









这几天需要对项目的测试环境的Hbase的数据做迁移,因为数据量不是很大,所以就做了一个Hbase clent的程序进行数据的导出,本身对于Hadoop体系不是很熟悉,对Hbase的一些配置也不是很理解,虽然之前写过hbase client的程序,但是这次对Hbase的认识又更近了一层。废话不多说。
本身的代码就是简单的,但是牵扯出很多问题。代码如下所示:
import java.io.File;
import java.io.IOException;
import java.io.PrintStream;
import java.security.PrivilegedExceptionAction;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.HTableDescriptor;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import org.apache.hadoop.hbase.client.HTable;
import org.apache.hadoop.hbase.client.Result;
import org.apache.hadoop.hbase.client.ResultScanner;
import org.apache.hadoop.hbase.client.Scan;
import org.apache.hadoop.security.UserGroupInformation;
public class HbaseTableCopy implements HbaseCommon{
public static Configuration confSource = HBaseConfiguration.create();
static{
confSource.set("hbase.zookeeper.quorum", "10.41.2.100:2181");
}
public HTableDescriptor[] getTables(HBaseAdmin admin) throws IOException{
HTableDescriptor[] discriptor =admin.listTables();
return discriptor;
}
public static void main(String args[]){
try{
UserGroupInformation.createRemoteUser("admin").doAs(new PrivilegedExceptionAction<Object>() {
@Override
public Object run() throws Exception {
File fileDes = null;
HbaseTableCopy copy = new HbaseTableCopy();
HBaseAdmin adminSource = new HBaseAdmin(confSource);
HTableDescriptor[] sourceDesc = copy.getTables(adminSource);
for(HTableDescriptor dis:sourceDesc){
String TableName = dis.getNameAsString();
HTable HbaseTable = new HTable(confSource, TableName.getBytes());
System.out.println("read "+TableName+".....");
fileDes = new File("D:"+File.separator+"hbase"+File.separator+TableName+".txt");
if(!fileDes.exists()){
fileDes.createNewFile();
}
PrintStream print =new PrintStream(fileDes);
Scan scan = new Scan();
ResultScanner scanner = HbaseTable.getScanner(scan);
for(Result res =scanner.next();res!=null; res =scanner.next()){
print.println(new String(res.getRow(),"UTF-8"));
}
System.out.println("already read "+TableName+".....");
scanner.close();
}
return null;
}
});
}catch(Exception e){
e.printStackTrace();
System.exit(0);
}
}
}代码的意义很简单,其实就是实例化一个HbaseAdmain和Htable的实例,进行对表和数据的操作,HbaseAdmain一般是进行表层面的操作而Htable则是对特定表进行数据层面的操作,但是在实例化HbaseAdmain的时候程序会等待,过一段时间之后会报超时的错误,错误如下:

根据提示,大概能猜测出是连不上hbase的Master了,这样应该明确的指定hbase的Master,在这里写Hbase Client的客户端的时候要注意这样一段代码:
public static Configuration confSource = HBaseConfiguration.create();这段代码的意思是根据默认的配置创建配置对象,当然这个配置对象在创建的时候会加载默认的配置文件即hbase-default.xml,此文件在hbase-0.94.5.jar包中(0.98版本的hbase在hbase-clent.jar中),这里还会隐含加载一个hbase-site.xml文件,这个文件通常由用户自己配置,放置在classpath下,如果存在会默认加载,这里需要注意的是,如果hbase-site.xml和hbase-default.xml文件中都存在的配置项,那么后加载的配置会覆盖先前加载的配置(final类型除外,类似于java中的final)。此处默认是site后于defaulit加载。本程序因为缺少master的配置,所以对hbase-site.xml文件部分配置如下:
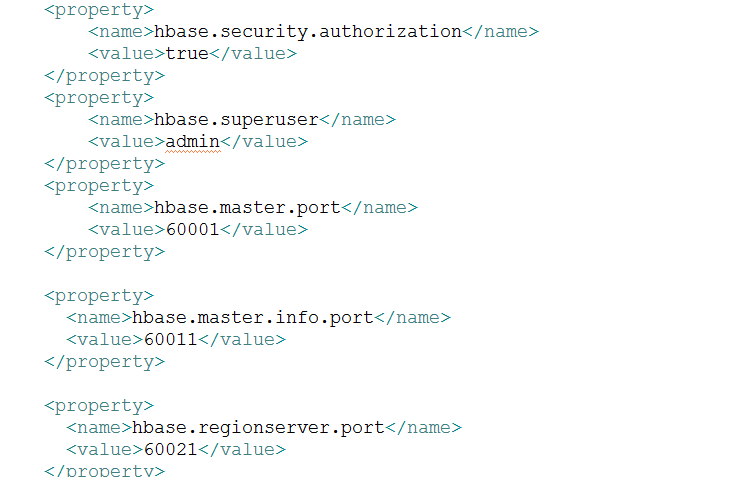
之前写过0.98版本的Hbase client程序,此处不需要更改(个人猜测可能和环境有关系)。
配置之后重新运行程序,这次HbaseAdmain成功创建了。
但是在创建HTable的时候问题又发生了,程序无限等待,不报任何错误,这样就比较尴尬了。网上也有问这个问题的,但是没人解答,后来多方查看,在配置host的时候,只配置了master没有配置slave,(郁闷,竟然忘记了这里)。
同时,这里暴露了一个问题,就是说在创建HTable的时候是回去访问RegionServer的,这里的无限等待就是没有取到对于的host,无法找到RegionServer。
把host配置上,ok,重新运行,程序可以完整的跑下来。这里我又联想到了另一个问题,就是为什么要配置host,只有个主机的ip不就好了?我猜想可能是和hadoop里面都是通过host的名称来进行配置有关,如果有了解的还请大神留言。总之收获很大,在写client的时候一定要注意host和默认的配置文件。














 6051
6051











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









