









参考文献见最后。
1.自动驾驶系统的分类
- Rule based system基于规则的系统, 也有论文中将这样的方法叫做Mediated percepiton approach.
- Fully end-to-end 端到端的系统, 也有论文中叫做behavior reflex approach.
- Intermediate approach综合1、 2两种的综合性方法,如 Princeton的DeepDriving ,也叫作direct perception.
- Future video prediction.未来视频预测.
1.1 Rule based system(mediated perception approach)基于规则的系统
从工业界的角度看基于规则的系统,有下图:
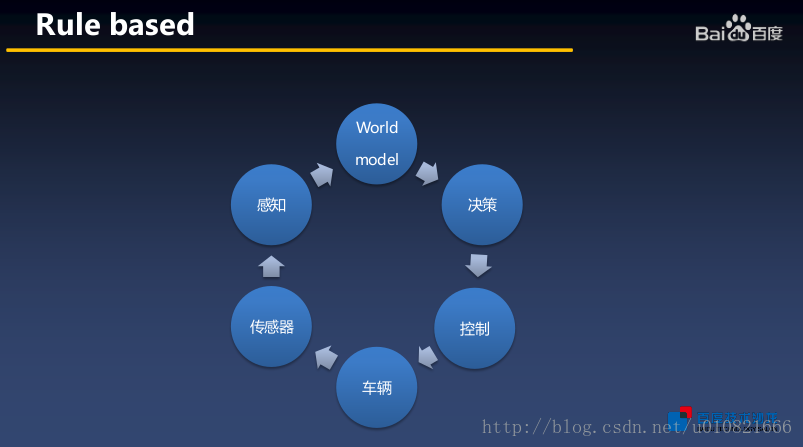
从车辆开始,整个自动驾驶系统是一个闭环系统,车辆传感器数据->感知->建模->决策->控制信号->车辆。
学术界(视觉)比较关心从感知到决策这一阶段吧,基于规则的系统就是理解了整个场景之后,再做决策,涉及到很多相关的子问题,比如说车道线,交通标志的识别,行人检测,信号灯检测,车辆的检测等等,基于规则的方法需要将各种各样的因素全部纳入考虑范围,综合决策,这其实是一件非常困难和复杂的事情。
优势:
有严谨规则,系统可解释性强
存在的问题:
整个系统非常庞大,计算量非常大,对硬件要求高。
规则构建复杂,难以完善地构建整套规则,所以仍存在很多难以用规则描述的情况,使得系统难以有效建模并采取相应措施。
1.2 Fully end-to-end(behavior reflex)端到端的系统
端到端深度学习或者再结合增强学习用于自动驾驶或机器人自主导航,是现在很热的一个研究方向,因为端到端这种image->action,比如开车的话可能是image->steering angles,当然只有steering angles是不够的,更贴近于人的开车习惯。(不过在未来的未来,驾驶这件事儿也许就不需要再考虑人的习惯,因为人开车也有其局限性,现有的车型也是根据人来设计的,不过这是很久之后才需要考虑的事情吧)。
优势:
把整件事情交给神经网络去做,不需要人为地制定规则。
系统的各项成本都比基于规则的系统要低甚至低得多。
存在的问题:
对于不同的车辆和传感器,系统需要进行校准。
可解释性差,毕竟自动驾驶是一个事关安全的问题。
