







列举各种排序算法,定义,举例,解释,java版实现。及最后附时间,空间复杂度,稳定性等比较表。
1:冒泡排序
在要排序的一组数中,对当前还未排好序的范围内的全部数,自上 而下对相邻的两个数依次进行比较和调整,让较大的数往下沉,较 小的往上冒。
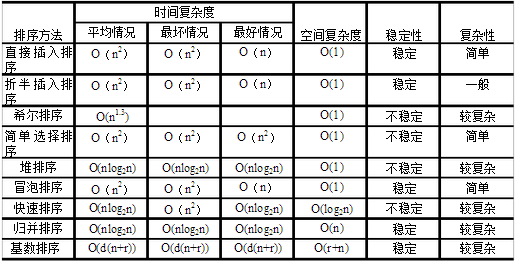
即:每当两相邻的数比较后发现它们的排序与排序要 求相反时,就将它们互换。 冒泡排序是稳定的。算法时间复杂度O(n^2)
例:相邻比较,前大后小,交换位置,循环N轮(一轮N次);
| 初始位置 | 4 | 7 | 9 | 6 | 5 |
|---|---|---|---|---|---|
| 第一轮比较 | 4 | 7 | 6 | 5 | 9 |
| 第二轮比较 | 4 | 6 | 5 | 7 | 9 |
| 第三轮比较 | 4 | 5 | 6 | 7 | 9 |
| 。。。 |
具体算法:
// 冒泡
public static int[] maopao(int[] arr) {
System.out.println(" ====This is a maopao sort :====");
int temp;
for(int i=arr.length-1;i>=1;i--){
for(int j=0;j<i;j++){
if(arr[j]>arr[j+1]){
temp=arr[j];
arr[j]=arr[j+1];
arr[j+1]=temp;
}
}
}
return arr;
}2、选择排序 :
在要排序的一组数中,选出最小的一个数与第一个位置的数交换; 然后在剩下的数当中再找最小的与第二个位置的数交换,如此循环 到倒数第二个数和最后一个数比较为止。 选择排序是不稳定的。算法复杂度O(n^2);
例:注意选择排序只是交换最小值位置和每一轮开始的位置。
| 初始位置 | 4 | 7 | 6 | 5 | 9 |
|---|---|---|---|---|---|
| 第一轮 | 4 | 7 | 6 | 5 | 9 |
| 第二轮 | 4 | 5 | 6 | 7 | 9 |
| 第三轮 | |||||
| 。。。 |
具体算法:
//选择
public static int[] xuanze(int[] arr){
System.out.println(" ====This is a xuanze sort :====");
int temp;
int index;
for (int i = 0; i < arr.length-1; i++) {
temp=arr[i];
index=i;
for (int j = i+1; j < arr.length; j++) {
if(arr[j]<temp){
temp=arr[j];
index=j;//记录最小数的下标
}
}
//将最小的元素交换到前面
temp = arr[i];
arr[i] = arr[index];
arr[index] = temp;
}
return arr;
}3、插入排序
在要排序的一组数中,假设前面(n-1) [n>=2] 个数已经是排 好顺序的,现在要把第n个数插到前面的有序数中,使得这n个数 也是排好顺序的。如此反复循环,直到全部排好顺序。 (这是从第n个数开始插入)
3(1):直接插入排序是稳定的,但是没有利用之前排好序的数组。算法时间复杂度O(n^2);
例:
| 初始位置 | 4 | 7 | 6 | 5 | 9 |
|---|---|---|---|---|---|
| 第一轮 | 4 | 6 | 7 | 5 | 9 |
| 第二轮 | 4 | 5 | 6 | 7 | 9 |
| 第三轮 | 4 | 5 | 6 | 7 | 9 |
| 。。。 |
具体算法:
//直接插入排序
public static int[] zhijieInsert(int[] arr){
System.out.println(" ====This is a zhijieInsert sort :====");
int temp;
for(int i = 1;i <arr.length; i++){
for (int j = 0; j < i; j++) {
if(arr[i]<arr[j]){//如果arr[i]<arr[j]则把arr[i]放到arr[j]之前,
//arr[j](包括)之后的依次后退一位
temp=arr[i];
for(int k = i-1;k >= j;k--){//只需要把j到i之间的位置变动就行
arr[k+1] = arr[k];
}
arr[j] = temp;
}
}
}
return arr;
}3(2):shell插入排序:
由于插入排序,各个元素移动的长度,每次都是1,移动的次数较多;如果移动的长度大于1,那么移动的次数自然而然较少。Shell排序时,对列表元素把相邻长度K的元素分为一组,然后对每一组进行插入排序,之后加少长度k的值,再进行排序,重复此操作(分组,排序),直到长度k为1 。优点:较易实现,减少了移动次数 缺点:效率低 时间复杂度o(n^2)。
