function was used to create a local similarity graph defined over an image which can be used to discover the extent of objects. This reminds me of the Object Discovery line of research started by Alyosha Efros and the MIT group, where the basic idea is to abstain from using class labels in learning a similarity function.
Isola et al: A Siamese network has shared weights and can be used for learning embeddings or “similarity functions.”
Isola 等人:Siamese 网络共享权重,可用来学习嵌入或者“相似性函数”
Philip Isola 发表了一篇非常有 Efrosian 风格的论文(Efrosian 为 Efros 星球上的人,该星球为《星际迷航》科幻系列中的星际联邦中 ,Flarset 系统的第四个行星),以一种非监督学习的方式用基于局部定义的 Siamese Network,学习局部相似性函数。这种局部与局部相似性函数,用于基于整张图像创建局部相似性图(a local similarity graph),这个相似性图可以用来发现物体的大小(the extent of object)。这使我想起了由 Alyosha Efros 和 MIT 团队开始的 对象发现(Object Discovery)的系列研究,其中基本的思想就是在相似性函数的学习中避免使用标签。
Learning visual groups from co-occurrences in space and time, Phillip Isola, Daniel Zoran, Dilip Krishnan, Edward H. Adelson. In ICLR 2016.

Isola et al: Visual groupings applied to image patches, frames of a video, and a large scene dataset.
局部图像的可视化聚合,视频的帧,以及大规模场景数据库
Initializing Networks: And why BatchNorm matters
Getting a neural network up and running is more difficult than it seems. Several papers in ICLR 2016 suggested new ways of initializing networks. But practically speaking, deep net initialization is “essentially solved.” Initialization seems to be an area of research that truly became more of a “science” than an “art” once researchers introduced BatchNorm into their neural networks. BatchNorm is the butter of Deep Learning – add it to everything and everything will taste better. But this wasn’t always the case!
设计一个神经网络并运行起来,并不容易。ICLR 2016上有几篇文章介绍了新的网络初始化的方法。但是实际上来说,深度网络的初始化问题已经“基本解决”了。自从研究者将 BatchNorm 引入到神经网络后,初始化问题才真正成为更加科学、而非只是具有艺术价值的研究领域。BatchNorm 是深度学习的黄油 —— 哪里挤上一点,哪里就会变得更“美味”,但事实并不总这样!
In the early days, researchers had lots of problems with constructing an initial set of weights of a deep neural network such that the back propagation could learn anything. In fact, one of the reasons why the Neural Networks of the 90s died as a research program, is precisely because it was well-known that a handful of top researchers knew how to tune their networks so that they could start automatically learning from data, but the other research didn’t know all of the right initialization tricks. It was as if the “black magic” inside the 90s NNs was just too intense. At some point, convex methods and kernel SVMs because the tools of choice — with no need to initialize in a convex optimization setting, for almost a decade (1995 to 2005) researchers just ran away from deep methods. Once 2006 hit, Deep Architectures were working again with Hinton’s magical deep Boltzmann Machines and unsupervised pretraining. Unsupervised pretaining didn’t last long, as researchers got GPUs and found that once your data set is large enough (think ~2 million images in ImageNet), that simple discriminative back-propagation does work. Random weight initialization strategies and cleverly tuned learning rates were quickly shared amongst researchers once 100s of them jumped on the ImageNet dataset. People started sharing code, and wonderful things happened!
在早些时候,研究者为了使得反向传播算法能够学习一切,在深度神经网络权重的初始化上有许多问题要面对。事实上,神经网络在90年代“死去”的原因之一就是,只有少数的几个知名的顶尖科学家知道如何去调节他们网络的权值,之后网络就可以从数据集中学习,但是其他的研究者并不知道所有的网络初始化技巧。在90年代的神经网络里,初始化就好像“黑魔法”,它是如此的重要、强大。在某一个时间点,人们选择使用凸方法和 Kernel SVMs,因为这不需要在凸优化设置中进行初始化,于是有近10年的时间,研究者抛弃了深度网络的方法。但是在2006年,深度结构取得突破, Hinton 的 深度玻尔兹曼机(deep Boltzmann Machine)以及 无监督预训练(unsupervised pretraining)再次使得深度结构发挥了作用。无监督预训练并没有持续太长的时间,因为研究者有了 GPU,他们发现,一旦你的数据集足够大(如 ImageNet 图像数据集就大约有 2,000,000 张图片),那么简单的 基于判别学习的反向传播算法就可以运行。当转向 ImageNet 数据集的研究者有100多个的时候,权重随机初始化策略,智能的学习率调节,这些方法快速的在他们中传播开来。人们开始分享代码,奇迹随之发生!
But designing new neural networks for new problems was still problematic – one wouldn’t know exactly the best way to set multiple learning rates and random initialization magnitudes. But researchers got to work, and a handful of solid hackers from Google found out that the key problem was that poorly initialized networks were having a hard time flowing information through the networks. It’s as if layer N was producing activations in one range and the subsequent layers were expecting information to be of another order of magnitude. So Szegedy and Ioffe from Google proposed a simple “trick” to whiten the flow of data as it passes through the network. Their trick, called “BatchNorm” involves using a normalization layer after each convolutional and/or fully-connected layer in a deep network. This normalization layer whitens the data by subtracting a mean and dividing by a standard deviation, thus producing roughly gaussian numbers as information flows through the network. So simple, yet so sweet. The idea of whitening data is so prevalent in all of machine learning, that it’s silly that it took deep learning researchers so long to re-discover the trick in the context of deep nets.
但是针对新的问题设计新的神经网络仍是个问题 —— 我们并不知道如何较好地设置学习率以及随机初始化值。但是不管怎样,研究者得坚持研究,来自 Google 许多极客发现了问题的关键,初始化较差的神经网络很难在网络间进行信息的流通(这里所谓的“信息”就是梯度)。例如,第 N 层产生了一定范围内的激活值,而这个层随后的其他层却期望另一个数量级的信息。所以 Google 的 Szegedy 和 Ioffe提出了一个简单的技巧,即在数据在数据通过网络的时候,将数据进行“漂白”。他们的这个技巧,叫做“BatchNorm(Batch Normalization)”,即在深度网络中的每一个卷积层或者全连接层之后加上一个 归一化层(a normalization layer)。这种归一化层的操作就是,先减去数据的平均值,再除以数据的标准差,这样当信息在网络间流通的时候,会输出近似高斯分布的结果。事半而功倍(so simple, so sweet)。机器学习中,这种数据“漂白”的方法十分的流行,但是深度学习研究者花了这么长时间,重新在深度网络的研究历史中发掘出这个技巧,似乎有些大费周折。
Data-dependent Initializations of Convolutional Neural Networks, Philipp Krähenbühl, Carl Doersch, Jeff Donahue, Trevor Darrell, ICLR 2016. Carl Doersch, a fellow CMU PhD, is going to DeepMind, so there goes another point for DeepMind.
Data-dependent Initializations of Convolutional Neural Networks, Philipp Krähenbühl, Carl Doersch, Jeff Donahue, Trevor Darrell.
Carl Doersch 是 CMU 的博士研究员,加入了 DeepMind,他将在那儿有所作为。
Backprop Tricks
Injecting noise into the gradient seems to work. And this reminds me of the common grad student dilemma where you fix a bug in your gradient calculation, and your learning algorithm does worse. You see, when you were computing the derivative on the white board, you probably made a silly mistake like messing up a coefficient that balances two terms or forgetting an additive / multiplicative term somewhere. However, with a high probability, your “buggy gradient” was actually correlated with the true “gradient”. And in many scenarios, a quantity correlated with the true gradient is better than the true gradient. It is a certain form of regularization that hasn’t been adequately addressed in the research community. What kinds of “buggy gradients” are actually good for learning? And is there a space of “buggy gradients” that are cheaper to compute than “true gradients”? These “FastGrad” methods could speed up training deep networks, at least for the first several epochs. Maybe by ICLR 2017 somebody will decide to pursue this research track.