image->action这样的模式,同样的image,可能的action不止一种,跟现实生活中一样,不同的司机面对相同或相似的场景做出的决策是不一样的的,所以这导致端到端的学习像是一个ill-posed不适定问题(适定问题是指解存在,解唯一,解连续依赖于初始条件或者说解具有稳定性)。
另:关于可解释性的一个观点
对于可解释性,,大家目前达成的共识是rule based系统可解释性很高,而end-to-end系统可解释性很低。
但对于传统的基于规则的无人驾驶系统,影响其最关键的点恰恰就在于规则式系统中存在着大量的不确定的边界性问题,这些问题是“不可解释的”,也就是说,从这点看,rule based系统也没有压倒性的优势。
1.3 Intermediate approach 介于rule based和end to end之间的综合性方法
结合两种方法,可以兼顾二者的优势,比如说一定程度上降低计算成本,可解释性介于两者之间等,但是缺点并不能相互抵消,比如说还是需要人为地定义一部分规则,仍存在难以完善地定义一整套规则的问题。
1.4 Future video prediction 未来视频预测
根据现在的情况预测未来可能会发生的情况,人是一定程度上有这个能力的,比如说判断出有些车想插队,有些车故意“别车”……但这又像是一个不适定问题,人也很难判断准确,而且这样的情况很难构造数据集,所以,未来视频预测用于辅助自动驾驶是否有发展前景和发展意义,还有待考虑吧。
2. 端到端自动驾驶的发展
从88年到17年的五项比较有代表性的成果。1,2,5项都有DARPA的支持
2.1 ALVINN 1988 CMU
ALVINN: Autonomous land vehicle in a nerual network
论文:ALVINN:An Autonomous Land Vehicle In a Neural Network[1]
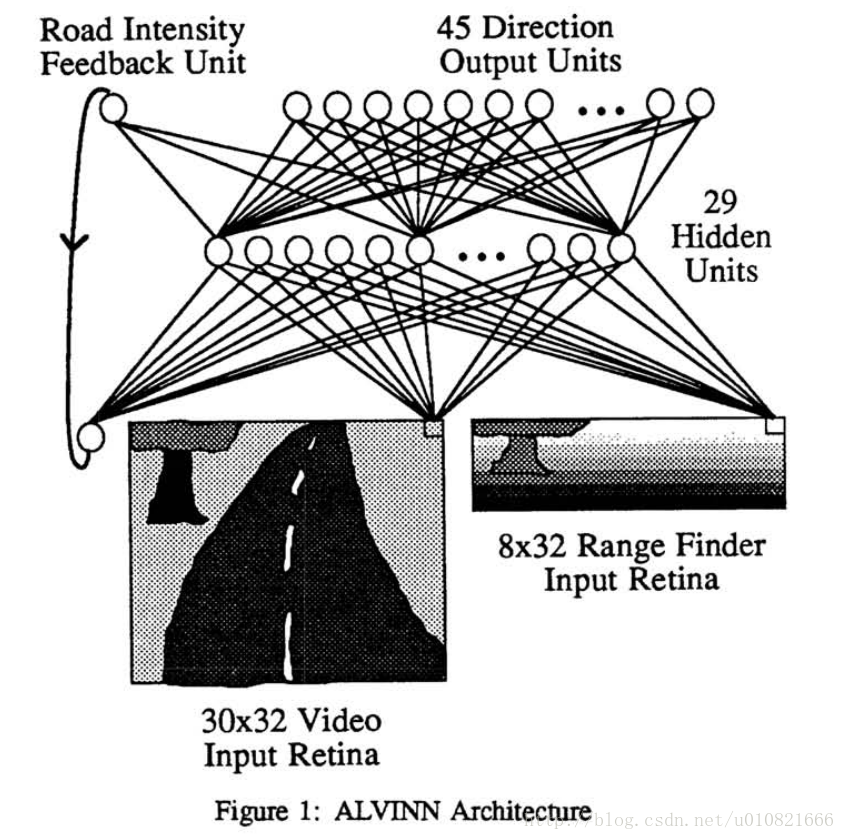
还没有CNN的时代,用了一个三层的比较浅的反向传播神经全连接网络,使用仿真路面图进行训练,输入单目相机和雷达数据,能够输出方向使得车辆一直沿着道路行驶。
网络结构比较简单:
测试的时候用的车辆

车上搭载了3台sun公司的机器,一台Warp(CMU自己研制的可编程序线性心动(Systolic)阵列机:Warp计算机),一台video camera,一台laser range finder激光测距机。