例子和具体算法见算法5。
4、快速排序
快速排序是对冒泡排序的一种本质改进。它的基本思想是通过一趟 扫描后,使得排序序列的长度能大幅度地减少。
在冒泡排序中,一次 扫描只能确保最大数值的数移到正确位置,而待排序序列的长度可能只 减少1。快速排序通过一趟扫描,就能确保以某个数为基准点的左边各数
都比它小,右边各数都比它大。然后又用同样的方法处理 它左右两边的数,直到基准点的左右只有一个元素为止。
显然快速排序可以用递归实现,当然也可以用栈化解递归实现。 快速排序是不稳定的。最理想情况算法时间复杂度O(nlog2n),最坏O(n^2)
简单来说:取一个数作为参考,从最后开始找个数与之比较,小则交换位置,然后从最前开始找个数与之比较,大则交换位置,直到结束。
例子:为了详细说明,再加2个数进去
| 初始位置 | 4 | 7 | 6 | 5 | 9 | 3 | 8 |
|---|---|---|---|---|---|---|---|
| 第一轮 | 3 | 4 | 6 | 5 | 9 | 7 | 8 |
| 第二轮 | 3 | 4 | 5 | 6 | 9 | 7 | 8 |
| 第三轮 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| 。。。 |
第一轮:将第一个位置4作为比较对象,从第N位比较,8比4大,不动,3比4小,交换位置(3.7.6.5.9.4.8),
然后从第0+1个位置比较比4大的放到4后面,7比4大,交换位置(3.4.6.5.9.7.8)
继续从N-1位比较,小则交换,7比4大,9比4大,5,6比4大,到4自己结束第一轮;结果是[{3}4{6.5.9.7.8}]从4分开两份数据;左边比4都小,右边比4都大;
第二轮:分开比较,左边1个数,结束。右边{6.5.9.7.8}按6开始比较,道理同第一轮结束后是{5.6.9.7.8},以后继续同理递归。
具体算法:
/**
* 一次排序单元,完成此方法,key左边都比key小,key右边都比key大。
*
* @param array
* 排序数组
* @param low
* 排序起始位置
* @param high
* 排序结束位置
* @return 单元排序后的数组
*/
private static int sortUnit(int[] arr, int low, int high) {
int temp = arr[low];
while (low < high) {
// 从后向前搜索比key小的值
while (arr[high] >= temp && high > low)
--high;
// 比key小的放左边
arr[low] = arr[high];
// 从前向后搜索比key大的值,比key大的放右边
while (arr[low] <= temp && high > low)
++low;
// 比key大的放右边
arr[high] = arr[low];
}
// 左边都比key小,右边都比key大。将key放在游标当前位置。此时low等于high
arr[high] = temp;
return high;
}
/**
* 快速排序
* 第一次,默认low=0,high=arr.length-1
* @param arr
* @return
*/
public static int[] quickSort(int[] arr, int low, int high) {
if (low <= high) {//没结束
// 完成一次单元排序
int index = sortUnit(arr, low, high);
// 对左边单元进行排序
quickSort(arr, low, index - 1);
// 对右边单元进行排序
quickSort(arr, index + 1, high);
}
return arr;
}5、希尔排序 (一种插入排序)
D.L.shell于1959年在以他名字命名的排序算法中实现 了这一思想。
算法先将要排序的一组数按某个增量d分成若干组,每组中 记录的下标相差d.对每组中全部元素进行排序,然后再用一个较小的增量 对它进行,在每组中再进行排序。当增量减到1时,整个要排序的数被分成 一组,排序完成。希尔排序的时间复杂度是O(n的1.25次方)~O(1.6n的1.25次方) 这是一个经验公式。
次算法第一次实现了复杂度小于O(n^2)的算法。希尔排序是不稳定的。并且和初始位置有关。希尔排序的时间复杂度为 O(N*(logN)^2)。有点是算法简短精炼,复杂度仅次于快速。
| 初始位置 | 4 | 7 | 6 | 5 | 9 |
|---|---|---|---|---|---|
| 第一轮 | 4 | 7 | 6 | 5 | 9 |
| 第二轮 | 4 | 5 | 6 | 7 | 9 |
| 。。。 | |||||
具体算法:
// 希尔排序
public static int[] shellSort(int arr[]) {
