







一直在用kettle做数据处理的工作,最近有个项目组需求,用kettle好像没法直接达到目的,遂自己写代码来实现。需求如下:从这个网站http://ztb.whx.gov.cn/SortHtml/1/8447599122.html 获取相应的列表名称、子目录的地址以及子目录内各个网页内容。如图:
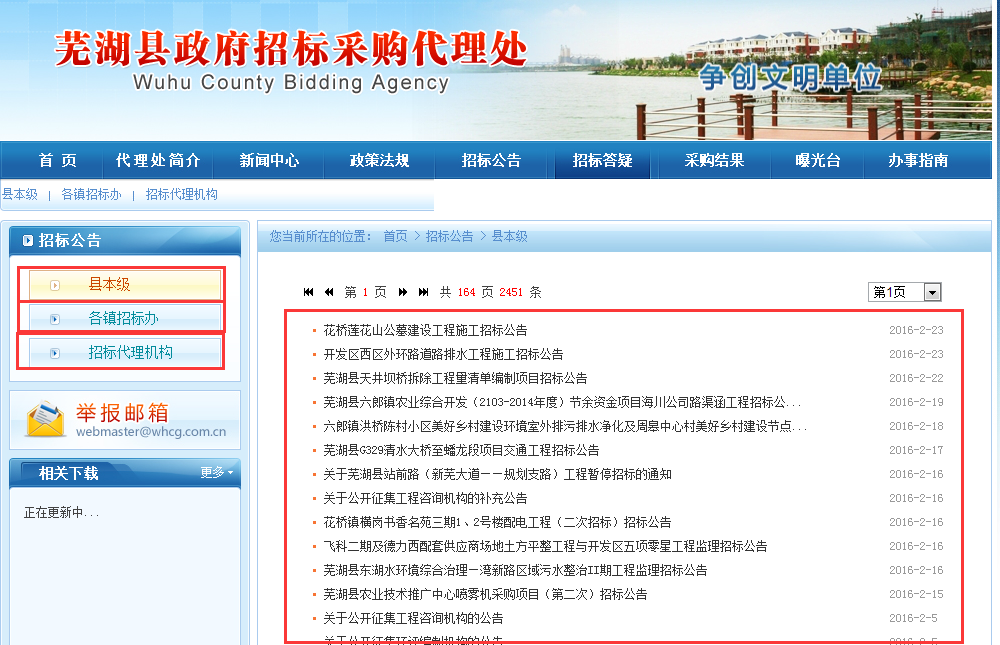
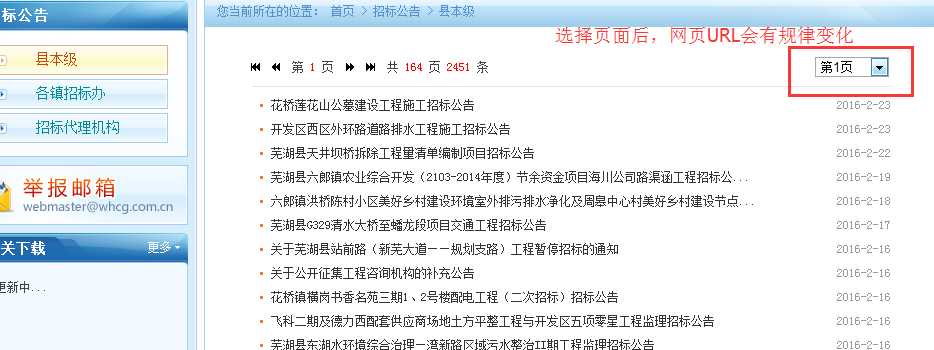
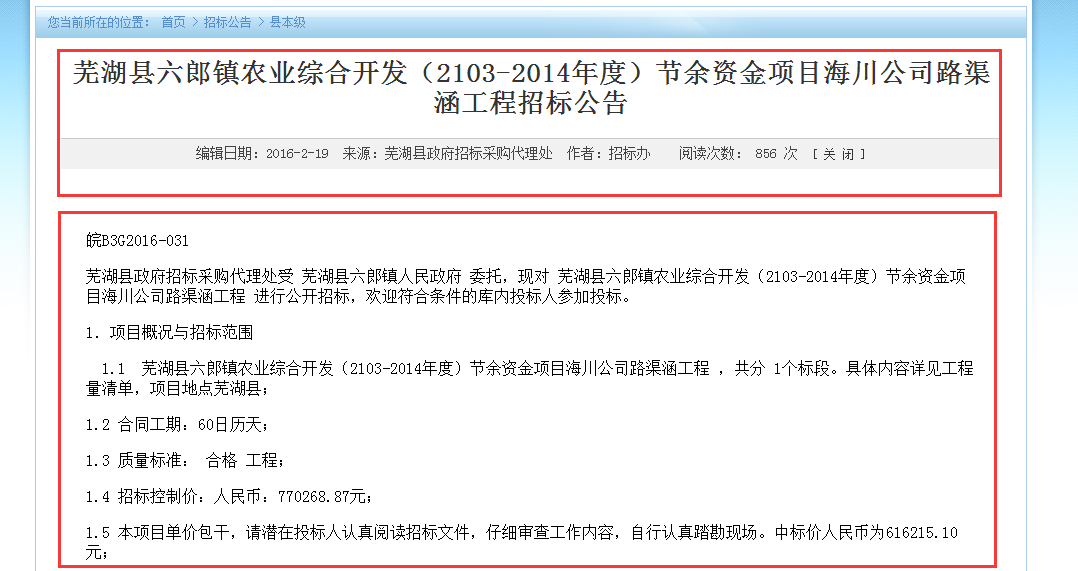

需求确定了,开发如下:
1.利用Jsoup的jar包内方法可以获取并解析html内容
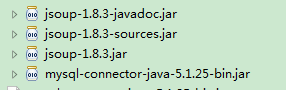
2.获取首页列表,代码如下:
package com.jsoup.demo;
import java.io.IOException;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.Statement;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import com.jsoup.test.SQLHelp;
/*
* 获取首页列表
* http://ztb.whx.gov.cn/Nav_gonggao.asp?whichpage=1&SS_ID=22 共164页2449条
* http://ztb.whx.gov.cn/Nav_gonggao.asp?whichpage=1&SS_ID=23 共3页35条
* http://ztb.whx.gov.cn/Nav_gonggao.asp?whichpage=1&SS_ID=24 共4页49条
*/
public class GetList {
private static Connection conn = null;
private static Statement st = null;
private static PreparedStatement ps = null;
private static ResultSet rs = null;
/**
* 获取首页标题和标题链接插入数据库中
*/
public static void getListinfo() {
Document doc;
int a = 10;
for (int i = 22; i <= 24; i++) {
if (i == 22) {
a = 200; // 县本级页数为164页
} else if (i == 23) {
a = 20; // 各镇招标办为3页
} else if (i == 24) {
a = 20; // 招标代理机构为4页
}
for (int j = 1; j <= a; j++) {
try {
doc = Jsoup.connect(
"http://ztb.whx.gov.cn/Nav_gonggao.asp?whichpage="
+ j + "&SS_ID=" + i).get();
Elements ListDiv = doc.getElementsByAttributeValue("style",
"margin-top:20px;");
for (Element element : ListDiv) {
Elements links = element.getElementsByTag("a");
for (Element link : links) {
String linkHref = link.attr("href");
String linkText = link.text().trim();
String content = null;
SQLHelp sh = new SQLHelp();
conn = sh.getConnection();
try {
// 判断数据库中是否已经存在该条记录,若存在不操作
if (chargeExists(linkHref).equals("no")) {
String sql = "insert into links1(linkname,linkhref,content) values(?,?,"
+ content + ")";
ps = conn.prepareStatement(sql);
