







关于Rabit的一篇论文:http://homes.cs.washington.edu/~icano/projects/rabit.pdf
Rabit有着较完善的文档,理解Rabit重点在于它的Allreduce和Broadcast,还有就是它的容错和恢复机制。
首先要理解的是Allreduce这个概念,Allreduce相较于mapreduce,通过允许程序员轻松的将模型(这些模型将被复制于每个节点)维护于内存中,使它避免了不必要的map过程、重新分配内存步骤以及迭代器之间的硬盘读写过程。如图所示:
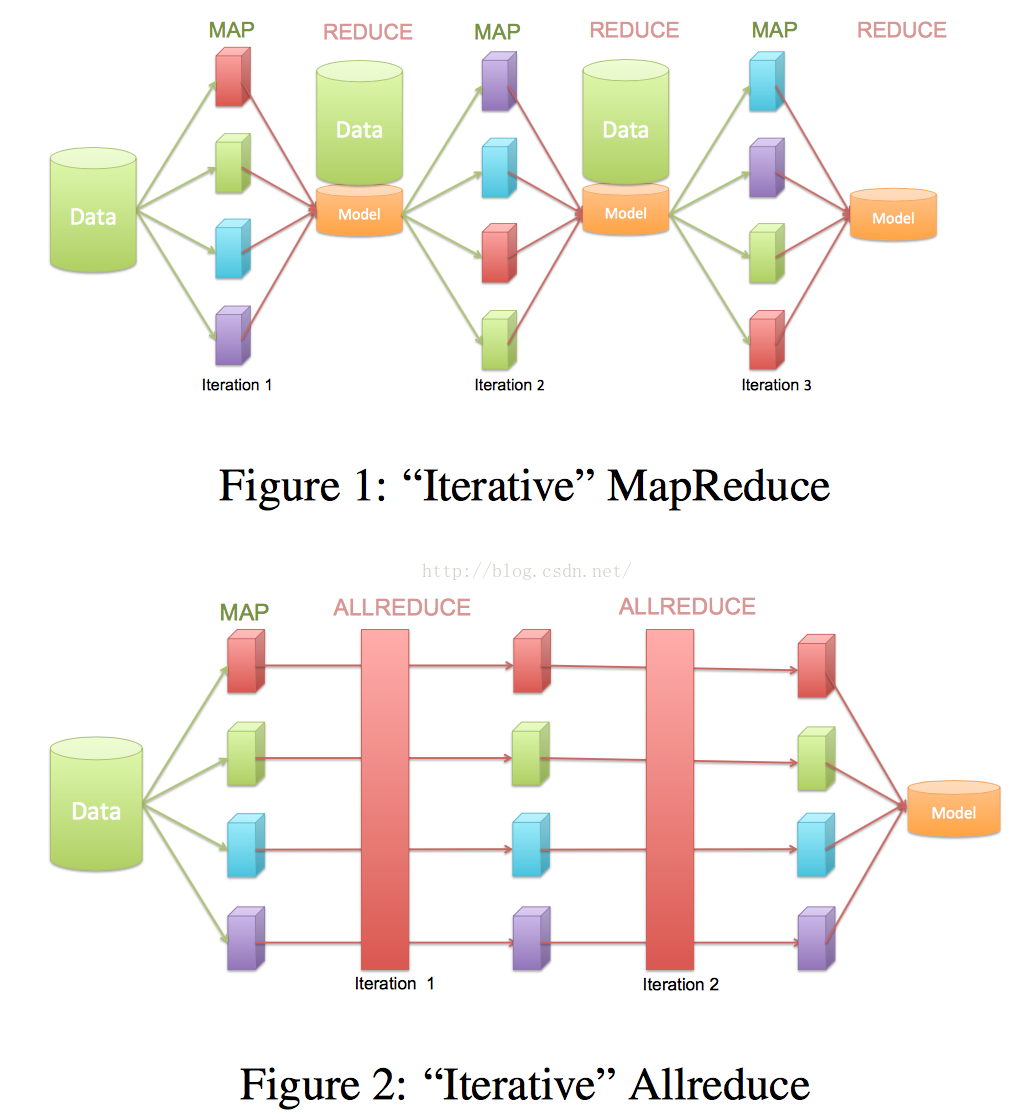
Rabit的Allreduce和Broadcast过程,可以用下图很具象的来解释:
