







-这是 小明同学 2018年第 1 篇文章-
#废话慎读
随着微信小游戏的出现,最近各种外挂又开始盛行了,听到的最多的外挂就是《跳一跳》的外挂了,看似很简单的游戏,但是玩儿起来却一点都不简单,我也像很多人一样,当分数越高,就会越紧张,至今为止自己玩儿还从未突破过200分,是不是很菜,看到朋友圈那么多好几千分的,自己也不甘心,于是就各种倒腾外挂,开始刷分,刷排名。一个同学问我,很多人都玩儿到了好几千分,这些人也太无聊了,听到这句话,真是笑出了声,她居然不知道有外挂这种东西。外挂盛行之后,腾讯也各种打击外挂,后来就发现朋友圈的分数没有以前那么离谱的高了,在微信公开课上,张小龙,居然说自己最高分数是6000多分,而现场也是当众玩儿到了900多分,这该是一种什么心态,他说这款游戏本来是让大家放松玩儿的,但是大多数人却分数越高越紧张,很容易就死掉了。也有人说,用个外挂,刷那么高的分数,有什么意思,实际上的确没啥意思,其实有意思的并不是刷那么高的分,而是外挂本身,他是怎么实现自己玩那么高分儿的,原理是什么,该如何实现,作为一名程序员,这才是我们要玩儿的东西,分数多少,排名高低,都不重要,重要的是图一乐呗。
其实原理很简单,我并没有仔细研究过github上的外挂的源代码,也是因为懒的原因吧,我只是在我自己机器上跑了起来,当然也入了很多坑,因为当时用的是python版的,而自己并不是用python做开发的,所以很多东西都是现查现使用。最后也只是把安卓的搞定了,IOS更是一窍不通,各种安装,最后还是报错了,也没再去管他。
最近《冲顶大会》,让很多人拿钱拿到手软,我也一样,到现在一分钱也没得到,实在是太笨了,于是乎我就想,这要是有外挂就好了,那真是太爽了,但是这种题目有时间限制的,外挂其实还是比较困难的,因为响应的时间可能会超出题目规定的答题时间,但也只是起到一个辅助的作用,而且有的题目也并不是能直接找到答案的,比如:下面4个选项中哪个答案是错误的(),这种怎么去搜索,所以外挂这种东西啊玩玩儿就好了,还是要靠真材实料。
同样的在小程序里面也有款类似的游戏《头脑王者》,拿它当作实验,自己做一个外挂,但是对我来说并未那么简单,其实学习python也有一段时间了(不应该这么说,是从开始看python已经很久了,但至于学了多少了,就不多说了,实在是太懒了。。。),但还是想用它来实现这个小小的外挂,下面就开始切入正题。
我们先来分析下流程,其实跟《跳一跳》外挂很相似,首先我们还是要去截图,题目界面如下图所示:
截完图后,将题目的题干和答案取出,这里也就会用到图像识别了,然后去百度或其他搜索引擎去搜索题目,得到正确答案和选项比较,最终返回正确答案,通过坐标我们也可以知道每个选项的大体位置,然后再去模拟点击答案,完成操作。其实步骤就是这么简单。
开始->截图->识别文字->搜索题目并返回答案->模拟点击答案->结束
开发工具:PyCharm 2017.3
开发语言:Python 3.6
开发环境:MacOS
图像识别:腾讯优图AI 通用ORC识别模块 地址:http://open.youtu.qq.com/#/develop/api-ocr-general
调试工具:adb 关于adb在mac上如何使用请查看我简书上一片杂乱的文章,地址:https://www.jianshu.com/p/2a0cb004792d
测试手机:锤子坚果Pro
搜索引擎:百度 or 必应
OK,下面我们进入正题,我们创建一个名为MindKing(大概是头脑王者的英文名吧,请忽略)的项目,创建一个Python脚本MindKingExt.py,然后将优图的OCR识别模块引入到项目中,大概就是酱紫:
创建完成后,下面我们完成第一个任务,手机截屏
关于手机截屏并保存,熟悉安卓开发的朋友应该都很清楚,使用使用adb的相关命令即可,我们可以直接在控制台来测试,首先我们查看手机是否连接成功(手机需要打开开发者模式,并开启USB调试,这些应该都不用说了),使用 adb devices 如果连接成功是介样的