ps.setString(1, linkText);
ps.setString(2, linkHref);
ps.executeUpdate();
}
} catch (Exception e) {
System.out.println(e.getMessage());
} finally {
try {
if (ps != null)
ps.close();
if (conn != null)
conn.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
// 判断是否已经存在
public static String chargeExists(String href) {
SQLHelp sh = new SQLHelp();
conn = sh.getConnection();
try {
String sql1 = "select linkhref from links1 where linkhref='" + href
+ "'";
st = conn.createStatement();
rs = st.executeQuery(sql1);
if (rs.next()) {
return "yes";
}
} catch (Exception e) {
System.out.println(e.getMessage());
} finally {
try {
if (ps != null)
ps.close();
if (conn != null)
conn.close();
} catch (Exception e) {
e.printStackTrace();
}
}
return "no";
}
// 删除非标准的域名
public static void delWrongUrl() {
SQLHelp sh = new SQLHelp();
conn = sh.getConnection();
try {
String sql = "DELETE from links1 where linkhref like '/Nav_gonggao.asp?whichpage=%'";
ps = conn.prepareStatement(sql);
ps.executeUpdate();
} catch (Exception e) {
System.out.println(e.getMessage());
} finally {
try {
if (ps != null)
ps.close();
if (conn != null)
conn.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) {
// 插入链接和标题数据
getListinfo();
// 删除非标准域名地址
delWrongUrl();
}
}
3.根据获取到的url地址,更新相关数据,代码如下:
package com.jsoup.demo;
import java.io.IOException;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.Statement;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
import com.jsoup.test.SQLHelp;
public class UpdateInfo {
private static Connection conn = null;
private static Statement st = null;
private static PreparedStatement ps = null;
private static ResultSet rs = null;
/**
* 从数据库读取URL获取相应内容并更新
*/
public static void updateInfo() {
SQLHelp sh = new SQLHelp();
conn = sh.getConnection();
try {
String sql = "select linkhref,linkname from links1 where content=''";
st = conn.createStatement();
rs = st.executeQuery(sql);
while (rs.next()) {