Adding Gradient Noise Improves Learning for Very Deep Networks. Arvind Neelakantan, Luke Vilnis, Quoc V. Le, Ilya Sutskever, Lukasz Kaiser, Karol Kurach, James Martens. In ICLR 2016.
Robust Convolutional Neural Networks under Adversarial Noise. Jonghoon Jin, Aysegul Dundar, Eugenio Culurciello. In ICLR 2016.
在梯度中加入噪声,似乎挺有效果。这让我想起一般研究生遇到的困境,当你修复了梯度计算中的一个 bug,你的学习算法却表现的更糟。你可以想象,当你用一个白板求导数时,你可能会犯一些愚蠢的小错误,如搞混了平衡两个项的系数,或者在哪个地方忘记
+、×
某个项。但是,有很高的可能性,你的“有漏洞的梯度”与真实的“梯度”是相关的。同时在许多场景下, 一个与真实梯度相关的数量比真实的梯度要好。这是尚未在科研界得到解决的规则化(regularization)的一种特定形式。哪一种“有漏洞的梯度”对学习是有实际好处的?是否有这样一个空间,使得“有漏洞的梯度”计算代价要比“真实的梯度”要小?这些“快速计算梯度”的方法可以加速训练神经网络,至少在前几个时期(epochs)是这样。可能在 ICLR 2017 年会议上会有人决定去从事这个研究。
Attention: Focusing Computations
Attention-based methods are all about treating different “interesting” areas with more care than the “boring” areas. Not all pixels are equal, and people are able to quickly focus on the interesting bits of a static picture. ICLR 2016’s most interesting “attention” paper was the Dynamic Capacity Networks paper from Aaron Courville’s group at the University of Montreal. Hugo Larochelle, another key researcher with strong ties to the Deep Learning mafia, is now a Research Scientist at Twitter.
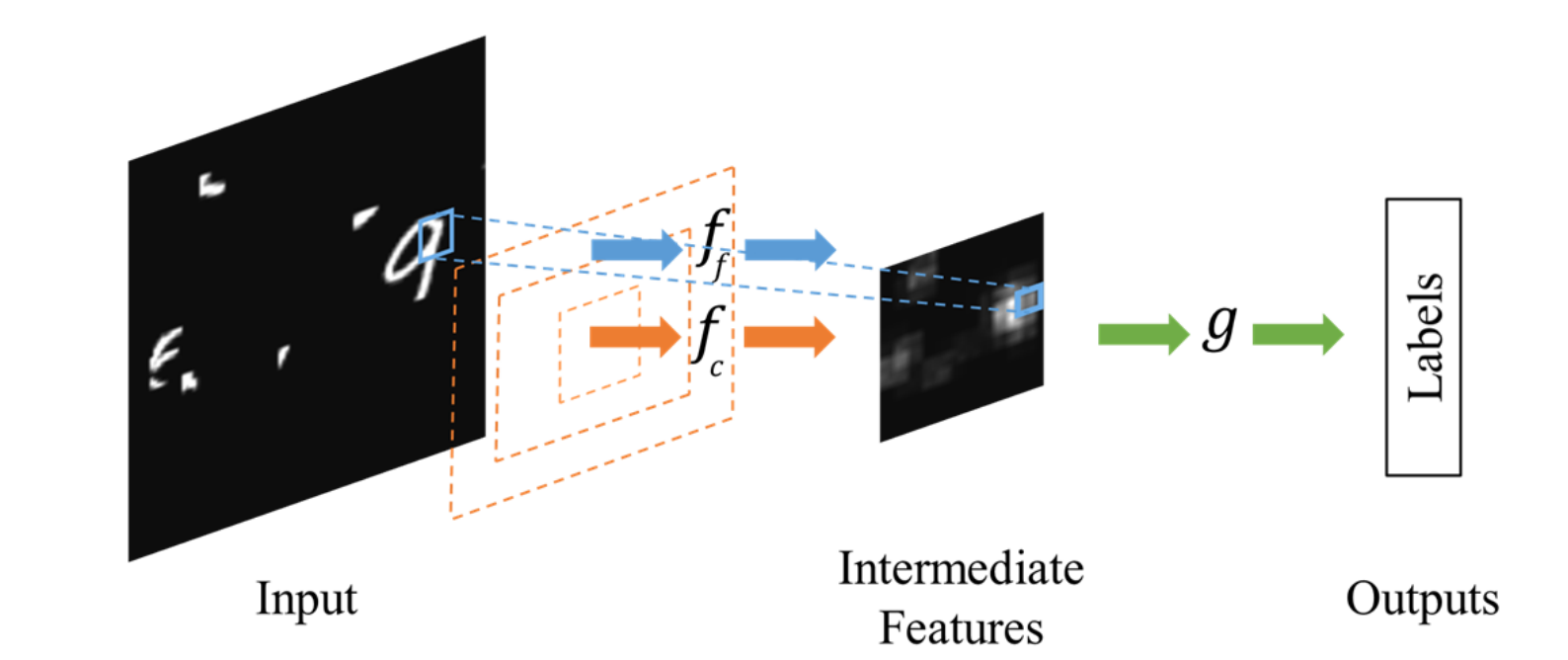
Dynamic Capacity Networks. Amjad Almahairi, Nicolas Ballas, Tim Cooijmans, Yin Zheng, Hugo Larochelle, Aaron Courville. In ICLR 2016.
Attention: 聚焦计算(这里以及下面的Attention我不知道如何翻译,故用原文,意思还能更准确点)
基于 Attention 的方法是,相比较于“不感兴趣”的区域,将更多的注意力放在不同的“感兴趣”区域上。图像中并不是所有的像素都是同等重要的,人们可以很快的将注意力集中在感兴趣的地方。ICLR 2016 中,有关 Attention 方法的论文中,最有意思的一篇文章是 《Dynamic Capacity Network》,来自于 Montreal 大学的 Aaron Courville 团队。Hugo Larochelle 是“深度学习黑手党”的另一个关键研究员,他现在在 Twitter 做研究科学家。
The “ResNet trick”: Going Mega Deep because it’s Mega Fun
We saw some new papers on the new “ResNet” trick which emerged within the last few months in the Deep Learning Community. The ResNet trick is the “Residual Net” trick that gives us a rule for creating a deep stack of layers. Because each residual layer essentially learns to either pass the raw data through or mix in some combination of a non-linear transformation, the flow of information is much smoother. This “control of flow” that comes with residual blocks, lets you build VGG-style networks that are quite deep.
Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning. Christian Szegedy, Sergey Ioffe, Vincent Vanhoucke. In ICLR 2016.
