






介绍
在这篇文章中,我们讨论主成分分析(PCA)是如何工作的,以及它如何被用来作为分类问题的降维技术。在这篇文章的末尾,出于证明的目的提供了Matlab源代码。
在前面的文章中,我们讨论了所谓的维数诅咒,表明在高维空间分类器倾向于过度拟合训练数据。接下来产生的问题是哪些特征应该保留,哪些应该从高维特征向量中删除。
如果此特征向量的所有特征是统计独立的,可以简单地从这个向量中消除最小的判别特征。通过各种贪婪特征选择方法可以找到最小的判别特征。然而,在实践中,许多特征互相依赖或依赖于底层未知变量。因此,一个特征可以由一个值表示多种类型信息的组合。除去这样的一个特征将删除更多的信息。在接下来的段落中,我们介绍PCA作为特征提取来解决这个问题,并从两个不同的角度介绍其内部运作。
PCA-一种去相关方法
通常,特征都是相关的。例如,我们想用一幅图中每个像素的红,绿和蓝分量进行分类(例如,检测狗与猫)。对红光最敏感的图像传感器也能捕捉一些蓝光和绿光。类似地,对蓝光和绿光最敏感传感器对红光也表现出一定程度的敏感度。其结果是,一个像素的R,G,B分量是统计相关的。因此,简单地从特征向量中消除R分量也隐含删除了有关G和B信道的信息。换句话说,消除特性之前,我们想改变整个特征空间从而获得底层不相关分量。
考虑下面二维特征空间的例子:
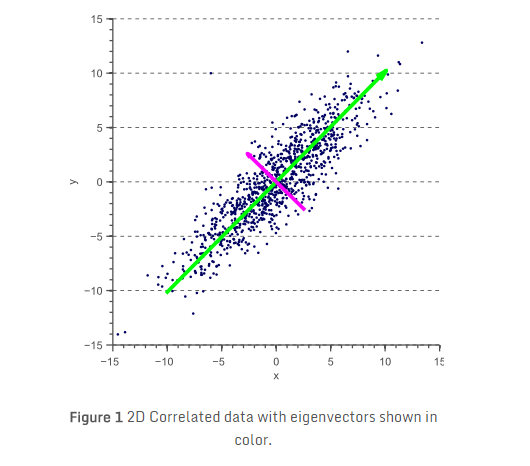
图1所示的特征x和y明显是相关的。事实上,它们的协方差矩阵是:

另一篇文章中,我们讨论了协方差矩阵的几何解释。我们看到协方差矩阵可以被分解为白色不相关数据上的一系列旋转和缩放操作,其中,旋转矩阵用协方差矩阵的特征向量定义。因此,直观来看,图1中所示的数据D通过旋转每个数据点可以去相关,使得特征向量V成为新的基准轴:
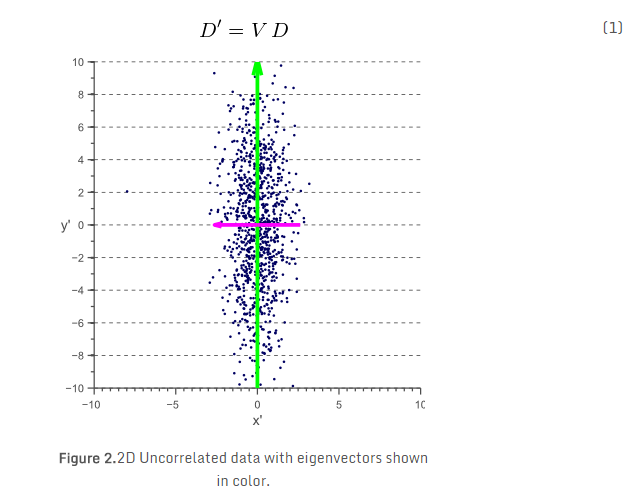
所得到数据的协方差矩阵现在是对角的,这意味着新的轴是不相关的:
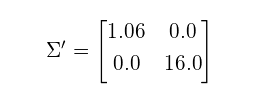
实际上,本实施例中图1所示的原始数据通过线性组合两个一维高斯特征向量x1~N(0,1)和x2~N(0,1)生成:
