







控制备份片的大小:
1、一次性(通过限制通道,来限制备份片的大小):
run{
allocate channel d1 type disk;
set limit channel di kbytes=10000;
backup datafile 4 format '/bk/%d_%s_%p.bkp';} -----如果我datafile 4的备份有80M,那么这个备份集有8个备份片
2、设置系统的默认配置:
configure channel device type disk maxpiecesize 1G format '/bk/%d_%I_%s_%p_%T.bkp';
控制一个备份集中有多少个数据文件
backup as compressed backupset database format '/bk/%d_%s_%p.bkp' filesperset 3; ---一个备份集3个数据文件
增量备份
2种增量备份策略:
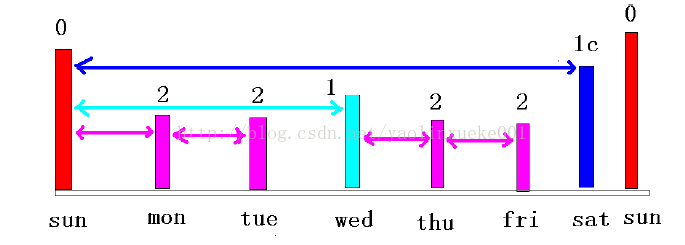
周日:0 周一:2 周二:2 周三:1 周四:2 周五:2 周六:1c 周日:0
元旦:0 每天:4 每周:3 每月:2 每季度:1
backup incremental level 1 datafile 4 format '/bk/%d_%s_%p.bkp'; ------差异增量
backup incremental level 1 cumulative datafile 4 format '/bk/%d_%s_%p.bkp' -----累计增量(1c)
*1c不认1,1认1c
expired(死亡备份)、obsolete(陈旧备份)
expired就是有备份记录,但是没有备份的文件了
obsolete是有多个备份,但是不符合保留策略
crosscheck backup;
delete noprompt expired backup;
crosschek copy;
delete noprompt expired copy;
crosscheck archivelog all;
delete noprompt expired archivelog all;
report obsolete; ---copy和backup都计算
delete noprompt obsolete; ---- 删除陈旧的备份信息和连带的备份物理文件
这里对obsolete特别提一下:obsolete有两个含义:①冗余的 ②过期的
说一下归档和obsolete的关系:比如说我每天晚上做全备份,那么全备份之前的:①归档的备份②归档 都是obsolete(过期的) 也就是说我delete obsolete会删掉他们
**因为归档本身并没有过期不过期之分,它的过期与否是根据数据文件的备份而定的,凡是你的备份可能会用到的归档,就不是过期的!
换句话说就是,"你非冗余最早的数据文件备份之前的归档(归档的备份集)是过期的"! <--------记住这句话就行
如果你的备份都是冗余的,那它就不能算是我上面说的非冗余最早的备份喽~!
所以说用delete obsolete要小心,因为她会删掉你的归档
设定保留策略
configure retention policy to redundancy 3;
configure retention policy to recovery window of 7 days;
----------------------------------------------
备份控制文件:
copy current controlfile to '/bk/c1.ctl';
backup current controlfile format '/bk/c1_%d.ctl';
list copy of controlfile;
list backup of controlfile;
可自动备份控制文件
备份归档日志文件:
list archivelog all;
list copy of archivelog all;
list backup of archivelog all;
list copy of archivelog seqence between 264 and 265 thread 1;
backup archivelog all format '/bk/arc_%d_%T_%U' delete input;
备份二进制文件:
list backup of spfile;
backup spfile format '/bk/spfile.%s';
catalog恢复目录的配置:
1、create tablespace rman datafile '....../rman.dbf' size 20M;
2、create user rman identified by rman default tablespace rman;
3、grant recovery_catalog_owner,connect,resource to rman;
4、DOS> rman catalog rman/rman
5、RMAN>create catalog;
6、rman target sys/managerconfig@tt catalog rman/rman
7、RMAN>register database;
*进入rman时,如果连接catalog,会将备份信息同时保存在控制文件和catalog中;
如果不连接catalog,只会将备份信息保存在控制文件中,等下次连接catalog时,catalog会去读取控制文件的信息。
利用rman恢复换路径
run
{ sql "alter tablespace users offline";
set newname for datafile 4 to '/bk/users.dbf';
restore datafile 4;
switch datafile 4;
recover datafile '/bk/users.dbf';
sql "alter tablespace users online";
}
有rman全备(数据文件,参数文件,控制文件,日志文件),异地恢复
1、还原参数文件: export ORACLE_SID=luyang (这里名字可以自己起,只要把dbs目录下恢复的参数文件的后缀也改了就ok了 <---改实例名就这么改)
用rman启动一个傀儡实例(DUMMY)到nomount下恢复参数文件:RMAN>restore spfile from '/rmanbk/LUYANG_1021439988_4_1_20130226.bkp'
