







查找也称检索,是根据给定的某个值,在查找表中确定一个其关键字等于给定值的记录或数据元素。若表中存在一个这样的记录,则称查找成功,反之查找失败。
查找算法大致可以分为:
1) 顺序查找,二分查找,分块查找
2) 树型查找
3) Hash表查找
以如下数组为例:

1. 顺序查找,二分查找,分块查找
1.1 顺序查找(也叫线性查找),在一个已知无(或有序)序队列中找出与给定关键字相同的数的具体位置。原理是让关键字与队列中的数从第一个开始逐个比较,直到找出与给定关键字相同的数为止。
//顺序查找
void saar(int *arr, int sz, int key) //sz: 数组大小,key: 关键字
{
int ind = 0; //下标索引
bool ex = false; //是否存在匹配
while (ind != sz)
{
if (key == arr[ind])
{
cout<<"数组中第 "<<ind+1<<" 个数据元素与关键字 \""<<key<<"\" 相匹配"<<endl;
ex = true;
++ind;
continue;
}
++ind;
}
if (false == ex)
{
cout<<"数组中不存在数据元素与关键字 \""<<key<<"\" 相匹配"<<endl;
}
}**该查找算法时间复杂度为O(n)
1.2 二分查找,要求线形表中的结点按关键字值升序或降序排列,用给定值k先与中间结点的关键字比较,中间结点把线形表分成两个子表,若相等则查找成功;若不相等,再根据k与该中间结点关键字的比较结果确定下一步查找哪个子表,这样递归进行,直到查找到或查找结束发现表中没有这样的结点。
**该查找算法时间复杂度为O(log2n),另:具体代码略(已在之前的博客给出)
1.3 分块查找,也称为索引查找,它是顺序查找的一种改进,是一种性能介于顺序查找和二分查找之间的查找方法。把线形分成若干块,在每一块中的数据元素的存储顺序是任意的,但要求块与块之间须按关键字值的大小有序排列,还要建立一个按关键字值递增顺序排列的索引表,索引表中的一项对应线形表中的一块,索引项包括两个内容:1) 键域存放相应块的最大关键字;2) 链域存放指向本块第一个结点的指针。分块查找分两步进行,先确定待查找的结点属于哪一块,然后在块内查找结点。
这次着重讲下分块查找的算法思想:
1) 将n个数据元素"按块有序"划分为m块(m ≤ n)。每一块中的结点不必有序,但块与块之间必须"按块有序",即前一块中任一元素的关键字都必须小于(或大于)后一块中任一元素的关键字。
2) 根据所有块建立一张索引表,索引表中每一项由关键字字段(存放块中最大的元素的关键字)和指针字段(存放指向相应块的起始下标)组成。
3) 查找分两个部分,先对索引表进行二分查找或顺序查找,以确定待查元素可能在哪一个块中,然后在已确定的块中顺序查找。
那么问题来了!如何分块?这里介绍一种分块方法:
首先确定待查找数据的上限和下限,然后对该区间等分N块,那么这N块就可以作为分块查找的块,然后将原数组中的元素按区间插入进去。当然,这样划分不能保证每个块中的元素个数相等,但是,分块查找算法并不严格要求每块中的元素的个数相等。
假设我们已经获得已经分好块的数组以及其索引表:
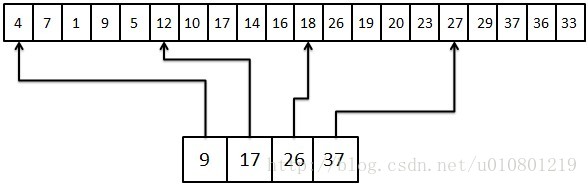
//索引表节点
struct iNode
{
int idata; //块中最大的元素
int ipointer; //块的起始下标
};//分块查找
void block(iNode *index, int m, int *arr, int n, int key) //index: 索引表数组,数组元素为索引节点
{
//对索引表进行二分查找
int low = 0, high = m - 1;
int mid = 0;
while (low <= high)
{
mid = (low + high) / 2;
if (key <= index[mid].idata)
{
high = mid -1;
}
else
{
low = mid + 1;
}
}
int aind = index[mid].ipointer; //获得已确定块的起始下标
bool ex =false; //是否存在匹配
while (arr[aind] <= index[mid].idata && aind != n)
{
if (key == arr[aind])
{