adb shell screencap -p
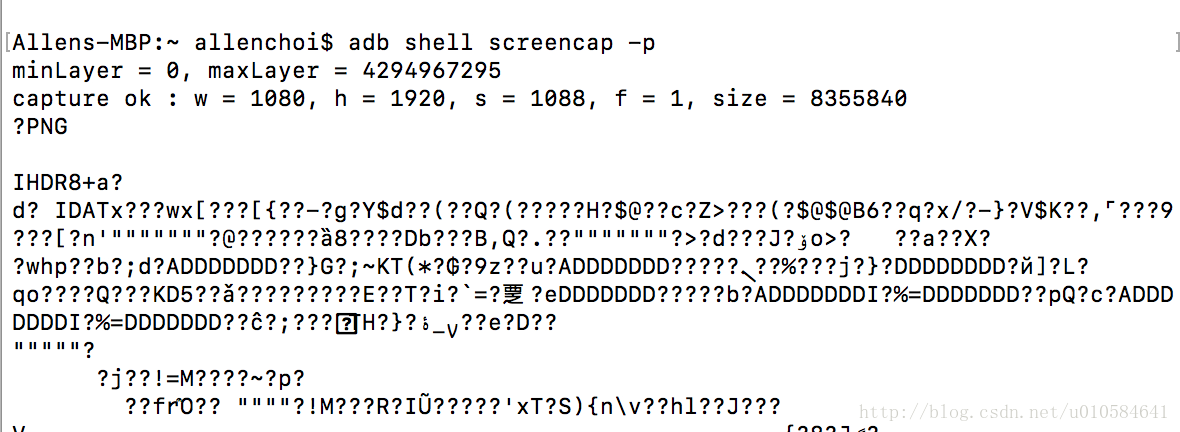
没错会出现一堆乱码,并且显示了截图的宽高等信息,下一步我们将此命令在我们的程序中执行,首先需要导入一个模块,它的名字叫做创建附加进程模块,subprocess,在这里我们使用的是它的直接处理管道的方法,叫做subprocess.Popen(),如何使用它执行截屏呢,代码如下:
# 第一个参数为命令行,安卓手机截屏命令;
# 第二个参数shell=True,在Windows下表示cmd.exe /c即在这里执行的是cmd命令;
# 第三个参数建立管道,这里通过将stdout重定向到subprocess.PIPE上来取得adb命令的输出
process = subprocess.Popen('adb shell screencap -p', shell = True, stdout = subprocess.PIPE)# 读取二进制数据
screenshot = process.sdtout.read()# 可直接保存至文件
with open('screenshot.png','wb') as f:
f.write(screenshot)
因为这样势必会浪费时间,我们本来答题是有时间限制的,而直接保存图片会耗费不必要的时间,所以在这里我们可以把图片加载到内存中操作,保存至内存需要引入另一个模块BytesIO ,它支持的是二进制数据,如果要将字符串写入内存的话要使用StringIO,如何使用这个模块呢,首先创建一个变量指向这个对象,再把刚才读取到的二进制数据写入这个变量中,
# 将二进制读进内存中
imgbyte = BytesIO()
imgbyte.write(screenshot)
上下两个红色框标注的内容就是我们想要的了,关于这个坐标的定位,在画图工具中可以直接显示,大家请根据自己的手机的分辨率自行调节,这里给出我使用的手机的大体位置坐标(实际上这个也不是我自己截取的,从别处看到的正好也是我手机的分辨率\ganga\),为了方便我们将截取图片相应的参数单独放到配置信息里面,
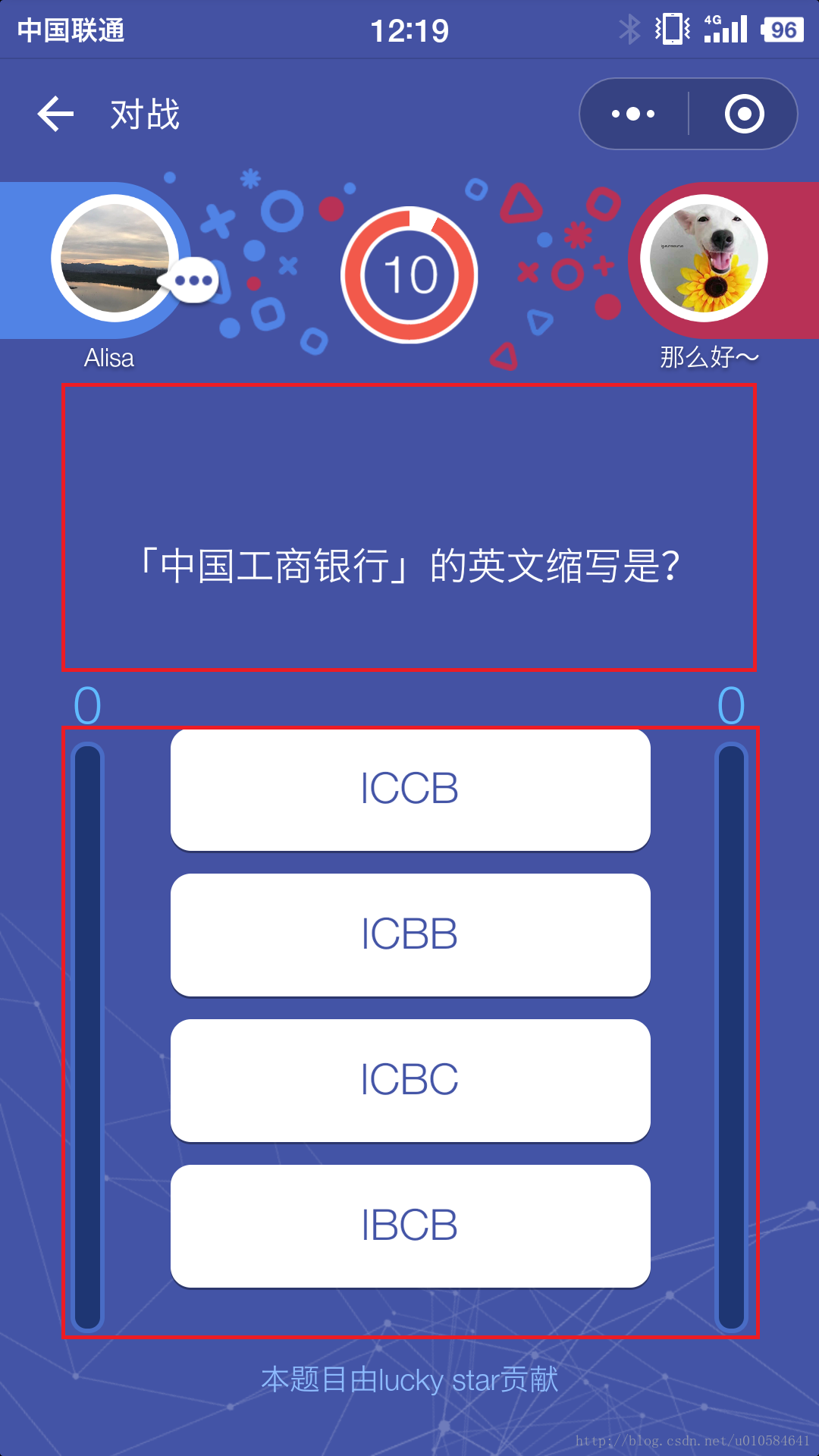
# 配置坐标信息,根据手机分辨率的不同调整,此坐标可适用于1080 X 1920
config = {
'头脑王者':{
'title': (80, 500, 1000, 880),
'answer': (80, 960, 1000, 1720),
'point': [
(316, 993, 723, 1078),
(316, 1174, 723, 1292),
(316, 1366, 723, 1469),
(316, 1570, 723, 1657)
]
}
} # 图片处理
img = Image.open(imgbyte)
# 切出题目,左上角,右下角的点
img_Prob = img.crop((config['头脑王者']['title']))
# 切出答案,左上角,右下角
img_Ans = img.crop((config['头脑王者']['answer']))
# 拼接
new_img = Image.new('RGBA', (920, 1140)) #创建一个新的画布,宽920,高1140
new_img.paste(img_Prob, (0, 0, 920, 380))
new_img.paste(img_Ans, (0, 380, 920, 1140)) # 内存对象
new_img_byte = BytesIO()
#保存为png格式至内存中
new_img.save(new_img_byte, 'png')