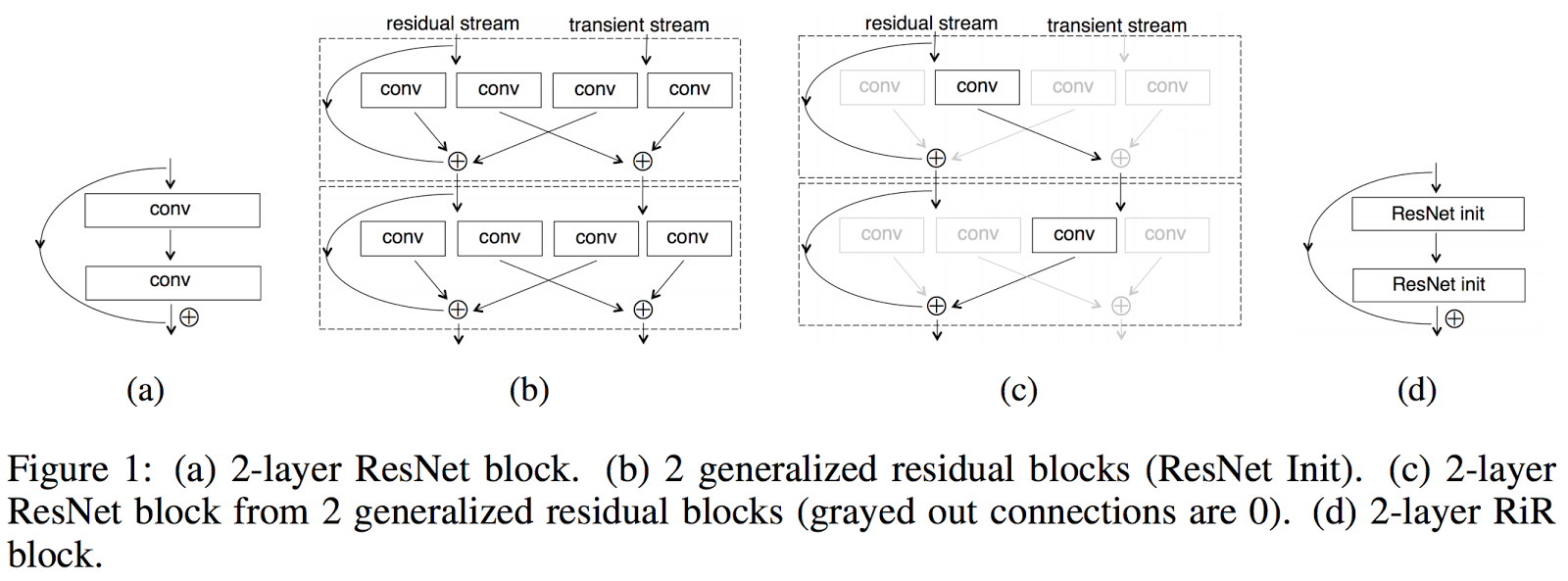
Resnet in Resnet: Generalizing Residual Architectures. Sasha Targ, Diogo Almeida, Kevin Lyman. In ICLR 2016.
“残差网络技巧”:构建更深的网络,更加的有趣
前几个月,在深度学习领域,出现了几篇新的“残差网络”技巧的文章。ResNet 是指“残差网络(Residual Net)”,这种方法能够为我们创建更深的网络堆层提供一种规则。因为每一个残差层基本上是学习要么让原始数据通过,要么学习将一些非线性变换结合的方式来混合原始数据,所以这些层中信息的流通会更顺畅。这种由残差模块(residual blocks)带来的“流控制(control of flow)”,可以让你构建 VGG 那种很深的网络。
Deep Metric Learning and Learning Subcategories
A great paper, presented by Manohar Paluri of Facebook, focused on a new way to think about deep metric learning. The paper is “Metric Learning with Adaptive Density Discrimination” and reminds me of my own research from CMU. Their key idea can be distilled to the “anti-category” argument. Basically, you build into your algorithm the intuition that not all elements of a category C1 should collapse into a single unique representation. Due to the visual variety within a category, you only make the assumption that an element X of category C is going to be similar to a subset of other Cs, and not all of them. In their paper, they make the assumption that all members of category C belong to a set of latent subcategories, and EM-like learning alternates between finding subcategory assignments and updating the distance metric. During my PhD, we took this idea even further and build Exemplar-SVMs which were the smallest possible subcategories with a single positive “exemplar” member.
注:这部分完全没有看懂……基本直译,有些直译都看不了的,我就参照了“机器之心”翻译的……
深度度量学习(Deep Metric Learning)、子类的学习
由 Facebook 的 Manohar Paluri 发表的一篇很棒的论文,关注了一种思考深度度量学习的新方法。论文的标题为 《Metric Learning with Adaptive Density Discrimination(自适应密度判别的度量学习)》,他们的关键想法可以总结归纳为“反类(anti-category)”的观点。基本上,你设计你的算法时,直觉上,一个类别 C1 中不是所有的元素都要塌缩成一个单一的表征。由于一个类别中视觉的多样性,你只可以假设 C 类中的一个元素 X 与其他 C 类的子类中元素类似,并且并非所有元素都是如此。在他们的论文中,他们假设 C 类中的所有成员都属于一个隐藏的子类的集合,例如 EM 的学习算法在寻找子类分配和更新距离度量之间交替。在我读博期间,我们将这个想法推进的更远,并构建了模范支持向量机,它带有单个积极“模范(exemplar)”元素的最小可能子类。
Manohar started his research as a member of the FAIR team, which focuses more on R&D work, but metric learning ideas are very product-focused, and the paper is a great example of a technology that seems to be “product-ready.” I envision dozens of Facebook products that can benefit from such data-derived adaptive deep distance metrics.

Metric Learning with Adaptive Density Discrimination. Oren Rippel, Manohar Paluri, Piotr Dollar, Lubomir Bourdev. In ICLR 2016.
Manohar 作为 FAIR 中的一员开始了他的研究,FAIR更专注于研发类的工作,但是度量学习是非常以产品为中心的,同时这篇论文也是“为产品做好准备”的技术的极佳示例。我想,会有数十种 Facebook 的产品可以从这样的数据驱动的自适应深度距离度量中受益。
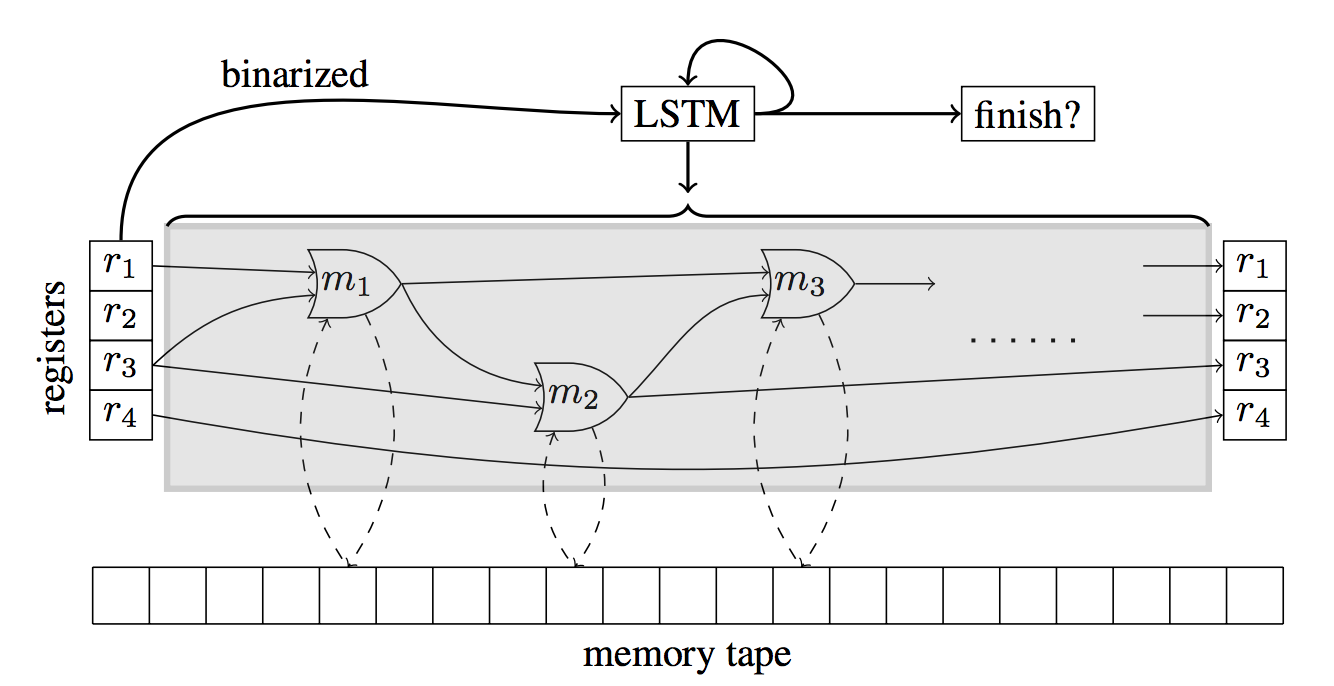
Deep Learning Calculators
LSTMs, Deep Neural Turing Machines, and what I call “Deep Learning Calculators” were big at the conference. Some people say, “Just because you can use deep learning to build a calculator, it doesn’t mean you should.” And for some people, Deep Learning is the Holy-Grail-Titan-Power-Hammer, and everything that can be described with words should be built using deep learning components. Nevertheless, it’s an exciting time for Deep Turing Machines.