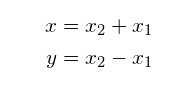
由于特征x和y是一些底层未知成分x1和x2的线性组合,直接消除x或y会除去来自x1和x2的一些信息。相反,用协方差矩阵的特征向量来旋转数据,使我们能够直接恢复独立成分x1和x2。这可以看作是:原始数据协方差矩阵的特征向量是(每列表示一个特征向量):

首先要注意的一点是,在此情况下V是旋转矩阵,对应于45度(cos(45)=0.7071)的旋转,从图1可以明显的看到。其次,将V看做一个线性变换矩阵得到一个新的坐标系,使得每个新特征x’和y’用原始特征x和y的线性组合来表示:

换言之,特征空间的去相关对应于未知的,不相关成分x1和y1的恢复(如果变换矩阵是不正交的,多一个未知的比例因子)。一旦这些成分被恢复,降低特征空间的维数就变得很容易了,只需要简单地删除x1或x2即可。
在上述例子中,我们以一个二维问题开始。如果我们想降低维数,问题仍然是是否消除x1(x’)或y1(y’)。尽管这样的选择可能取决于许多因素,如分类问题的数据可分性,但是PCA简单地假定最有趣的特征具有最大方差。这种假设是基于信息论的角度,由于最大方差的维对应于最大熵的维,编码了大部分信息。最小的特征向量将简单地表示噪声成分,而最大的特征向量往往对应于定义数据的主要成分。
由主成分分析降低维数,然后投影数据到协方差矩阵的最大特征向量上。对于上面的例子,所得到的一维特征空间如图3所示:
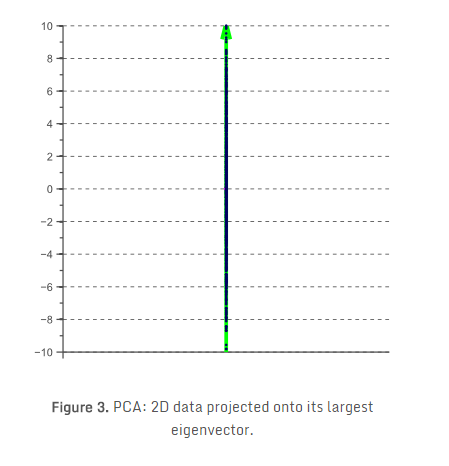
显然,上面的例子很容易推广到更高维的特征空间。例如,在三维情况下,我们既可以将数据投影到两个最大特征向量定义的平面来获得2D特征空间,也可以将其投影到最大特征向量来获得1D特征空间。结果示于图4:
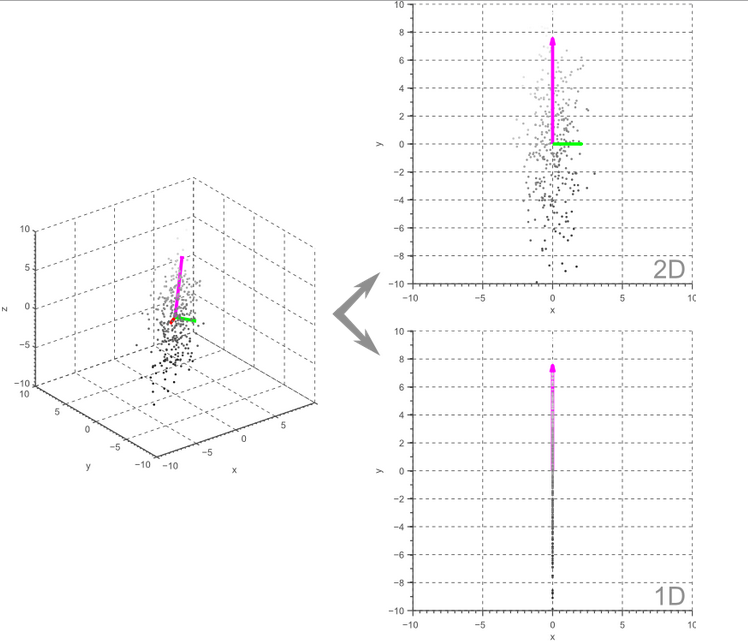
Figure 4. 3D data projected onto a 2D or 1D linear subspace by means of Principal Component Analysis.