看样子应该是达到了我们预期的效果,最后我们将这个对象返回 return new_img_byte 。继续下一步操作,识别图像。关于识别图像,我用的是腾讯的优图AI开放平台的通用OCR识别,关于这个的使用呢,大家可以直接去官网看官方文档,用法也都很简单,返回的数据也都是标准的json对象,处理起来也很方便,下面直接贴代码了:
# 这里使用的是腾讯的优图开放平台的图像识别SDK,该appid应该会有上弦,具体不知,如果不能使用了,请自行申请更换
""" 以下为开放平台返回的识别文本,题目和答案根据此内容解析
{
"errorcode":0,
"errormsg":"OK",
"items":
[
{
"itemstring":"手机",
"itemcoord":{"x" : 0, "y" : 1, "width" : 2, "height" : 3},
"words": [{"character": "手", "confidence": 98.99}, {"character": "机", "confidence": 87.99}]
},
{
"itemstring":"姓名",
"itemcoord":{"x" : 0, "y" : 1, "width" : 2, "height" : 3},
"words": [{"character": "姓", "confidence": 98.99}, {"character": "名", "confidence": 87.99}]
}
],
"session_id":"xxxxxx"
"""
appid = '10115709'
secret_id = 'AKIDY0HNJ482FJI8mJcqpdIpCPQFwTs6d2kM'
secret_key = 'fAVfdP1Rlur03vfifR0U5Y1Qwv2yiWHs'
userid = 'myApp1' # 自行命名,以上三个参数均在开放平台申请
end_point = TencentYoutuyun.conf.API_YOUTU_END_POINT # 优图开放平台
youtu = TencentYoutuyun.YouTu(appid, secret_id, secret_key, userid, end_point)
with open('screenshot.png', 'wb') as fileReader:
fileReader.write(img.getvalue())
# 在执行generalocr()方法时,由于request对象的问题,返回中文时乱码,需要手动再指定返回对象的编码格式:r.encoding='utf-8' 详见youtu,py脚本文件
ocrinfo = youtu.generalocr('screenshot.png', 0)
# print(ocrinfo['items'])
return ocrinfo['items']{
'errorcode': 0,
'errormsg': 'OK',
'items': [{
'itemcoord': {
'x': 109,
'y': 219,
'width': 705,
'height': 53
},
'itemstring': '「中国工商银行」的英文缩写是?',
'coords': [],
'words': [{
'character': '「',
'confidence': 0.9919068813323975
}, {
'character': '中',
'confidence': 0.9999942779541016
}, {
'character': '国',
'confidence': 0.9999985694885254
}, {
'character': '工',
'confidence': 0.9998493194580078
}, {
'character': '商',
'confidence': 0.9999986886978149
}, {
'character': '银',
'confidence': 0.999992847442627