长短期记忆人工神经网络(LSTM),深度神经图灵机(Deep Neural Turing Machines),以及我称之为“深度学习计算器(Deep Learning Calculators)”这三样是会议中的大头。一些人说,“仅仅是因为你可以使用深度学习来构建一个计算器,并不意味着你应该这么做。”同时对于一些人而言,深度学习是圣杯+泰坦之锤,任何可以用语言表述的都可以用构成深度学习组件构建出来。虽然如此,这是深度图灵机的激动人心的时刻。
The winner of the Best Paper Award was the paper, Neural Programmer-Interpreters by Scott Reed and Nando de Freitas. An interesting way to blend deep learning with the theory of computation. If you’re wondering what it would look like to use Deep Learning to learn quicksort, then check out their paper. And it seems like Scott Reed is going to Google DeepMind, so you can tell where they’re placing their bets.
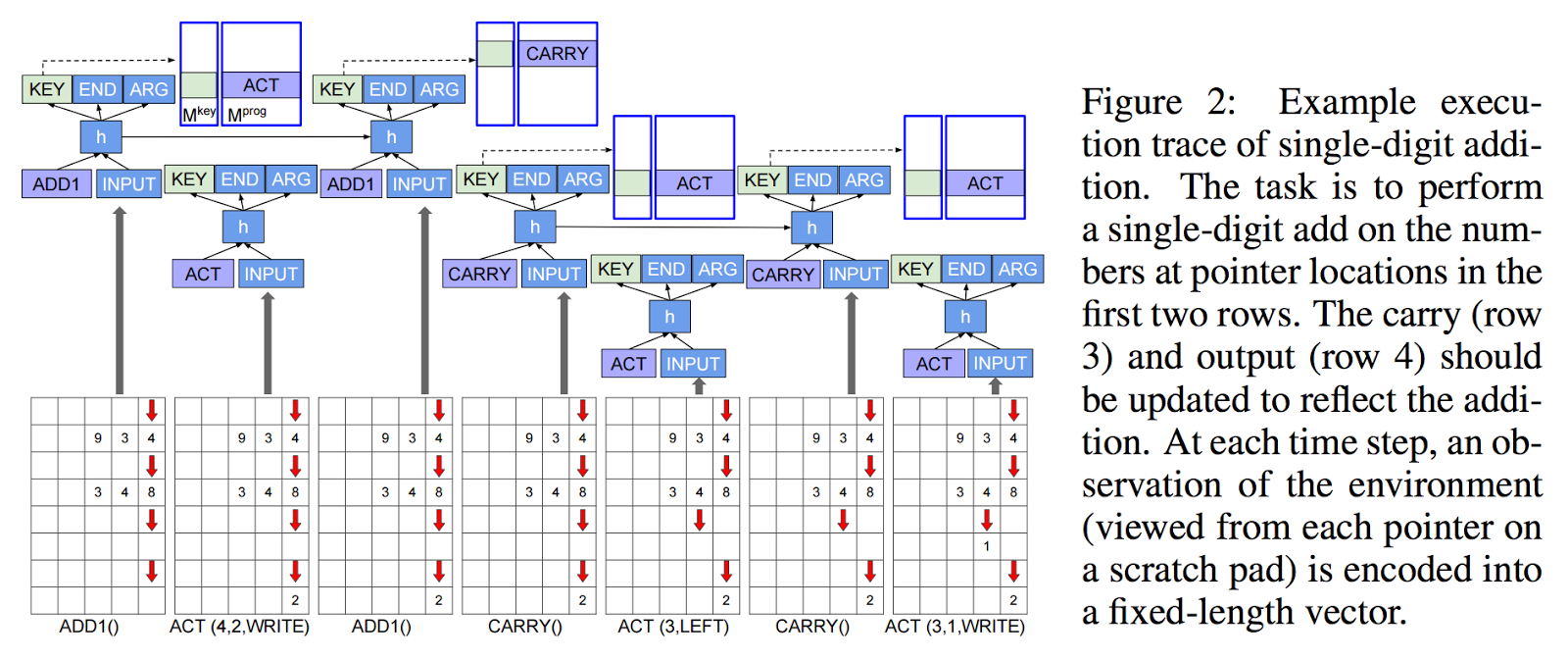
Neural Programmer-Interpreters. Scott Reed, Nando de Freitas. In ICLR 2016.
获得最佳论文奖的是, Scott Reed and Nando de Freitas 的论文:《Neural Programmer-Interpreters》。将深度学习与计算理论进行融合的一种方法。如果你想知道将深度学习用于学习快速排序会是什么样子,那就去看看他们的这篇论文。好像 Scott Reed 打算去 Google 的 DeepMind 组了,你可以看出他们正在押注哪些方面。
这篇论文:Neural Programmer-Interpreters. Scott Reed, Nando de Freitas. In ICLR 2016.
Another interesting paper by some OpenAI guys is “Neural Random-Access Machines” which is going to be another fan favorite for those who love Deep Learning Calculators.
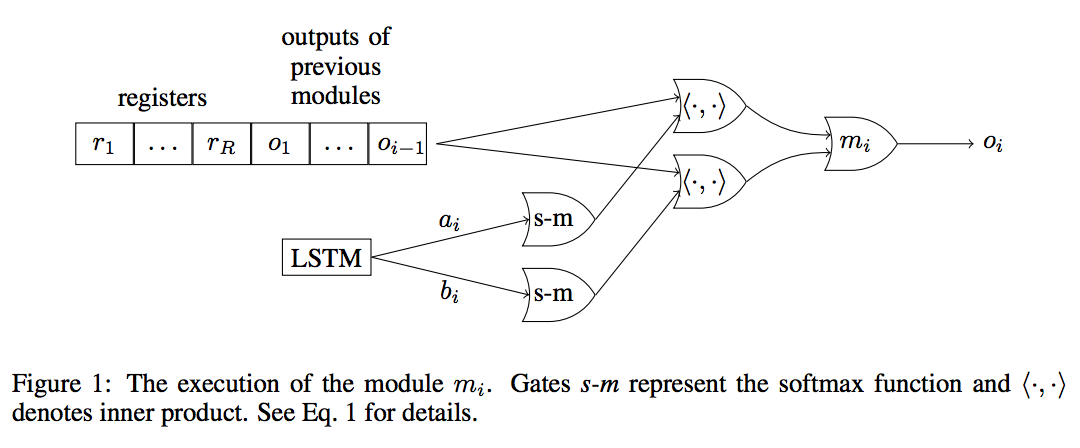
Neural Random-Access Machines. Karol Kurach, Marcin Andrychowicz, Ilya Sutskever. In ICLR 2016.
由 OpenAI 的小伙伴写的另一篇有趣的文章叫做《Neural Random-Access Machines》(《神经随机存取机》),也是那些喜欢深度学习计算器的人的最爱。
“神经随机存取机”论文:Neural Random-Access Machines. Karol Kurach, Marcin Andrychowicz, Ilya Sutskever. In ICLR 2016.
Computer Vision Applications
Boundary detection is a common computer vision task, where the goal is to predict boundaries between objects. CV folks have been using image pyramids, or multi-level processing, for quite some time. Check out the following Deep Boundary paper which aggregates information across multiple spatial resolutions.