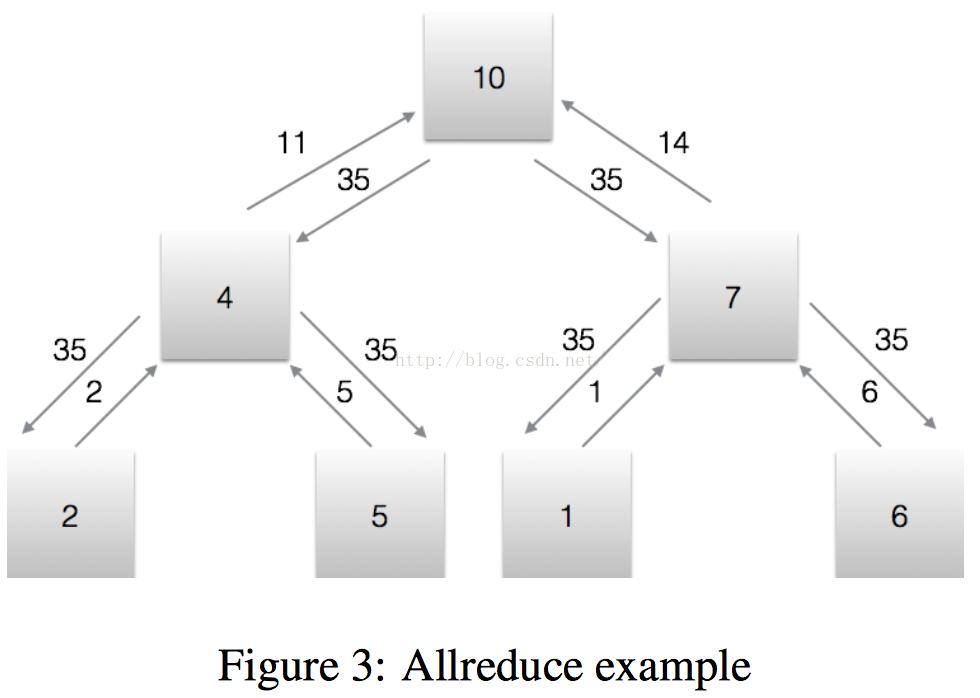
每个节点向上传递自己的值,每个节点执行一次求和操作,直到根节点,这就是Allreduce过程;根节点告诉所有叶子节点结果,这就是Broadcast过程。
那么这俩个过程有何作用呢,往下看。
Rabit作为一个同步的分布式机器学习通信库,其最重要的特性就是其可靠性,它的可靠性体现在俩点:容错性和可恢复性。
那么是如何达到容错的呢?下图可以解释其容错机制:
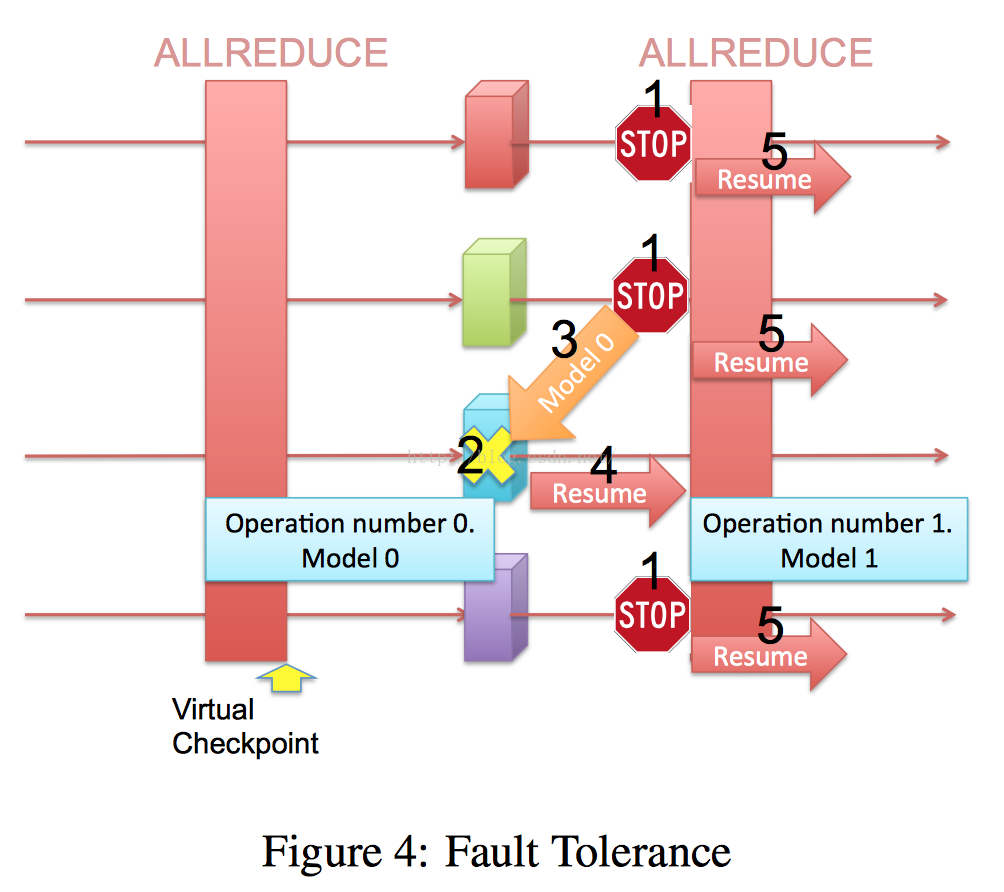
从1 到 5是其执行步骤:
-
Pause every node until the failed node is fully recov- ered.
