







RNN学习笔记
参考cs224d Lecture 7:Recurrent Neural Networks
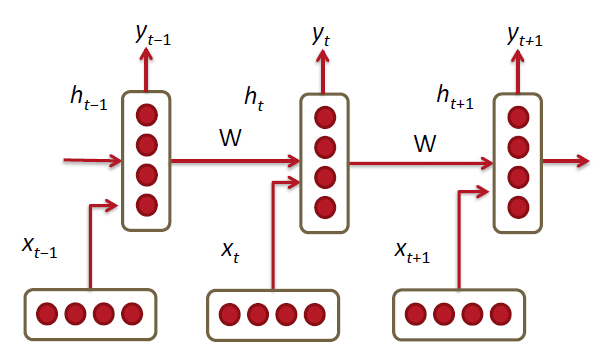
RNN层数
RNN不是单隐层的神经网络,对于
xt−1
来说,其到输出
yt+1
经过了3个隐层。仅对于
xt−1
和
yt+1
来说,当去掉其它的
x
和
对RNN记忆前面层信息的理解
以序列标注为例,与原始MLP不同,RNN对每个序列中的每个
x
向量区分处理,与当前时刻向量
输入输出意义
在该实例中,每个输入的
损失函数
损失函数定义为
最大似然估计
最大似然估计是频率学派中用于优化参数的方法。频率学派认为对于一个给定问题,参数是确定的,而我们观测到的样本是随机变量。(贝叶斯学派相反,认为样本确定,参数是随机变量。)最大似然估计是通过调整参数,使得给定对应参数情况下观测到的样本出现的概率最大,从而求得最优化参数的方法。其中的似然(likelihood)指在给定参数和特征的情况下,观测到样本出现的概率。
严格来说是使得在经验分布的时候观测到样本出现概率最大,使得我们假设的模型逼近经验分布,而当样本所取数目足够多的时候,经验分布就会逼近实际分布。这里经验分布指的是样本集合中的分布。
最大似然的公式为:
以上内容均为个人理解,如有疏漏,敬请指正!














 1811
1811











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