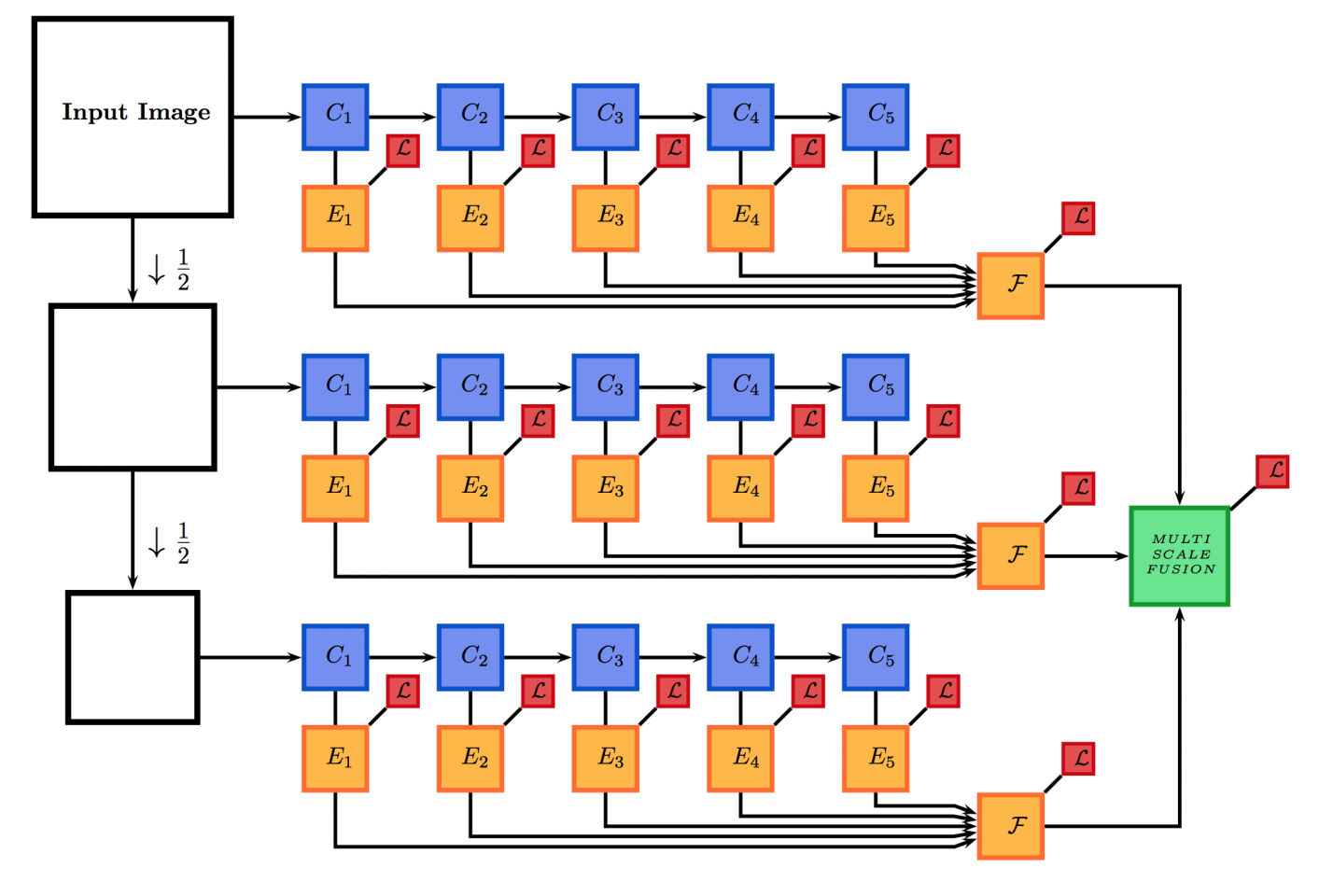
Pushing the Boundaries of Boundary Detection using Deep Learning. Iasonas Kokkinos, In ICLR 2016.
这一块介绍深度学习在计算机视觉中的应用。
边界检测是计算机视觉中的常见任务,它的目的是预测物体之间的边界。计算机视觉研究者已经用图像金字塔、多级处理这类方法很长时间了。看看下面的深度边界检测论文,用多重空间分辨率进行信息的集成。
Pushing the Boundaries of Boundary Detection using Deep Learning. Iasonas Kokkinos, In ICLR 2016.
A great application for RNNs is to “unfold” an image into multiple layers. In the context of object detection, the goal is to decompose an image into its parts. The following figure explains it best, but if you’ve been wondering where to use RNNs in your computer vision pipeline, check out their paper.
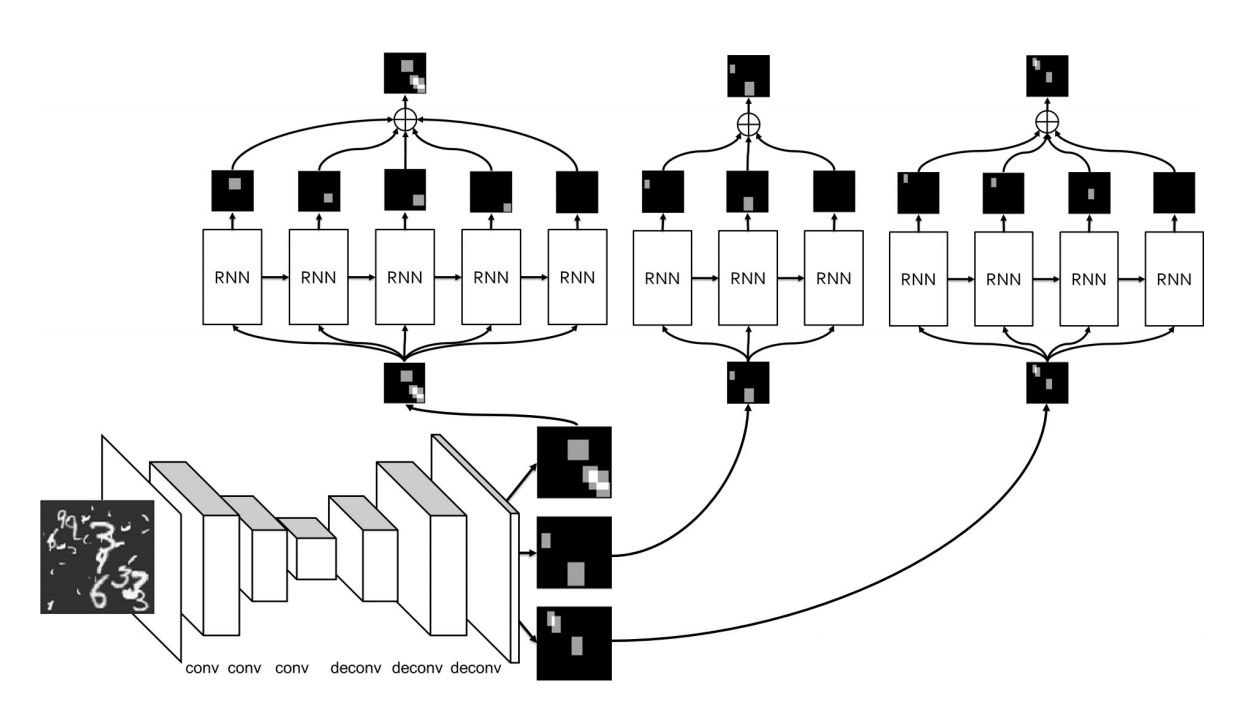
Learning to decompose for object detection and instance segmentation. Eunbyung Park, Alexander C. Berg. In ICLR 2016.
RNN 网络的一个重要的应用就是将一张图像“展开”成多层。在物体检测中,我们的目标是将图像分解成许多的部分。下面的图解释的很好,如果你想知道在你的计算机视觉流程中哪里该用 RNN,去看这篇论文吧。
Dilated convolutions are a “trick” which allows you to increase your network’s receptive field size and scene segmentation is one of the best application domains for such dilations.