-
Detect the model version we need to recover by ob- taining the minimum operation number. This is done using the Consensus Protocol explained in section 3.2.2.
-
Transfer the model to the failed node using the Rout- ing Protocol explained in section 3.2.2.
-
Resume the execution of the failed node using the received model.
-
Resume the execution of the other nodes as soon as the failed node catches up.
容易理解,当蓝点down 机后,所有节点在下一个Allreduce前等待该节点恢复,在蓝点启动后,从最近相邻节点读取模型,然后和其他节点一同继续下去。
那么,是如何得知哪个点down 机了呢,就是通过模型版本加前面提到过的Allreduce,这里采用了一个一致性协议,协议规定所有模型的版本必须一致,版本号根据Allreduce轮数依次增加,所以找到有版本号比大家低的,就说明那个机器down掉了,恢复即可。如图所示:

关于如何选择最近节点,参考下图:
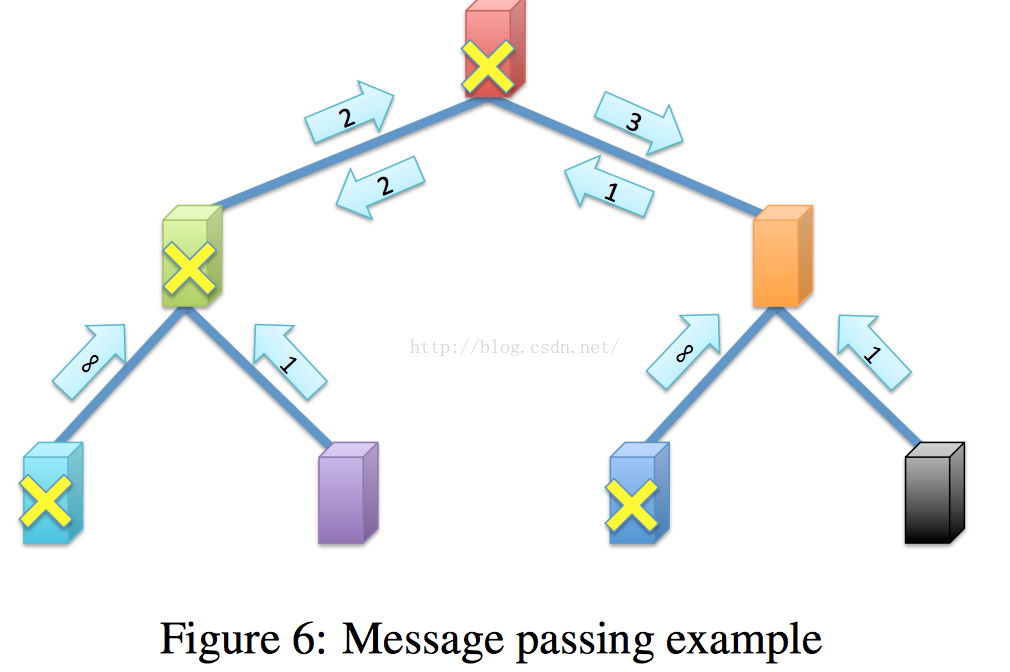
这里采用的是路由协议,一共俩轮,第一轮计算距离,第二轮用最近节点恢复。














 3301
3301











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









