







非常感谢网上的大神们给出的参考,终于勉强弄懂了,在此自己总结复习一遍,也希望能帮助到大家。
参考:
《KMP算法》
普通算法
提供长字符串P,和短字符串B,要求查出在P中与B相同的子串
最最普通算法:从头开始一个个检测,检测失败则移动到下一个字符再从头开始一个个检测。这个不消多说。
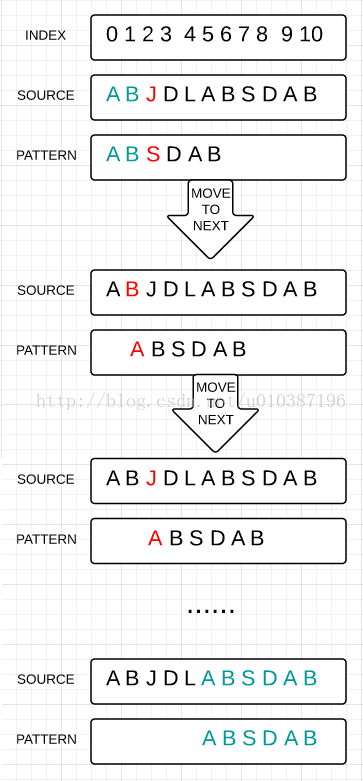
代码:
//最简单粗暴
#include<iostream>
#include<cstring>
using namespace std;
int FirstMatch(const char *source, const char *pattern) {
//返回首次匹配的字符串的首字母在source中的下标
int target_len = strlen(source);
int pattern_len = strlen(pattern);
int i =0, j = 0;
for(i = 0; i < source_len; i++) {
for(j = 0; j < pattern_len; j++) {//从source[i]开始与pattern逐步比较
if(source[i+j] != pattern[j]) {//不匹配
break;
}
if(j == pattern_len - 1)return (i);//完全匹配
}
}
return 0;
}
int main() {
char *source = "dafxfvfxffff\
dshfhashfjkkvhsdjakfacofiiafabffffsd\
fabsfffdjkfhdsfknfffffffckhfajskfab\
ahgoiinclkjadklfsvnsdgiu";
char *pattern = "dsfknffff";
int n = FirstMatch(source, pattern);
cout<<n<<endl;
cout<<source[n]<<endl;
return 0;
}KMP算法:
1.在检测到不匹配时,右移几位?
2.右移之后,从第几位开始检测?
问题一:在检测到不匹配时,右移几位?
首先提供一个特例
P中检测失败前最后一位字符(第j位)没有与其之前的字符重复
S A S D A S X X S D L B
P A S D A S X A
对于上面例子,在P中A处检测失败,之前的A S D A S X是完全一样,检测失败前最后一个字符为X,其之前的字符为A S D A S。
若每次检测失败均右移一位,则source中的X(也是pattern中检测失败前最后一个字符)必将与pattern中的A S D A S依次进行比较
S A S D A S X X S D L B
P A S D A S X A
-------------------------------------
S A S D A S X X S D L B
P A S D A S X A
-------------------------------------
S A S D A S X X S D L B
P A S D A S X A
--------------------------------------
S A S D A S X X S D L B
P A S D A S X A
-------------------------------------
S A S D A S X X S D L B
P A S D A S X A
故若已知P中检测失败前最后一位字符(第j位)没有与之前的字符重复,可右移j位。
这个例子给我们一个启示,能不能用利用已经检测能够匹配的部分来求得移动几位呢?
而已经检测能够匹配的部分必然出现在短字符串pattern中。
再提供一个例子
S A S D A S Z X S D L B
P A S D A S X A
我们获取检测失败前能匹配的部分来观察一下,
A S D A S
检测失败前最后一位字符S在之前的字符中有重复,不能使用上面的方法。
不考虑算法,先用肉眼进行观察,我们首先想到一次移动成下面的样子进行比较:
S A S D A S Z X S D L B
P A S D A S X A
那么如何实现这一移动呢?
我们已知检测失败前能匹配的部分A S D A S在pattern和source中均有出现,这个移动即是找到与开头某一子串(前缀)重复的部分(前后缀重复部分,或者说头部和尾部的重复部分)如A S D A S,移动到重复部分的开始,即移动总长度减去后部分重复子串长度,在这里是5 - 2 = 3。
S A S D A S Z X S D L B
P A S D A S X A
这样表现是不是更好理解了?
于是KMP算法计算一个匹配表,计算每一个前缀中出现的前后缀相同的最大字符串的长度。
如:010010中出现的左右相同的字符串有:
010010长度:1
010010长度:3
取最长的010的长度3作为第6个字符0的匹配数
如下pattern的匹配表next[]:
j 0 1 2 3 4 5 6
P[j] A S D A S X A
next[j] -1 0 0 0 1 2 0
求next[4]则取前4位 A S D A 找出头尾部重复部分最长的子串为A,取其长度1。
右移量则是j - next[j],因为这里j相当于长度。
另外,还记得我提供的第一个例子么?
“P中检测失败前最后一位字符(第j位)没有与其之前的字符重复”
这种状态有没体现在匹配表中呢?哦,next[j] = 0的(头尾部没有重复子串)情况就包括它啦。
求得next的代码如下:
int *GetNext(const char *str, const int len) {
//获取next数组
int *next = new int [len];
memset(next, 0, sizeof(next));
next[0] = -1;
