









我们接着之前学习的大数据来学习。之前说到了NoSql的HBase数据库以及Hadoop中的HDFS存储系统,可是我们发现这跟我们平时常用的关系型数据库有很大区别,为了使用方便,产生了针对大数据存储的数据仓库Hive。
一、是什么
1、概念
Hive 是一个基于 Hadoop 的开源数据仓库工具,用于存储和处理海量结构化数据。 它把海量数据存储于 hadoop 文件系统,而不是数据库,但提供了一套类数据库的数据存储和处理机制,并采用 HQL (类 SQL )语言对这些数据进行自动化管理和处理。我们可以把 Hive 中海量结构化数据看成一个个的表,而实际上这些数据是分布式存储在 HDFS 中的。 Hive 经过对语句进行解析和转换,最终生成一系列基于 hadoop 的 map/reduce 任务,通过执行这些任务完成数据处理。
2、体系结构
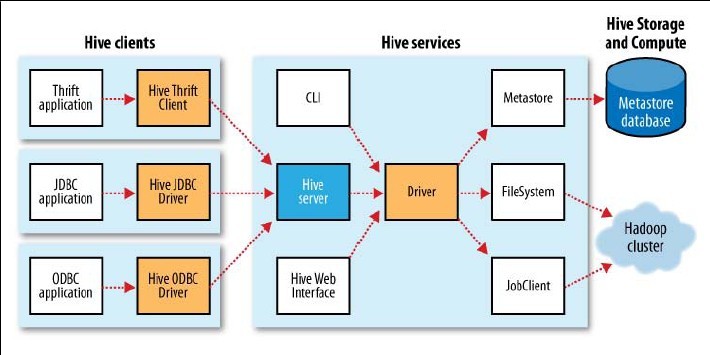
- hiveserver
hiveserver启动方式:hive –service hiveserver
HiveServer支持多种连接方式:Thrift、JDBC、ODBC
- metastore
metastore用来存储hive的元数据信息(表格、数据库定义等),默认情况下是和hive绑定的,部署在同一个JVM中,将元数据存储到Derby中
这种方式不好的一点是没有办法为一个Hive开启多个实例(Derby在多个服务实例之间没有办法共享)
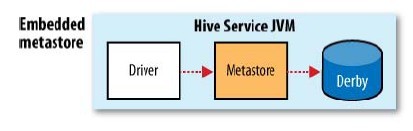
Hive提供了增强配置,可将数据库替换成MySql等关系数据库,将存储数据独立出来在多个服务实例之间共享
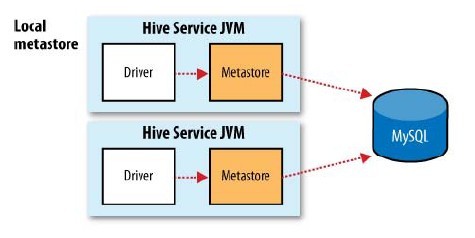
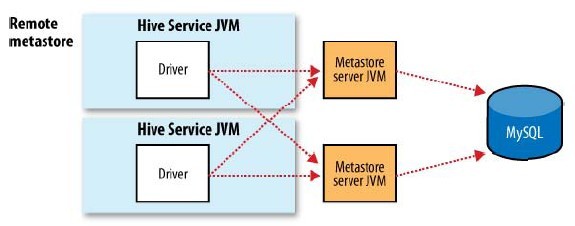
甚至还可以将metastore Service也独立出来,部署到其他JVM中去,在通过远程调用的方式去访问
3、优缺点
- 优点
可扩展Hive可以自由的扩展集群的规模,一般情况下不需要重启服务
延展性Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数
容错良好的容错性,节点出现问题SQL仍可完成执行
- 缺点
不支持记录级别的更新、插入和删除操作Hive不是一个完整的数据库。Hadoop以及hdfs的设计本身约束和局限性地限制了hive所能胜任的工作。Hive不支持记录级别的更新、插入和删除操作。但是用户可以通过查询生成新表或者将查询结果导入到文件中。
查询延时比较严重因为Hadoop是一个面向批处理的系统,而mapreduce任务(job)的启动过程需要消耗较长的时间,所以hive查询延时比较严重。传统数据库中在秒级可以完成的查询,在hive中,即时数据集相对较小,往往也需要执行更长的时间。
由于Hadoop本身的时间开销很大,并且Hadoop所被设计用来处理的数据规模非常大,因此提交查询和返回结果是可能具有非常大的延时的,所以hive并不能满足OLAP的“联机”部分,至少目前并没有满足。如果用户需要对大规模数据使用OLTP功能的话,那么应该选择使用一个NOSQL数据库。例如,和Hadoop结合使用的HBase及Cassandra.
不支持事务 二、相关联系
1、与HBase的关系
Hive是基于Hadoop的一个数据仓库工具,是为简化编写MapReduce程序而生的,Hive十分适合数据仓库的统计分析。
HBase是一个分布式的、面向列的开源数据库,它是一个适合于非结构化数据存储的数据库。
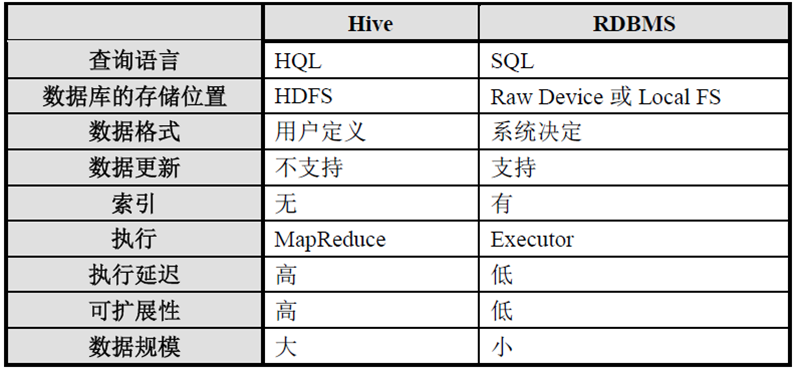
2、与RDBMS的关系
总结:
今天我们通过对Hive的学习,对大数据的处理又有了一定的认识。在以后的实际操作中,我们去慢慢掌握Hive的使用方法。通过不断学习,达到自己所追求的目标。















 1663
1663

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