cout<<"数组中第 "<<aind+1<<" 个数据元素与关键字 \""<<key<<"\" 相匹配"<<endl;
ex = true;
++aind;
continue;
}
++aind;
}
if (false == ex)
{
cout<<"数组中不存在数据元素与关键字 \""<<key<<"\" 相匹配"<<endl;
}
}2. 树型查找
这里主要介绍二叉查找树,二叉查找树又称二叉排序树。它或者是一棵空树;或者是具有下列性质的二叉树:
1) 若左子树不空,则左子树上所有结点的值均小于它的根结点的值;
2) 若右子树不空,则右子树上所有结点的值均大于它的根结点的值;
3) 左、右子树也分别为二叉查找树;
查找步骤:若子树为空,查找不成功。若根结点的关键字值等于查找的关键字,查找成功。若小于根结点的关键字值,递归查左子树。若大于根结点的关键字值,递归查右子树。
//树结点
typedef struct tNode
{
int tdata;
tNode *lchild; //指向左孩子结点
tNode *rchild; //指向右孩子结点
}*PTRNODE;//插入算法即二叉查找树的生成
void tinsert(PTRNODE &tp, int key)
{
if (NULL == tp)
{
tp = new tNode;
tp->tdata = key;
tp->lchild = tp->rchild =NULL;
}
else if (key < tp->tdata)
{
tinsert(tp->lchild, key);
}
else
{
tinsert(tp->rchild, key);
}
}
//查找算法
void tsearch(PTRNODE &tp, int key)
{
if (NULL == tp)
{
cout<<"Error\n未找到与关键字 \""<<key<<"\" 相匹配的数据元素"<<endl;
return;
}
if (key < tp->tdata)
{
//打印访问路径
cout<<tp->tdata<<"->";
tsearch(tp->lchild, key);
}
else if(key > tp->tdata)
{
cout<<tp->tdata<<"->";
tsearch(tp->rchild, key);
}
else
{
cout<<tp->tdata<<endl;
}
}3. Hash表查找
1) Hash表(散列表)的定义:若结构中存在和待查关键字(key)相等的记录,则必定存储在H(key)的位置上,不需比较便可直接取得所查记录。称这个对应关系H为散列函数(Hash function),按这个思想建立的表为散列表。
2) 对不同的关键字可能得到同一散列地址,即key1≠key2,而H(key1)=H(key2),这种现象称为冲突。具有相同函数值的关键字称作该哈希函数的同义词。
3) 根据散列函数H(key)和处理冲突的方法将一组关键字映象到一个有限的连续的地址集(区间)上,并以关键字在地址集中的“象”作为记录在表中的存储位置,这种表便称为散列表。这一映象过程称为散列造表或散列,所得的存储位置称散列地址。
常用的Hash函数构造方法
1) 直接寻址法:取关键字或关键字的某个线性函数值为散列地址。即H(key)=key或H(key)=a*key+b,其中a和b为常数。
2) 除留余数法:取关键字被某个不大于散列表表长m的数p除后所得的余数为散列地址,即H(key)=key mod p(p<=m)。
**对p的选择很重要,一般取素数或m,若p选的不好,容易产生同义词。
3) 平方取中法:取关键字平方后的中间若干位作为散列地址。
4) 折叠法:将关键字自左向右分成位数相等的几部分,最后一部分的位数可以不同,然后取这几部分的叠加和(舍弃最后进位)作为散列地址。
**叠加分为两种:
1) 位移叠加:将分割后的每一部分的最低位对齐,然后相加。
2) 边界叠加:从一端向另一端沿分割界来回折叠,然后对齐相加。
5) 数字分析法:找出数字的规律,尽可能利用这些数据来构造冲突几率较低的散列地址。
6) 随机数法:选择一个随机函数,取关键字的随机函数值为它的哈希地址,即H(key)=random(key) ,其中random为随机函数。通常关键字长度不等时采用此法。














 2298
2298











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