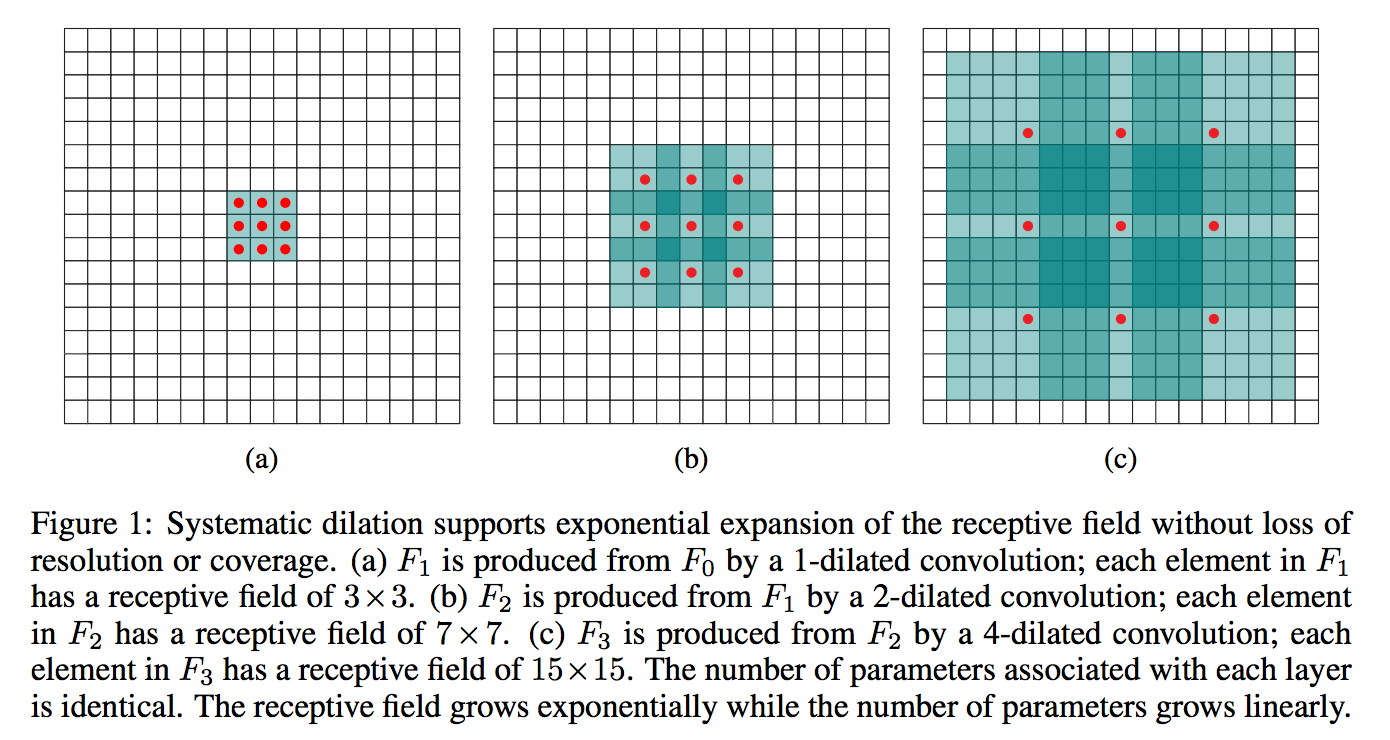
Multi-Scale Context Aggregation by Dilated Convolutions Fisher Yu, Vladlen Koltun. In ICLR 2016.
“膨胀卷积(dilated convolution)”这个技巧,可以使你增加你网络中的感受野(receptive field)的大小,场景分割是这种“膨胀”技巧最好的利用领域之一。
膨胀卷积的论文:Multi-Scale Context Aggregation by Dilated Convolutions Fisher Yu, Vladlen Koltun. In ICLR 2016.
Visualizing Networks
Two of the best “visualization” papers were “Do Neural Networks Learn the same thing?” by Jason Yosinski (now going to Geometric Intelligence, Inc.) and “Visualizing and Understanding Recurrent Networks” presented by Andrej Karpathy (now going to OpenAI). Yosinski presented his work on studying what happens when you learn two different networks using different initializations. Do the nets learn the same thing? I remember a great conversation with Jason about figuring out if the neurons in network A can be represented as linear combinations of network B, and his visualizations helped make the case. Andrej’s visualizations of recurrent networks are best consumed in presentation/blog form[2]. For those of you that haven’t yet seen Andrej’s analysis of Recurrent Nets on Hacker News, check it out here.

Convergent Learning: Do different neural networks learn the same representations? Yixuan Li, Jason Yosinski, Jeff Clune, Hod Lipson, John Hopcroft. In ICLR 2016. See Yosinski’s video here.
有两篇“可视化”的论文,一篇是 Jason Yosinski (现在去了 Geometric Intelligence 公司)的 “Do Neural Networks Learn the same thing?” 另一篇是 Andrej Karpathy (现在去了 OpenAI )的 “Visualizing and Understanding Recurrent Networks”. Yosinski 展示了他研究的当用不同的初始化值对两个不同的网络进行学习,会发生什么现象。这些网络会学到相同的东西吗?我想起来我曾和 Jason 有过一次谈话,对于网络 A 中的神经元能否由网络 B 的线性组合来表示,Jason 的可视化研究帮主我们解决了这个问题。Andrej 对 RNN 的可视化在presentation或者blog的形式下更形象生动可前往blog看看。对于那些还没有见过 Andrej 对递归网络在 Hacker News 上的分析的人,请看这里。
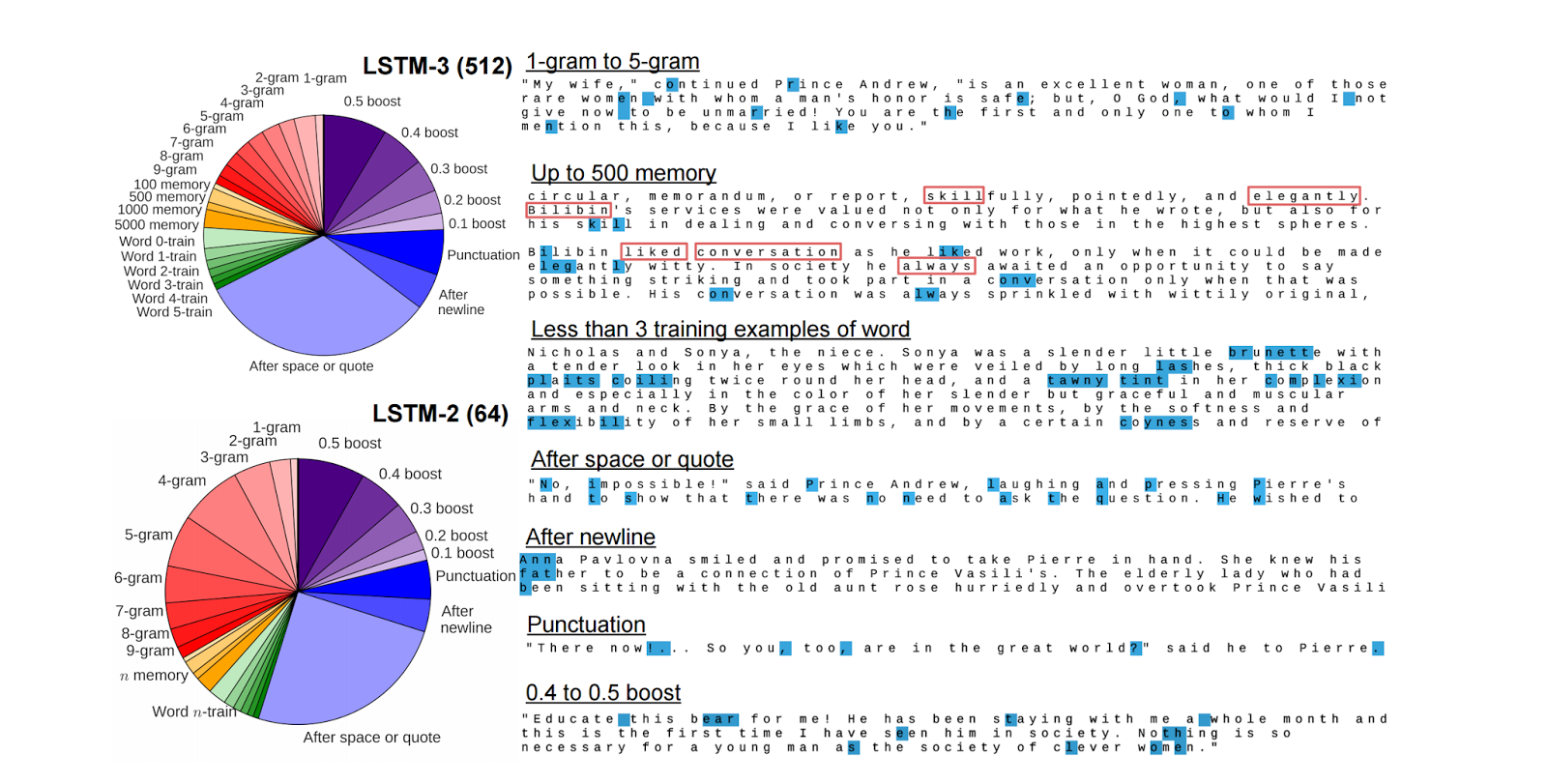
Visualizing and Understanding Recurrent Networks. Andrej Karpathy, Justin Johnson, Li Fei-Fei. In ICLR 2016.