一般情况下,主成分分析使我们获得原始N维数据的一个线性M维子空间,其中M小于等于N。此外,如果未知,不相关的成分满足高斯分布,则PCA实际上充当了独立成分分析的角色,因为不相关的高斯变量在统计上是独立的。但是,如果底层成分不是正态分布,PCA仅仅产生去相关的变量,这些变量不一定是独立的。在这种情况下,非线性降维算法可能是一个更好的选择。
PCA-正交回归方法
在上述的讨论中,我们以获得独立成分(如果数据不是正态分布,至少是不相关成分)为目标来减少特征空间的维数。我们发现,这些所谓的“主成分”是由我们数据协方差矩阵的特征值分解获得的。然后将数据投影到最大特征向量从而降低维数。
现在,我们不考虑找不相关成分。相反,我们现在尝试通过找到原始特征空间上的一个线性子空间来实现降维数,我们可以将我们的数据映射的这个子空间上使得映射误差最小化。在二维情况下,这意味着我们试图找到一个向量,映射到这个向量上的数据对应于一个映射误差,而这个误差比任何其他可能向量所映射数据的映射误差低。接下来的问题是如何找到这个最佳向量。
考虑图5所示的例子。三种不同的映射向量,以及所得到的一维数据。在接下来的段落中,我们将讨论如何确定哪些映射向量最小化映射误差。在寻找这个向量之前,我们必须定义这个误差函数。
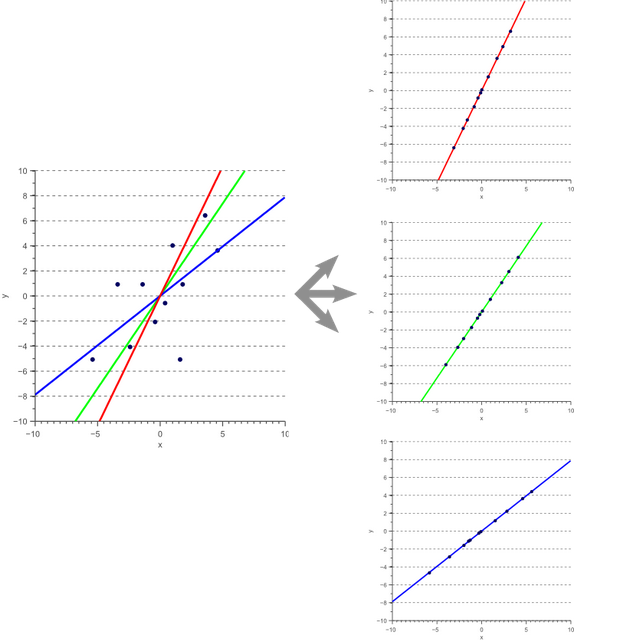
Figure 5 Dimensionality reduction by projection onto a linear subspace
一个众所周知的用一条线来拟合2D数据的方法是最小二乘回归。给定自变量x和因变量y,最小二乘回归对应于f(x)=ax+b,使得残差的平方之和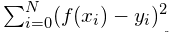
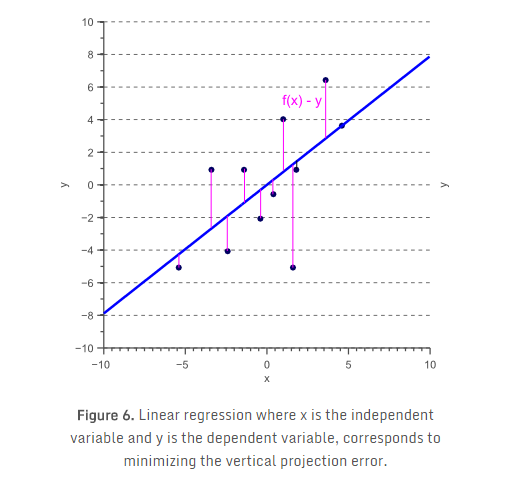
然而,在特征提取的情况下,可能会问,为什么我们会定义x为自变量,特征y为因变量。事实上,我们可以很容易地定义y为自变量,并找到一个线性函数f(y)来预测因变量x,使得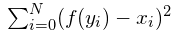
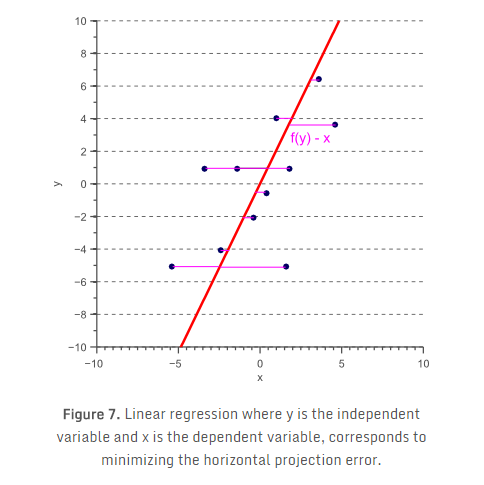
显然,自变量和因变量的选择改变了所得到的模型,使得普通的最小二乘回归是对称的回归。这样的原因是最小二乘回归假定自变量是无噪声的,而因变量是有噪声的。然而,在分类的情况下,所有的特征通常是有噪声的观测,使得x和y都应被视为自变量。事实上,我们希望得到一个模型f(x,y),它同时最小化水平和垂直的映射误差。这对应于找到一个模型,使得正交映射误差最小化,如图8。
由此产生的回归被称为总体最小二乘回归或正交回归,假定两个变量都是不完善的观察。一个有趣的观察是所获得的向量(表示最小化正交映射误差的映射方向)对应于数据的最大主成分:
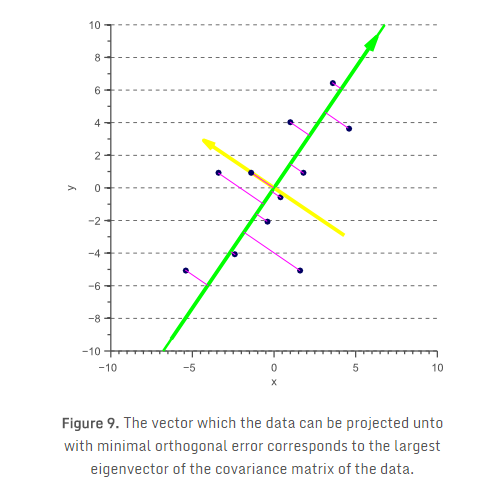