String str = rs.getString(1);
String str1 = rs.getString(2);
String body=getBody(str);
String sql1 = "update links1 set sourcetxt= ? ,content= ?,title=?,editdate=?,source=?,editor=? where linkhref= ? ";
ps = conn.prepareStatement(sql1);
ps.setString(1, body);
ps.setString(2, getUrlInfo(str));
//ps.setString(3, (body.substring(body.indexOf(str1.replace(".", "")), body.indexOf(str1.replace(".", ""))+20)).replaceAll("[&;a-zA-Z0-9</]", ""));
ps.setString(3, str1);
ps.setString(4, (body.substring(body.indexOf("编辑日期:")+5, body.indexOf("编辑日期:")+15)).replaceAll("[&;a-zA-Z]", ""));
ps.setString(5, (body.substring(body.indexOf("来源:")+3, body.indexOf("来源:")+20)).replaceAll("[&;a-zA-Z]", ""));
ps.setString(6, (body.substring(body.indexOf("作者:")+3, body.indexOf("作者:")+20)).replaceAll("[&;a-zA-Z]", ""));
ps.setString(7, str);
//System.out.println(sql1);
ps.executeUpdate();
}
} catch (Exception e) {
System.out.println(e.getMessage());
} finally {
try {
if (ps != null)
ps.close();
if (conn != null)
conn.close();
} catch (Exception e) {
e.printStackTrace();
}
}
}
/**
* 获取指定class内容
*/
public static String getUrlInfo(String url) {
Document doc;
try {
doc = Jsoup.connect(url).get();
Elements ListDiv = doc.getElementsByAttributeValue("class", "p1");
for (Element element : ListDiv) {
// System.out.println(element.html());
String html = element.html().replaceAll("'", "''");
/* return element.html(); */
return html;
}
} catch (Exception e) {
System.out.println(e.getMessage());
}
return null;
}
/**
* 获取指定url的body内容
*
* @throws IOException
*/
private static String getBody(String url) throws IOException {
// 从 URL 直接加载 HTML 文档
Document doc2 = Jsoup.connect(url).get();
String body = doc2.body().toString();
body = body.replaceAll("'", "''");
// System.out.println(body);
return body;
}
public static void main(String[] args) {
updateInfo();
}
}















 488
488

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