Do Deep Convolutional Nets Really Need to be Deep (Or Even Convolutional)?
This was the key question asked in the paper presented by Rich Caruana. (Dr. Caruana is now at Microsoft, but I remember meeting him at Cornell eleven years ago) Their papers’ two key results which are quite meaningful if you sit back and think about them. First, there is something truly special about convolutional layers that when applied to images, they are significantly better than using solely fully connected layers – there’s something about the 2D structure of images and the 2D structures of filters that makes convolutional layers get a lot of value out of their parameters. Secondly, we now have teacher-student training algorithms which you can use to have a shallower network “mimic” the teacher’s responses on a large dataset. These shallower networks are able to learn much better using a teacher and in fact, such shallow networks produce inferior results when the are trained on the teacher’s training set. So it seems you get go [Data to MegaDeep], and [MegaDeep to MiniDeep], but you cannot directly go from [Data to MiniDeep].
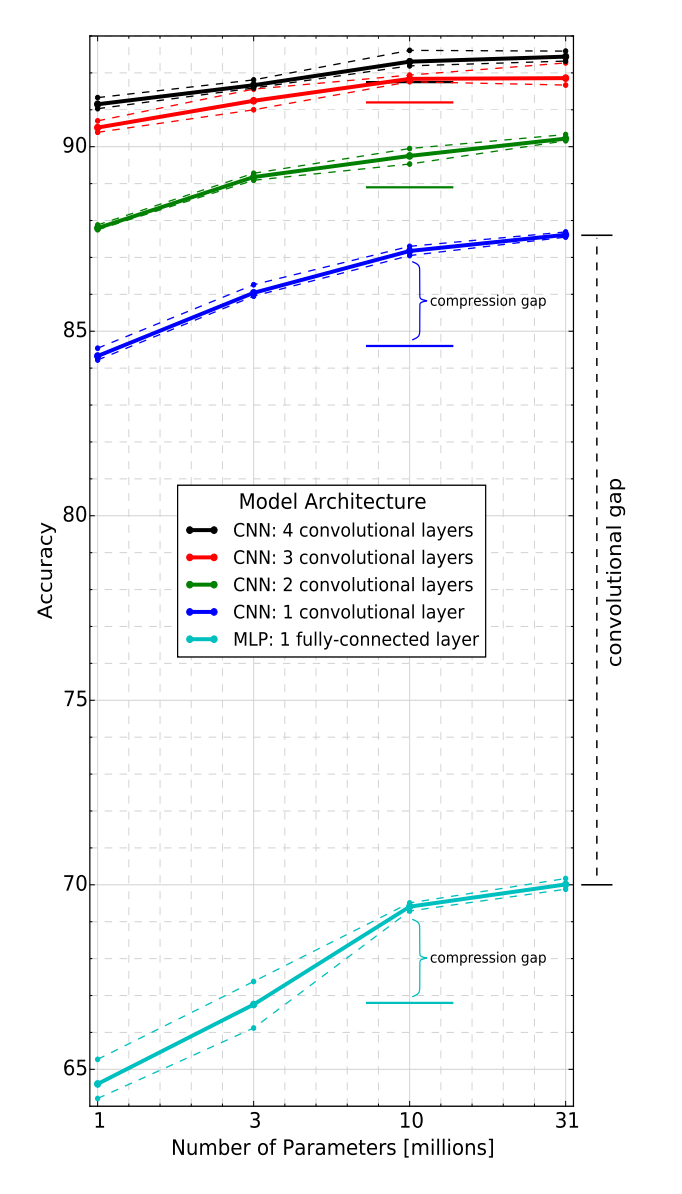
Do Deep Convolutional Nets Really Need to be Deep (Or Even Convolutional)?. Gregor Urban, Krzysztof J. Geras, Samira Ebrahimi Kahou, Ozlem Aslan, Shengjie Wang, Rich Caruana, Abdelrahman Mohamed, Matthai Philipose, Matt Richardson. In ICLR 2016.
这是由Rich Caruana 博士的论文提出的一个关键问题(Caruana 博士现在在 Microsoft了,我记得11年前在 Cornell 见过他) 。如果你坐下来好好想象,就会发现他们论文中的两个重要结果是非常有意义的。首先,处理图像时,卷积层是有其特殊之处的,他们明显好处单独只用全连接层 —— 图像的二维结构以及过滤器(filters)的二维结构,使得卷积层从参数中得到大量的结果。第二点,我们现在已经有了 “teacher-student” 类型的训练算法,可以使用浅层的网络去 “模仿” “老师”在大规模数据集上的反应效果。这些浅层的网络在使用一个“teacher”时,可以学习到更好的效果,事实上,当你用训练“teacher”的数据集用于训练这个浅层的网络,效果会很差。所以,你可以从“数据到深层网络”,以及可以从“深层网络到浅层网络”,但你不能直接从“数据到浅层网络”。
上面的这篇论文:Do Deep Convolutional Nets Really Need to be Deep (Or Even Convolutional)?. Gregor Urban, Krzysztof J. Geras, Samira Ebrahimi Kahou, Ozlem Aslan, Shengjie Wang, Rich Caruana, Abdelrahman Mohamed, Matthai Philipose, Matt Richardson. In ICLR 2016.
Another interesting idea on the [MegaDeep to MiniDeep] and [MiniDeep to MegaDeep] front,
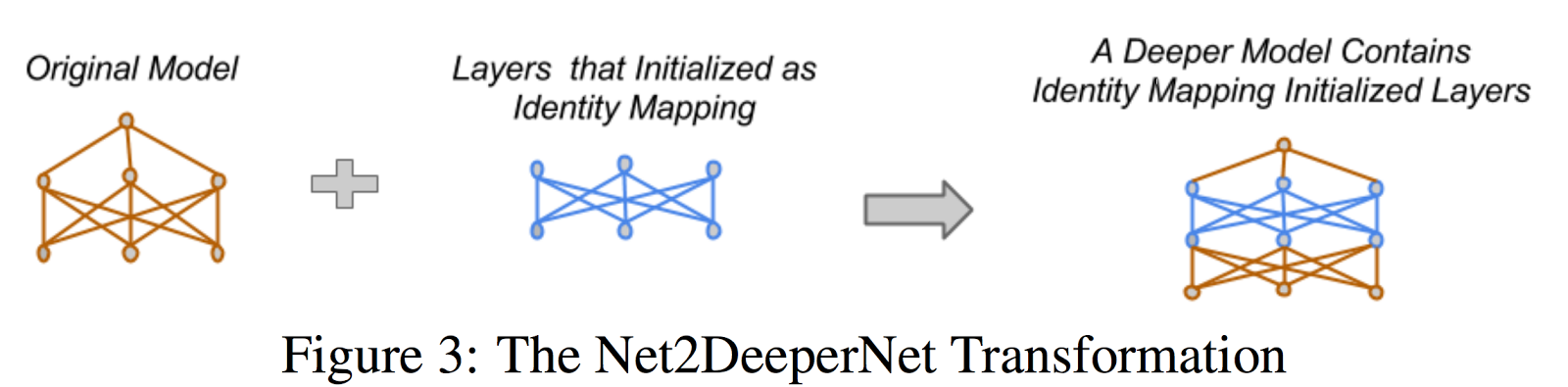
Net2Net: Accelerating Learning via Knowledge Transfer. Tianqi Chen, Ian Goodfellow, Jonathon Shlens. In ICLR 2016.