换言之,如果我们想通过把原始数据映射到一个向量上使得平方映射误差在所有方向上最小来减少维数,那么我们可以简单地映射数据到最大特征向量。这正是我们前一节所谓的PCA,这样的映射也消除了特征空间的相关性。
PCA实际应用:特征脸
上述实例出于可视化的目的限于两个或三个维度,当特征的数量和训练样本相比不可忽略时,降低维数通常会变得非常重要。举个例子,假设我们要执行面部识别,即基于带有标记的面部图像训练数据集来确定人的身份。一个办法是把图像上每个像素的亮度作为特征。如果输入图像的大小是32×32,这意味着该特征向量包含1024个特征值。判断新的图像通过计算这1024维矢量与我们训练数据集中特征向量之间的欧氏距离完成。然后最小距离告诉我们正在寻找的那个人。
然而,如果我们只有几百训练样本,在1024维空间中运行会变得有问题。此外,欧氏距离在高维空间中行为比较奇怪。因此,我们可以利用PCA方法通过计算1024维特征向量协方差矩阵的特征向量来降低特征空间的维数,然后映射每个特征向量到最大特征向量。
因为2D数据的特征向量是2维的,三维数据的特征向量是3维的,1024维数据的特征向量是1024维。换句话说,为了可视化,我们可以重塑每个1024维特征向量到一个32×32的图像。图10展示了由剑桥人脸数据集的特征分解获得的前四个特征向量:

每个1024维特征向量可以映射到N个最大的特征向量,并可以表示为这些特征脸的线性组合。这些线性组合的权重确定人的身份。因为最大特征向量表示数据中的最大方差,所以这些特征脸描述信息量最大的图像区域(眼睛,鼻子,嘴等)。只考虑前N(例如,N = 70)个特征向量,特征空间的维数大大减少了。
剩下的问题是现在使用了多少个特征脸,或者在一般情况下,应保留多少个特征向量。去除过多的特征向量可能会删除特征空间里的重要信息,而消除太少会留给我们维数的诅咒。遗憾的是,对这个问题没有明确的回答。尽管交叉验证技术可用于获得超参数的估计值,但选择维数的最佳数目仍然是一个问题,目前主要用一个经验(学术术语,意思是没有太多的“试错法”)方式来解决。注意,当消除特征向量时,这对检查保留多少原始数据的方差(以百分比表示)是有用的,用保留特征值的总和除以所有特征值的总和。
PCA配方
基于前面的章节,我们现在可以列出应用PCA进行特征提取的简单配方:
1)中心化数据
在另一篇文章中,我们表明协方差矩阵可以写为一系列线性操作(缩放和旋转)。特征分解提取这些变换矩阵:特征向量表示旋转矩阵,而特征值代表缩放因子。但是,协方差矩阵不包含数据变换相关的任何信息。事实上,为了表示变换,我们需要仿射变换而不是线性变换。
因此,应用PCA来旋转数据以获得不相关轴之前,任何现有的移位都需要用每个数据点减去数据的平均值。这只是对应于集中数据,使得其平均值为零。
2)标准化数据
协方差矩阵的特征向量指向数据最大方差的方向。然而,方差是绝对值,而不是相对的。这意味着,以厘米为单位测得的数据方差比以米为单位测得的相同数据的方差大得多。考虑这样一个例子,一个特征表示对象的长度(米为单位),而第二个特征表示对象的宽度(厘米为单位)。如果数据没有被标准化,那么最大方差及最大特征向量将隐式地由第一个特征定义。
