







决策树<Decision Tree>是一种预测模型,它由决策节点,分支和叶节点三个部分组成。决策节点代表一个样本测试,通常代表待分类样本的某个属性,在该属性上的不同测试结果代表一个分支;分支表示某个决策节点的不同取值。每个叶节点代表一种可能的分类结果。
使用训练集对决策树算法进行训练,得到一个决策树模型,利用模型对未知样本(类别未知)的类别判断时,从决策树根节点开始,从上到下搜索,直到沿某分支到达叶节点,叶节点的类别标签就是该未知样本的类别。
网上有个例子可以很形象的说明利用决策树决策的过程(母亲给女儿选对象的过程),如下图所示:
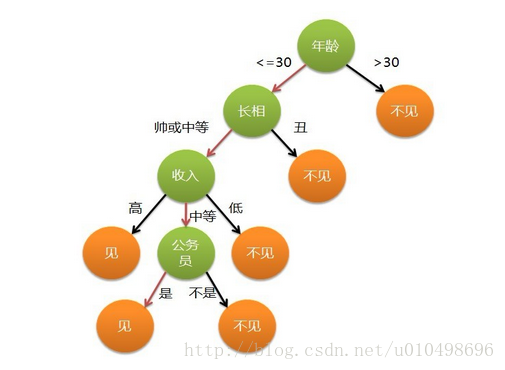
女儿:多大年纪了?
母亲:26。
女儿:长的帅不帅?
母亲:挺帅的。
女儿:收入高不?
母亲:不算很高,中等情况。
女儿:是公务员不?
母亲:是,在税务局上班呢。
女儿:那好,我去见见。
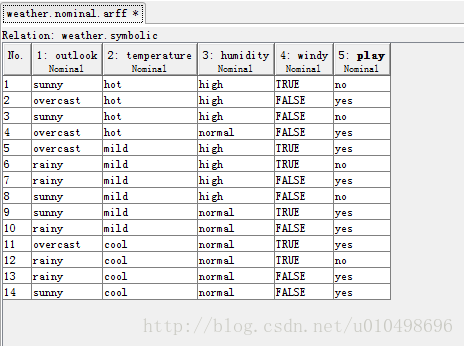
再看一个例子:数据集如下图所示,共有14个样本,每个样本有4个属性,分别表示天气,温度,湿度,是否刮风。最后一列代表分类结果,可以理解为是否适合出去郊游(play)。
下面是利用上面样本构建的决策树:
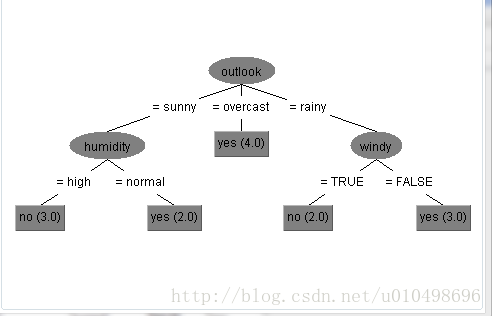
根据构建的模型,当再来一个样本<outlook = rainy, temperature = cool,humidity = normal windy = true>那么我们就可以从根节点开始向下搜索最后得到:no play。
仔细思考下,这有点类似FP-Tree算法中的构造树过程,但是绝不一样。事实上,相同的数据集,我们可以构建很多棵决策树,也不一定以outlook 作为根节点。FP-Tree只是单纯将所有样本信息存储到一个树上,而决策树显然有一个选取节点属性进行分类的过程。那么问题来了?该如何选取属性作为分类属性,将样本分为更小的子集?什么时候结束终止决策树的增长,使构建的决策树既对训练样本准确分类,而且对于未知样本(测试样本)也能够准确预测,可能的策略是所有的样本都属于同一类别或所有样本属性值都相等。
不同的决策树算法采用的策略不同,下面主要介绍C4.5 算法,主要学习C4.5选取节点划分子集的策略。
C4.5算法是由澳大利亚悉尼大学Ross Quinlan教授在1993年基于ID3算法的改进提出的,它能够处理连续型属性或离散型属性的数据;能够处理具有缺失值的属性数据;使用信息增益率而不是信息增益作为决策树的属性选择标准;对生成枝剪枝,降低过拟合。
如下为决策树算法框架:
TreeGrowth(E, F)//E--训练集 F—属性集
if stopping_cond(E, F) = true then //达到停止分裂条件(子集所有样本同为一类或其他)
leaf = createNode() //构建叶子结点
leaf.label = Classify(E) //叶子结点类别标签
return leaf
else<span style="white-space:pre">
root = createNode()<span style="white-space:pre"> //创建结点
root.test_cond = find_best_split(E, F) 确定选择哪个属性作为划分更小子集//
令 V = {v | v是root.test_cond 的一个可能的输出}
for each v V do
Ev = {e | root.test_cond(e) = v and e E}
child = TreeGrowth(Ev, F)
//添加child为root的子节点,并将边(root——>child)标记为v
end for
end if
return root主要过程:首先用根节点代表一个给定的数据集;然后从根节点开始(包括根节点)在每个节点上选择一个属性,使结点数据集划分(一棵树分裂为几棵树)为更小的子集(子树);直到使用某个属性,其子集中所有样本都属于一个类别,才停止分裂。
而其中节点如何选择属性,正是C4.5要做的。