shutdown 假实例
修改参数文件的一些值:如(a,b,c,u)dump、控制文件的路径、归档路径等
2、还原控制文件: SQL>startup nomount
SQL>show parameter name ---看看是不是自己的库
启动rman:RMAN>restore controlfile from '/rmanbk/LUYANG_1021439988_4_1_20130226.bkp' (还原的位置由参数文件里的路径决定)
3、还原数据文件、恢复:
SQL>alter database mount ;
RMAN>list backup;
RMAN>crosscheck backup;
RMAN>delete noprompt expired backup;
RMAN>catalog start with '/rmanbk/';
run{
set newname for datafile 1 to '/u01/oracle/oradata/luyang/system01.dbf';
set newname for datafile 2 to '/u01/oracle/oradata/luyang/undotbs01.dbf';
set newname for datafile 3 to '/u01/oracle/oradata/luyang/sysaux01.dbf';
set newname for datafile 4 to '/u01/oracle/oradata/luyang/users01.dbf';
set newname for datafile 5 to '/u01/oracle/oradata/luyang/example01.dbf';
restore database;
switch datafile all;
recover database;
} ------还在找下面的归档,不用管它
修改日志文件的指针,使之能建立联机日志(因为要resetlogs)
SQL> alter database rename file '/u01/app/oracle/oradata/luyang/redo03.log' to '/u01/oracle/oradata/luyang/redo03.log';
SQL> alter database rename file '/u01/app/oracle/oradata/luyang/redo02.log' to '/u01/oracle/oradata/luyang/redo02.log';
SQL> alter database rename file '/u01/app/oracle/oradata/luyang/redo01.log' to '/u01/oracle/oradata/luyang/redo01.log';
sql>alter database open resetlogs;
大功告成~!
rman 的数据块完全恢复(rman数据块不能不完全恢复)
select * from V$DATABASE_BLOCK_CORRUPTION ;
BLOCKRECOVER DATAFILE 12 BLOCK 12;
数据文件的恢复(在线恢复):
1、数据文件要再offline或者recover状态(如果是在线状态,手动offline)
2、RMAN>restore datafile 4;
3、RMAN>recover datafile 4;
控制文件的恢复(rman没有using backup controlfile):
1、控制文件坏了----数据库崩溃~!
2、从新启动数据库到nomount ,然后进入rman还原控制文件:RMAN>restore controlfile from '/bk/controlfile_TEST.bkp';
3、将数据库启动到mount下:SQL>alter database mount;
4、RMAN>recover database; ---完全恢复
rman的不完全恢复:
1、有rman的全备份
2、drop table t1 purge;
3、日志挖掘找出SCN
4、停止数据库,从新启动到mount
5、进入rman:
RMAN>run{
set until scn 39847;
restore database; ---------rman的restore database是还原所有的数据文件;
recover database;
alter database open resetlogs;
}
rman的数据库副本(incarnation)管理:
list incarnation of database; ----列出共有多少个副本
想要理解incarnation,先要弄明白alter database open resetlogs 和 incarnation的关系
举个例子:
我要进行一次不完全恢复:
1、我有rman的全备份
2、然后我关闭数据库,从新启动到mount
3、RMAN> run{
set until time "to_date('2010-10-16 23:14:42','yyyy-mm-dd hh24:mi:ss')";
restore database;
recover database;
}
Starting restore at 17-OCT-10
。。。。
Finished restore at 17-OCT-10
starting media recovery
。。。。
Finished recover at 17-OCT-10
4、alter database open resetlogs;
5、打开库后,我发现我刚才恢复的时间23:14:42有点早,我想恢复到23:14:50;
6、于是我再次将数据库启动到mount下
7、RMAN> run{
set until time "to_date('2010-10-16 23:14:50','yyyy-mm-dd hh24:mi:ss')";
restore database;
recover database;
}
报错:RMAN-20207: UNTIL TIME or RECOVERY WINDOW is before RESETLOGS time
观察以上这个实验,想想为什么呢?对!因为你用的还那个控制文件,而你做了resetlogs操作后,控制文件中记录日志的sequence号重置了,以前的归档和日志就不认了.