}, {
'character': '行',
'confidence': 0.9999927282333374
}, {
'character': '」',
'confidence': 0.993008017539978
}, {
'character': '的',
'confidence': 0.9999935626983643
}, {
'character': '英',
'confidence': 0.9999959468841553
}, {
'character': '文',
'confidence': 0.9999784231185913
}, {
'character': '缩',
'confidence': 0.9995788931846619
}, {
'character': '写',
'confidence': 0.9999926090240479
}, {
'character': '是',
'confidence': 0.9999960660934448
}, {
'character': '?',
'confidence': 0.9996994733810425
}],
'candword': []
}, {
'itemcoord': {
'x': 397,
'y': 436,
'width': 126,
'height': 47
},
'itemstring': 'ICCB',
'coords': [],
'words': [{
'character': 'I',
'confidence': 0.732905924320221
}, {
'character': 'C',
'confidence': 0.9993401169776917
}, {
'character': 'C',
'confidence': 0.9990763664245605
}, {
'character': 'B',
'confidence': 0.9994719624519348
}],
'candword': []
}, {
'itemcoord': {
'x': 398,
'y': 627,
'width': 125,
'height': 45
},
'itemstring': 'ICBB',
'coords': [],
'words': [{
'character': 'I',
'confidence': 0.8364823460578918
}, {
'character': 'C',
'confidence': 0.9991937279701233
}, {
'character': 'B',
'confidence': 0.9999769926071167
}, {
'character': 'B',
'confidence': 0.9999263286590576
}],
'candword': []
}, {
'itemcoord': {
'x': 399,
'y': 819,
'width': 125,
'height': 45
},
'itemstring': 'ICBC',
'coords': [],
'words': [{
'character': 'I',
'confidence': 0.8958392143249512
}, {
'character': 'C',
'confidence': 0.9992052912712097
}, {
'character': 'B',
'confidence': 0.9998654127120972
}, {
'character': 'C',
'confidence': 0.9920558333396912
}],
'candword': []
}, {
'itemcoord': {
'x': 397,
'y': 1010,
'width': 126,
'height': 46
},