int i = -1, j = 0;
while(j < len) {
if(i == -1 || str[i] == str[j]) {
i++;j++;
next[j] = i;
}
else i = next[i];
}
return next;
}next数组的求法
问题可以理解成:
假设已知next[i] == j,那么就意味着P[0, j-1](P[0]~P[j-1]) == P[i - j, i -1],求next[i+1]。
如下求next[6],已知next[5] = 2.则i=5,j=2,P[0,1] = P[3,4]
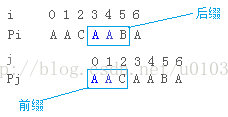
如果S[j] == S[i],那么简单,next[i] = j+1,因为j已经是上一位的最大匹配长度了,这里只是多了一位相同字符,故只需要简单加一即可。
如果S[j] != S[i],那就要减小j的值,即减小作为基础的上一位最大匹配长度,因为前后缀在加上S[j]和S[i]后已经不匹配了,减少到多少呢?减小到next[j]。即向右滑动(减小前后缀)到下一个匹配处,这时再比较S[next[j]]和S[i],重复以上直至长度减少到-1,说明没有匹配的,赋值为0。
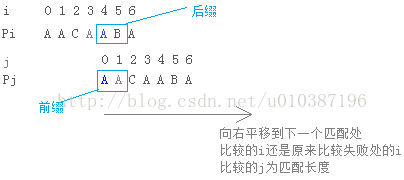
问题二:右移之后,从第几位开始检测?
理解了问题一,问题二就不是什么大问题了。
还是这个例子
S A S D A S X X S D L B
P A S D A S X A
我们已经求得了其匹配表
j 0 1 2 3 4 5 6
P[j] A S D A S X A
next[j] -1 0 0 0 1 2 0
从S[ 0], P[ 0]开始
i 0 1 2 3 4 5 6 7 8 9 10
S A S D A S Z X S D L B
j 0 1 2 3 4 5 6
P A S D A S X A
在i= 5,j = 5处检测到失败,next[j=5] = 2故向右移动j - next[j] = 5 - 2 = 3。
i 0 1 2 |3 4 5 6 7 8 9 10
S A S D |A S Z X S D L B
j |0 1 2 3 4 5 6
P |A S D A S X A
本来应该从头(j = 0)再开始比较的
但是这时候,我们早就从匹配表中得知了next[j]即相同子串(AS)的长度为2,于是AS就不用比较了,直接跳过2长度开始比较,即j=next[j]=2,重新比较时从原先S比较失败处S[5]处开始比较。
i 0 1 2 |3 4 5 6 7 8 9 10
S A S D |A S Z X S D L B
j |0 1 2 3 4 5 6
P |A S D A S X A
于是从S[i=0],P[j=0]开始比较,匹配则i++,j++,匹配失败则i不变,j=next[j](注意next[i] = -1的情况,此时应该i++)。继续比较,直至i >= s_length或者j >= p_length。若结束后j==p_length,说明完全匹配,否则就是找不到。
代码
int KMP_match(const char * source,const int sourceLen,
const char * patt, const int pattLen) {
//返回首次完全匹配的头字符在source中的下标
int * next = GetNext(patt, pattLen);
int i =0, j =0;
while(i < sourceLen && j < pattLen) {//i代表source中下标,j代表patt中下标
if(source[i] != patt[j]) {
//在patt[j],source[i]处比较失败
//右移j-next[j],从next[j]和i开始比较
//单独处理next[j] == -1
if(next[j] == -1) i++;
else {
j = next[j];
}
}
else {
j ++;i++;
}
}
//释放内存
if(next != NULL) {
delete[] next;
next = NULL;
}
if(j == pattLen) return i-pattLen;
else return -1;//没有找到
}测试:
加上上面两个代码以及头文件
#include<iostream>#include<cstring>
using namespace std;
再加上此测试代码
int main() {
char * str1 = "dafxfvfxfffffihblanbflajgaincoa\
dshfhashfjkkvhsdjakfacofiiafabffffsdjkyfoldfljka\
fabsfffdjkfhdsfknfffffffckhfajskfabsdjkfhasffffdfafffg\
ahgoiinclkjadklfsvnsdgiu\
haigaklsdnkncadjkkskannc";
char * str2 = "ffffckhf";
int len1 = strlen(str1);
int len2 = strlen(str2);
int n = KMP_match(str1,len1,str2,len2);
//输出测试
if(n != -1){
cout<<n<<" ";
for(int i = 0; i < len2; i++) {
cout<<str1[n+i];
}
cout<<endl;
}
else cout<<"Not Found!"<<endl;
return 0;
}
初生牛犊,如有错误,还望不吝指教。














 7232
7232











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