当然如果你有控制文件的备份,可以先恢复控制文件再做不完全恢复。
但是10g以后rman给我们引入了一个新的概念incarnation,我每次resetlogs后incarnation+1,有了它我们就可以更简单的实现上面的实验:
list incarnation;
reset database to incarnation 1;
然后再重复6、7就ok了
登记备份集:
catalog datafilecopy '/bk/user01.cp';
catalog backuppiece '/bk/TT_3_1_20130817.bkp'; (10g 新特性)
catalog start with '/bk/';
补充:不完全恢复:
热备----recover database (using backup control file) until ......; (文件已经cp完)
rman -----RMAN>run{
set until scn 39847;
restore database;
recover database;}
**********************************************************************
附赠一个rman全备份的脚本for AIX:
#!/bin/ksh
exportORACLE_BASE=/opt/oracle
exportORACLE_HOME=/opt/oracle/product/10.2.0/db_1
exportORA_CRS_HOME=/opt/oracle/product/10.2.0/crs_1
exportORACLE_SID=orcl1
export PATH=$PATH:$ORACLE_HOME/bin:$ORA_CRS_HOME/bin:$HOME/bin:/usr/ccs/bin:.
exportLD_LIBRARY_PATH=$ORACLE_HOME/lib:/lib:/usr/lib;
exportCLASSPATH=$ORACLE_HOME/JRE:$ORACLE_HOME/jlib:$ORACLE_HOME/rdbms/jlib;
exportAIXTHREAD_SCOPE=S
exportNLS_LANG=AMERICAN_AMERICA.ZHS16GBK
ly=`/bin/date +%y%m%d`
rman target/ log=/oracle/oradata/rman/rman$ly.log <<EOF
run{
crosscheck backup;
crosscheck archivelog all;
delete noprompt expired backup;
delete noprompt expired archivelog all;
delete noprompt obsolete;
allocate channel c1 type disk;
allocate channel c2 type disk;
sql 'alter system archive log current';
backup as compressed backupset databaseformat '/oracle/oradata/rman/dbfull_%d_%T_%U.bkp';
sql 'alter system archive log current';
backup as compressed backupset archivelogall format '/oracle/oradata/rman/arc_%d_%T_%U' delete all input;
release channel c1;
release channel c2;
delete noprompt obsolete;
}
EOF
echo "backup complete!";
大前提是我CONFIGURE RETENTION POLICY TO REDUNDANCY 1;
1、如上的备份策略如果用蓝色位置,我每天得到的是,一个数据库的全备份(包括数据文件、参数文件、控制文件),和一个归档日志的备份集(该备份集中的归档是上次备份归档日志到这次备份归档日志之间的所有归档),显然这个归档日志的备份集意义不大(因为其中的归档大部分都是本次全备份之前的归档!)~! 虽然这个归档日志的备份集中有非冗余的最早的备份之前的归档,但是该备份集不算obsolete,因为备份集是在本次全备之后完成的
2、如果用粉色的位置,那我每天备份完成会后,会有两套全备份和归档日志的备份,说不明白了。。。看图!
这样看来比第一种要合理一点,起码我3号的归档日志的备份,2号的全备份可以用上。。。。。也就是说我可以恢复2号3:00点到3号3:00之间的任意时间点。。。。
主要是我的保留策略太不科学~(CONFIGURE RETENTION POLICY TO REDUNDANCY 1;) -----生产中最好不好不要冗余1
如果是CONFIGURE RETENTION POLICY TO REDUNDANCY 2;的话,我上面的脚本就可以实现,有3套’黑线‘和‘蓝线’,我3号备份完成后,我可以恢复1号3:00到3号3:00的任意时间点~~
也就是说我redundancy +1,我就能多保留一套备份,我可以恢复的时间就越往前呗~~














 170
170











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