前面已经提到过:C4.5 使用信息增益率而不是信息增益作为决策树的属性选择标准。下面从熵开始逐步解释:
熵:信息论中对熵的解释,熵确定了要编码集合S中任意成员的分类所需要的最少二进制位数
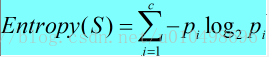
pi 为集合S中第i类所占的比例。(具体举例见后面实例)
理解”最少”:
1. 对于2分类问题,用一个二进制位1和0描述足以分类;对于4分类问题,至少需要用两个二进制位描述00 01 10 11;c分类 log2(c)
2. 对于分类问题,还要考虑类的比例(样本不平衡问题),m+n个样本其中m个样本分类表示的二进制位数和n个样本表示的二进制位数不相同,所有熵的定义还存在着一种加权平均的思想。
简单来说,它刻画了任意样本集的纯度,越纯,熵越小。
换句话说,“变量的不确定性越大,熵就越大,一个系统越是有序,信息熵就越低(百度百科)
对于二分类问题,熵在[0,1]之间,如果所有样本都属于同一类,熵为0,这个时候给定一个样本,类别就是确定的。如果不同的样本各占一半,熵为1=1/2+1/2,这个时候如果给定一个样本来分类,就完全无法确定了,就好像我们抛硬币完全无法预测它是正面还是反面朝上一样。
对于c分类问题,熵在[0 log2(c)]之间。
C4.5中用到的几个公式:
1 训练集的信息熵
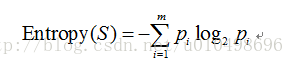
其中 m代表分类数,pi为数据集中每个类别所占样本总数的比例。
2 划分信息熵----假设选择属性A划分数据集S,计算属性A对集合S的划分信息熵值
case 1:A为离散类型,有k个不同取值,根据属性的k个不同取值将S划分为k各子集{s1 s2 ...sk},则属性A划分S的划分信息熵为:(其中 |Si| |S| 表示包含的样本个数)
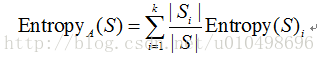
case 2: A为连续型数据,则按属性A的取值递增排序,将每对相邻值的中点看作可能的分裂点,对每个可能的分裂点,计算:
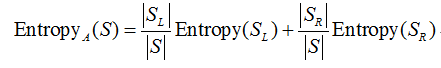
其中,SL和SR分别对应于该分裂点划分的左右两部分子集,选择EntropyA(S)值最小的分裂点作为属性A的最佳分裂点,并以该最佳分裂点按属性A对集合S的划分熵值作为属性A划分S的熵值。
3 信息增益
按属性 A划分数据集 S的信息增益Gain(S,A)为样本集 S的熵减去按属性 A划分 S后的样本子集的熵,即
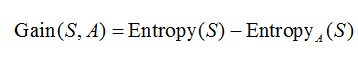
4 分裂信息
利用引入属性的分裂信息来调节信息增益
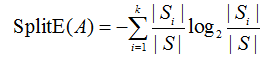
5 信息增益率
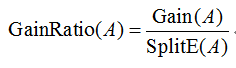
信息增益率将分裂信息作为分母,属性取值数目越大,分裂信息值越大,从而部分抵消了属性取值数目所带来的影响。
相比ID3直接使用信息熵的增益选取最佳属性,避免因某属性有较多分类取值因而有较大的信息熵,从而更容易被选中作为划分属性的情况。公式略多,看得眼花缭乱,其实就是为了得到信息增益率。
下面以博客开始介绍的天气数据集为例,进行属性选取。
具体过程如图所示:


根节点选取outlook属性后就得到如下划分:
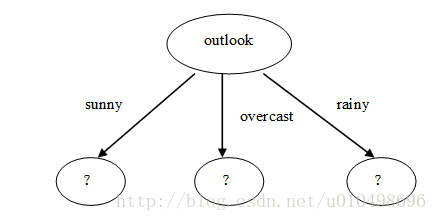
递归进行如上过程,就得到了博客开头的决策树。
本文引用了部分《数据挖掘与机器学习WEKA应用技术与实践》中的内容,并修改了原书中决策树计算错误之处,书中outlook的信息增益率为0.44是错误的。
转载请申明: http://blog.csdn.net/u010498696/article/details/46333911
参考文献: 《数据挖掘与机器学习WEKA应用技术与实践》














 6409
6409











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









