









 HDFS是一个适合大型文件、流式数据读取的分布式文件系统,常部署于廉价硬件上。它不适合小文件存储、实时读取和频繁数据修改。架构包含Client、NameNode、Secondary NameNode和DataNode,其中NameNode存储元数据,DataNode存储实际数据,Secondary NameNode协助NameNode工作。
HDFS是一个适合大型文件、流式数据读取的分布式文件系统,常部署于廉价硬件上。它不适合小文件存储、实时读取和频繁数据修改。架构包含Client、NameNode、Secondary NameNode和DataNode,其中NameNode存储元数据,DataNode存储实际数据,Secondary NameNode协助NameNode工作。
HDFS是一个具有高度容错性的分布式文件系统,适合部署在廉价的机器上,它具有以下几个特点:
1)适合存储非常大的文件
2)适合流式数据读取,即适合“只写一次,读多次”的数据处理模式
3)适合部署在廉价的机器上
但HDFS不适合以下场景(任何东西都要分两面看,只有适合自己业务的技术才是真正的好技术):
1)不适合存储大量的小文件,因为受Namenode内存大小限制
2)不适合实时数据读取,高吞吐量和实时性是相悖的,HDFS选择前者
3)不适合需要经常修改数据的场景
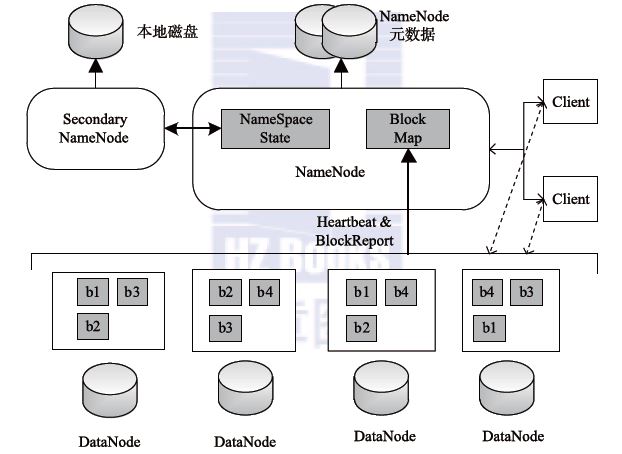
HDFS的架构如上图所示,总体上采用了Master/Slave的架构,主要有以下4个部分组成:
1、Client
2、NameNode
整个HDFS集群只有一个NameNode,它存储整个集群文件分别的元数据信息。这些信息以fsimage和editlog两个文件存储在本地磁盘,Client通过这些元数据信息可以找到相应的文件。此外,NameNode还负责监控DataNode的健康情况,一旦发现DataNode异常,就将其踢出,并拷贝其上数据至其它DataNode。
3、Secondary NameNode
Secondary NameNode负责定期合并NameNode的fsimage和editlog。这里特别注意,它不是NameNode的热备,所以NameNode依然是Single Point of Failure。它存在的主要目的是为了分担一部分NameNode的工作(特别是消耗内存的工作,因为内存资源对NameNode来说非常珍贵)。
4、DataNode
DataNode负责数据的实际存储。当一个文件上传至HDFS集群时,它以Block为基本单位分布在各个DataNode中,同时,为了保证数据的可靠性,每个Block会同时写入多个DataNode中(默认为3)
想了解MapReduce的架构设计,可以参考另外一篇文章介绍MapReduce架构:http://blog.csdn.net/u010415792/article/details/9056129















 1650
1650

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









