







 本文详细介绍了如何使用OpenCV进行性别识别项目的样本创建、分类器训练过程,包括正负样本的准备、使用CreateSamples转换样本、haartraining进行训练等关键步骤,旨在帮助读者掌握自定义分类器的训练技巧。
本文详细介绍了如何使用OpenCV进行性别识别项目的样本创建、分类器训练过程,包括正负样本的准备、使用CreateSamples转换样本、haartraining进行训练等关键步骤,旨在帮助读者掌握自定义分类器的训练技巧。
最近要做一个性别识别的项目,在人脸检测与五官定位上我采用OPENCV的haartraining进行定位,这里介绍下这两天我学习的如何用opencv训练自己的分类器。在这两天的学习里,我遇到了不少问题,不过我遇到了几个好心的大侠帮我解决了不少问题,特别是无忌,在这里我再次感谢他的帮助.
一、简介
目标检测方法最初由Paul Viola [Viola01]提出,并由Rainer Lienhart [Lienhart02]对这一方法进行了改善。该方法的基本步骤为: 首先,利用样本(大约几百幅样本图片)的 harr 特征进行分类器训练,得到一个级联的boosted分类器。分类器中的”级联”是指最终的分类器是由几个简单分类器级联组成。在图像检测中,被检窗口依次通过每一级分类器, 这样在前面几层的检测中大部分的候选区域就被排除了,全部通过每一级分类器检测的区域即为目标区域。
分类器训练完以后,就可以应用于输入图像中的感兴趣区域的检测。检测到目标区域分类器输出为1,否则输出为0。为了检测整副图像,可以在图像中移动搜索窗口,检测每一个位置来确定可能的目标。 为了搜索不同大小的目标物体,分类器被设计为可以进行尺寸改变,这样比改变待检图像的尺寸大小更为有效。所以,为了在图像中检测未知大小的目标物体,扫描程序通常需要用不同比例大小的搜索窗口对图片进行几次扫描。
目前支持这种分类器的boosting技术有四种: Discrete Adaboost, Real Adaboost, Gentle Adaboost and Logitboost。”boosted” 即指级联分类器的每一层都可以从中选取一个boosting算法(权重投票),并利用基础分类器的自我训练得到。
根据上面的分析,目标检测分为三个步骤:
1、 样本的创建
2、 训练分类器
3、 利用训练好的分类器进行目标检测。
二、样本创建
训练样本分为正例样本和反例样本,其中正例样本是指待检目标样本,反例样本指其它任意图片。
负样本
负样本可以来自于任意的图片,但这些图片不能包含目标特征。负样本由背景描述文件来描述。背景描述文件是一个文本文件,每一行包含了一个负样本图片的文件名(基于描述文件的相对路径)。该文件创建方法如下:
采用Dos命令生成样本描述文件。具体方法是在Dos下的进入你的图片目录,比如我的图片放在D:\face\posdata下,则:
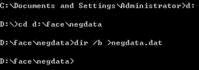
按Ctrl+R打开Windows运行程序,输入cmd打开DOS命令窗口,输入d:回车,再输入cd D:\face\negdata进入图片路径,再次输入dir /b > negdata.dat,则会图片路径下生成一个negdata.dat文件,打开该文件将最后一行的negdata.dat删除,这样就生成了负样本描述文件。dos命令窗口结果如下图:

正样本
对于正样本,通常的做法是先把所有正样本裁切好,并对尺寸做规整(即缩放至指定大小),如上图所示:
由于HaarTraining训练时输入的正样本是vec文件,所以需要使用OpenCV自带的CreateSamples程序(在你所按照的opencv\bin下,如果没有需要编译opencv\apps\HaarTraining\make下的.dsw文件,注意要编译release版的)将准备好的正样本转换为vec文件。转换的步骤如下:
1) 制作一个正样本描述文件,用于描述正样本文件名(包括绝对路径或相对路径),正样本数目以及各正样本在图片中的位置和大小。典型的正样本描述文件如下:
posdata/1(10).bmp 1 1 1 23 23
posdata/1(11) 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