另一篇论文,其中的想法是从“深层网络到浅层网络”,以及“从浅层网络到深层网络”:
论文:Net2Net: Accelerating Learning via Knowledge Transfer. Tianqi Chen, Ian Goodfellow, Jonathon Shlens. In ICLR 2016.
Language Modeling with LSTMs(略过)
Training-Free Methods: Brain-dead applications of CNNs to Image Matching
These techniques use the activation maps of deep neural networks trained on an ImageNet classification task for other important computer vision tasks. These techniques employ clever ways of matching image regions and from the following ICLR paper, are applied to smart image retrieval.

Particular object retrieval with integral max-pooling of CNN activations. Giorgos Tolias, Ronan Sicre, Hervé Jégou. In ICLR 2016.
这些技术可以将训练在 ImageNet 分类任务上的神经网络激活图,用在其他计算机视觉任务。这些技术能够巧妙的匹配图像区域,从下面的 ICLR 的论文,是将这些技术用在图像检索上。
论文:Particular object retrieval with integral max-pooling of CNN activations. Giorgos Tolias, Ronan Sicre, Hervé Jégou. In ICLR 2016.
This reminds me of the RSS 2015 paper which uses ConvNets to match landmarks for a relocalization-like SLAM task.

Place Recognition with ConvNet Landmarks: Viewpoint-Robust, Condition-Robust, Training-Free. Niko Sunderhauf, Sareh Shirazi, Adam Jacobson, Feras Dayoub, Edward Pepperell, Ben Upcroft, and Michael Milford. In RSS 2015.
下面的论文使我想起了 RSS 2015年的一篇论文,它使用了卷积网络来匹配地标,以完成同时定位与地图创建任务。
RSS 2015年的论文:Place Recognition with ConvNet Landmarks: Viewpoint-Robust, Condition-Robust, Training-Free. Niko Sunderhauf, Sareh Shirazi, Adam Jacobson, Feras Dayoub, Edward Pepperell, Ben Upcroft, and Michael Milford. In RSS 2015.
Gaussian Processes and Auto Encoders
Gaussian Processes used to be quite popular at NIPS, sometimes used for vision problems, but mostly “forgotten” in the era of Deep Learning. VAEs or Variational Auto Encoders used to be much more popular when pertaining was the only way to train deep neural nets. However, with new techniques like adversarial networks, people keep revisiting Auto Encoders, because we still “hope” that something as simple as an encoder / decoder network should give us the unsupervised learning power we all seek, deep down inside. VAEs got quite a lot of action but didn’t make the cut for today’s blog post.
这里讲 高斯过程 以及 自动编码
高斯过程曾在 NIPS 上十分流行,有时候也用于视觉问题,但是在深度学习时代,几乎被遗忘了。当 pertaining 还是训练深度神经网络的唯一方法时(我感觉这里作者打错字了,是不是“pretraining”?),可变化自动编码器(VAEs, Variational Auto Encoders)更加的流行。但是,随着诸如对抗网络(adversarial networks)这类新技术的到来,人们频繁的使用自动编码器,因为我们仍然希望着有如编码器/解码器这样简单的网络,能够给予我们无监督学习的能力。人们对 VAE 进行了许多尝试,但是到今天都没有过关。
Geometric Methods
Overall, very little content pertaining to the SfM / SLAM side of the vision problem was present at ICLR 2016. This kind of work is very common at CVPR, and it’s a bit of a surprise that there wasn’t a lot of Robotics work at ICLR. It should be noted that the techniques used in SfM/SLAM are more based on multiple-view geometry and linear algebra than the data-driven deep learning of today.
Perhaps a better venue for Robotics and Deep Learning will be the June 2016 workshop titled Are the Sceptics Right? Limits and Potentials of Deep Learning in Robotics. This workshop is being held at RSS 2016, one of the world’s leading Robotics conferences.
这里讲几何方法。
总体来说,在今年的 ICLR 2016上,与 SfM / SLAM 有关的视觉问题,内容很少。这类工作在 CVPR 上是很常见的,但是 ICLR 上却没有大量的机器人相关的工作却让我有点惊讶。应该注意到这类用在 SfM/SLAM 上的技术更加基于多视角几何的学、线性代数,而深度学习是以数据为驱动的。
也许对于机器人机器以及深度学习更好的一个会议,是2016年6月要举办的“Are the Sceptics Right? Limits and Potentials of Deep Learning in Robotics ”的研讨会。这个研讨会是 RSS 2016 的一部分,RSS 是世界领先的机器人会议。
Part III: Quo Vadis Deep Learning?
深度学习,路往何方?
Neural Net Compression is going to be big – real-world applications demand it. The algos guys aren’t going to wait for TPU and VPUs to become mainstream. Deep Nets which can look at a picture and tell you what’s going on are going to be inside every single device which has a camera. In fact, I don’t see any reason why all cameras by 2020 won’t be able to produce a high-quality RGB image as well as a neural network response vector. New image formats will even have such “deep interpretation vectors” directly saved alongside the image. And it’s all going to be a neural net, in one shape or another.
神经网络压缩肯定是未来的大头 —— 因为现实的工业界有需求。算法研究人员(algos guys)等不及 TPU、VPUs成为主流的。看一眼就知道怎么回事的神经网络会安装在每个有摄像头设备里面。事实上,到2020年,我可以肯定摄像头能够拍摄出高质量的RGB图像,并处理神经网络向量。新的图片格式甚至会可以直接将图像转成“深度解译向量”,并与图片同时保存。然后任何的形状格式都可以转变成神经网络。
OpenAI had a strong presence at ICLR 2016, and I feel like every week a new PhD joins OpenAI. Google DeepMind and Facebook FAIR had a large number of papers. Google demoed a real-time version of deep-learning based style transfer using TensorFlow. Microsoft is no longer King of research. Startups were giving out little toys – Clarifai even gave out free sandals. Graduates with well-tuned Deep Learning skills will continue being in high-demand, but once the next generation of AI-driven startups emerge, it is only those willing to transfer their academic skills into a product world-facing focus, aka the upcoming wave of deep entrepreneurs, that will make serious $$$.
OpenAI 在今年的 ICLR 2016 上存在感很强,我估计每一周都有一个新的博士加入 OpenAI。Google、DeepMind 以及 Facebook 的 FAIR 刷了一大波的论文。谷歌用 TensorFlow 演示了基于深度学习的实时迁移。Microsoft 不在是研究领域的王者了。创业公司给了一些小礼物 —— Clarifai 甚至免费提供凉鞋。具有良好的深度学习技术的毕业生仍供不应求,但是一旦下一代 AI 驱动的创业公司进来的时候,只有那些能够将他们的学术能力转化为面向全球产品的人,又名“浪潮中的深度企业家”,能够拿到真金白银。
Research-wise, arXiv is a big productivity booster. Hopefully, now you know where to place your future deep learning research bets, have enough new insights to breath some inspiration into your favorite research problem, and you’ve gotten a taste of where the top researchers are heading. I encourage you to turn off your computer and have a white-board conversation with your colleagues about deep learning. Grab a friend, teach him some tricks.
从研究上来说,arXiv 是一个巨大的生产力助推器。现在我希望你知道该把自己在深度学习上的研究重心该放在哪里了,对你喜欢研究的问题有足够的洞察力,才能获取到一些灵感,你也感受到了最顶尖研究者的前进方向。我希望你关掉你的电脑,去与你的同事在白版上谈谈深度学习。叫上一个朋友,传授一些其中的技巧。
I’ll see you all at CVPR 2016. Until then, keep learning.
我们在CVPR 2016上见!请记住,保持学习!














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