'itemstring': 'IBCB',
'coords': [],
'words': [{
'character': 'I',
'confidence': 0.6056796312332153
}, {
'character': 'B',
'confidence': 0.9954431056976318
}, {
'character': 'C',
'confidence': 0.9996951818466187
}, {
'character': 'B',
'confidence': 0.9998865127563477
}],
'candword': []
}],
'session_id': '',
'angle': 0.0
} # 分割题目和答案
answers = [x['itemstring'] for x in infos[-4:]] # 后4项为答案
question = ''.join([x['itemstring'] for x in infos[:-4]]) # 前面为题目「中国工商银行」的英文缩写是?
['ICCB', 'ICBB', 'ICBC', 'IBCB']# url = 'https://www.baidu.com/s' # 百度搜索
url = 'https://www.bing.com/search' # 必应搜索
# 请求头文件
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_2) AppleWebKit/604.4.7 (KHTML, like Gecko) Version/11.0.2 Safari/604.4.7'
}
data = {
# 'wq':question 百度搜索
'q': question # 必应搜索
}
response = requests.get(url,params=data,headers=headers)
response.encoding = 'utf-8'
# 返回请求的文本
html = response.text
# print(html)
# 查找答案并按照答案出现的次数排序
for i in range(len(answers)):
answers[i] = (html.count(answers[i]),answers[i],i)
answers.sort(reverse=True)
# 打印输出题目和答案
print(question)
print(answers)
# 返回正确答案,即第一个答案
return answers[0]「中国工商银行」的英文缩写是?
[(2, 'ICBC', 2), (0, 'ICCB', 0), (0, 'ICBB', 1), (0, 'IBCB', 3)] cmd = 'adb shell input swipe %s %s %s %s %s' %(
point[0],
point[1],
point[0]+random.randint(0,3), # 右下角的坐标随机点击
point[1]+random.randint(0,3), # 右下角的坐标随机点击
200 # 延迟200ms
)
# 执行cmd命令,根据指定的坐标在手机上模拟点击
os.system(cmd)最后一步我们也完成了,这样一个简单的外挂就实现了,当然它也只是一个辅助性的工具,因为实测,耗费时间太长,总是让别人抢先了,但这并不重要,重要的是实现它的乐趣。
太晚了,睡觉了,晚安。
源码地址:https://github.com/Allen0910/MindKing 有问题请提Issue,谢谢!
最后再说一句,哎呀,CSDN的UI换了啊,看来是招到前端了!!!














 3737
3737











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