int i, j, h, temp;
int n = arr.length;
h = n / 2;
while (h >=1) {
for (i = h; i < n; i++) {
temp = arr[i];
for (j = i - h; j >= 0 && arr[j] > temp; j = j - h) {
arr[j + h] = arr[j];
}
arr[j + h] = temp;
}
h = (int) (h / 2.0);
}
return arr;
}6:归并排序
先将所有数据分割成单个的元素,这个时候单个元素都是有序的,然后前后相邻的两个两两有序地合并,合并后的这两个数据再与后面的两个合并后的数据再次合并,充分前面的过程直到所有的数据都合并到一块。
通常在合并的时候需要分配新的内存。时间复杂度O(nlog2n)。具体算法可以参考JDK中Arrays的sort方法;
例:
| 初始位置 | 4 | 7 | 6 | 5 | 9 |
|---|---|---|---|---|---|
| 第一轮 | 4 | 7 | 6 | 5 | 9 |
| 第二轮 | 4 | 7 | 5 | 6 | 9 |
| 第三轮 | 4 | 5 | 6 | 7 | 9 |
| 。。。 |
解释:排序开始第一轮分割数组为[4][7][6][5][9]第二轮合并相邻的数组并排序[4.7][5.6][9]第三轮继续合并相邻的数组[4.5.6.7][9]继续。。结束。
具体算法: // 归并排序
public static int[] mergeSort(int[] arr) {
if (arr.length == 1)
return arr;
final int dividePos = arr.length / 2;
int[] array1 = new int[dividePos];
System.arraycopy(arr, 0, array1, 0, array1.length);
int[] array2 = new int[arr.length - dividePos];
System.arraycopy(arr, dividePos, array2, 0, array2.length);
return merge(mergeSort(array1), mergeSort(array2));
}
public static int[] merge(int[] a1, int[] a2) {
int[] result = new int[a1.length + a2.length];
int cursor = 0;
int cursor1 = 0;
int cursor2 = 0;
while (cursor1 < a1.length && cursor2 < a2.length) {
if (a1[cursor1] > a2[cursor2]) {
result[cursor++] = a2[cursor2++];
} else {
result[cursor++] = a1[cursor1++];
}
}
while (cursor1 < a1.length) {
result[cursor++] = a1[cursor1++];
}
while (cursor2 < a2.length) {
result[cursor++] = a2[cursor2++];
}
return result;
}7、堆排序
堆排序是一种树形选择排序,是对直接选择排序的有效改进。
堆的定义如下:具有n个元素的序列(h1,h2,...,hn),当且仅当 满足(hi>=h2i,hi>=2i+1)或(hi<=h2i,hi<=2i+1)(i=1,2,...,n/2) 时称之为堆。在这里只讨论满足前者条件的堆。
由堆的定义可以看出,堆顶元素(即第一个元素)必为最大项。完全二叉树可以 很直观地表示堆的结构。堆顶为根,其它为左子树、右子树。 初始时把要排序的数的序列看作是一棵顺序存储的二叉树,调整它们的存储顺序, 使之成为一个堆,这时堆的根节点的数最大。然后将根节点与堆的最后一个节点 交换。然后对前面(n-1)个数重新调整使之成为堆。依此类推,直到只有两个节点 的堆,并对它们作交换,最后得到有n个节点的有序序列。 从算法描述来看,堆排序需要两个过程,一是建立堆,二是堆顶与堆的最后一个元素 交换位置。
所以堆排序有两个函数组成。一是建堆的渗透函数,二是反复调用渗透函数 实现排序的函数。有最大堆和最少堆之分 堆排序是不稳定的。算法时间复杂度O(nlog2n)。
C/C++实现:http://www.cppblog.com/toMyself/archive/2011/07/06/150329.html
视觉直观感受7种常用的排序算法 http://linux.cn/article-1272-1-qqmail.html














 102
102











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