为了避免PCA的比例相关性,用每个特征除以它的标准差来标准化数据是有用的。如果不同的特征对应不同的指标,这一点尤其重要。
3)计算特征值分解
由于数据将被映射到最大特征向量来减少维数,所以需要获得特征分解。有效计算特征分解方法中使用最广泛的是奇异值分解(SVD)。
4)映射数据
为了降低维数,数据被简单地映射到最大特征向量。令V表示矩阵,该矩阵的列包含最大特征向量,令D表示原始数据,该数据的列包含不同的观测值。然后映射数据D’通过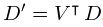

PCA陷阱
在上述的讨论中,已经做出了几个假设。在第一部分,我们讨论了PCA如何去相关。事实上,我们通过恢复未知的,潜在的独立成分开始讨论。然后,假设我们的数据满足高斯分布,使得统计独立性简单地对应于缺少一个线性关系。事实上,PCA允许我们去相关,从而恢复高斯情况下的独立成分。然而,值得注意的是,去相关只对应于高斯情况下的统计独立性。考虑采样y=sin(x)半个周期所获得的数据:
虽然上述数据显然是不相关的(平均而言,当x值增加时,y值增加的和它减少的一样多),因此对应于一个对角的协方差矩阵,但这两个变量之间仍然有明确的非线性关系。
一般情况下,PCA值去数据相关,但不会删除统计相关。如果潜在的成分是非高斯的,诸如ICA等技术会更好。另一方面,如果非线性显然存在,如非线性PCA降低等技术都可以使用。然而,请记住,这些方法很容易过拟合,因为更多的参数是基于相同数量的训练数据被估计出来的。
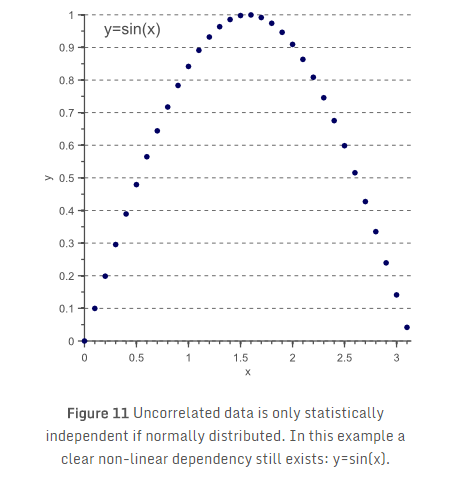
在本文中的第二个假设是,最能区别的信息通过特征空间中的最大方差捕获。因为最大方差方向编码的信息最多,这很可能是真的。然而,有一些情况,其中的区别信息实际驻留在最小方差的方向,使得PCA可以大大损害分类性能。举个例子,考虑图12的两种情况,我们将二维特征空间降到1D表示:
如果最能区别的信息包含在较小的特征向量中,应用PCA实际上可能恶化维数的诅咒,因为现在需要更复杂的分类模型(例如非线性分类器)来分类低维问题。在这种情况下,其他降维的方法可能会感兴趣,如线性判别分析(LDA),其试图找到能够一个映射向量,该向量最优的分开两个类别。
源码
下面的代码片段(Matlab)展示了主成分分析如何进行降维的:
http://download.csdn.net/my/uploads(资源正在审核,如果有需要的可能需要等一等,或可以私信我也行)
总结
在这篇文章中,我们从两个观点讨论了PCA对特征提取和降维的优点。第一个观点说明的PCA如何允许我们去除特征空间的相关性,而第二种观点表明,PCA实际上对应于正交回归。
此外,我们还简要介绍了众所周知的特征脸实例,且是基于主成分分析的特征提取。我们还讨论了主成分分析的一些最重要的缺点。














 2521
2521











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