测试结果:速度0.5m/s,CMU校园,树木覆盖的路面,日落环境下,可以准确行驶400米。
作为1988年的结果,ALVINN证明了端到端学习有形成一个自动驾驶系统的能力。
2.2 DAVE 2005 LeCun NYU
LeCun大神05年的论文……学术界已经有了明确的end-to-end学习这一概念。
基于端到端学习的野外避障研究
论文:Off-Road Obstacle Avoidance through End-to-End Learning.[2]
使用6层卷积网络,双目相机RGB图,端到端有监督学习,image->steering angles
网络结构没有图,结构:

测试用机器人:50cm长,速度2m/s,远程计算机控制,中图为训练数据样本,右图为有时接收到的质量不佳画面。

作者在论文结论中指出:系统的主要优势是对野外环境中的各种情况具有鲁棒性,从raw pixels直接得到steering angles,不需要手工标定,校正,参数调整,也不需要设计和选择合适的特征检测子以及鲁棒且快速的双目视觉算法。
总而言之,05年有这样的成果已经是很有开创性的工作了,以至NVIDIA将16年提出的成果命名为DAVE 2。
2.3 DeepDriving 2015 Princeton
论文:DeepDriving: Learning Affordance for Direct Perception in Autonomous Driving[3]
ICCV 2015的文章
deepdriving项目相关网站 http://deepdriving.cs.princeton.edu
有开源代码和数据.
属于自动驾驶系统分类中的第三种:综合性的方法
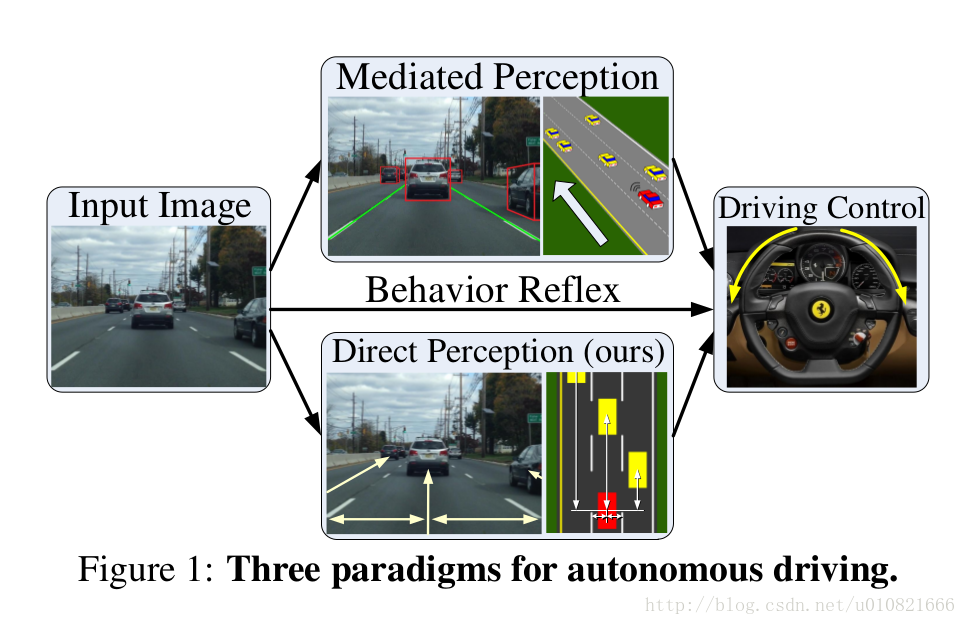
Mediated perception可以理解成基于规则的方法,需要理解整个场景之后再做决策。
Behavior Reflex可以理解成为端到端的方法,输入图像,输出行为。
这篇文章的方法综合了这两种方法,称之为Direct Perception。
文章基于CNN,使用Caffe框架,整体的网络结构还是基于AlexNet。
主要使用TORCS(The Open Racing Car Simulator)的仿真数据(是一个开源的开车游戏,AI研究中也经常使用此数据集)训练和测试,也基于KITTI数据集另外训练了网络以证明方法对于真实的驾驶场景有良好的泛化能力。
系统的整体架构:
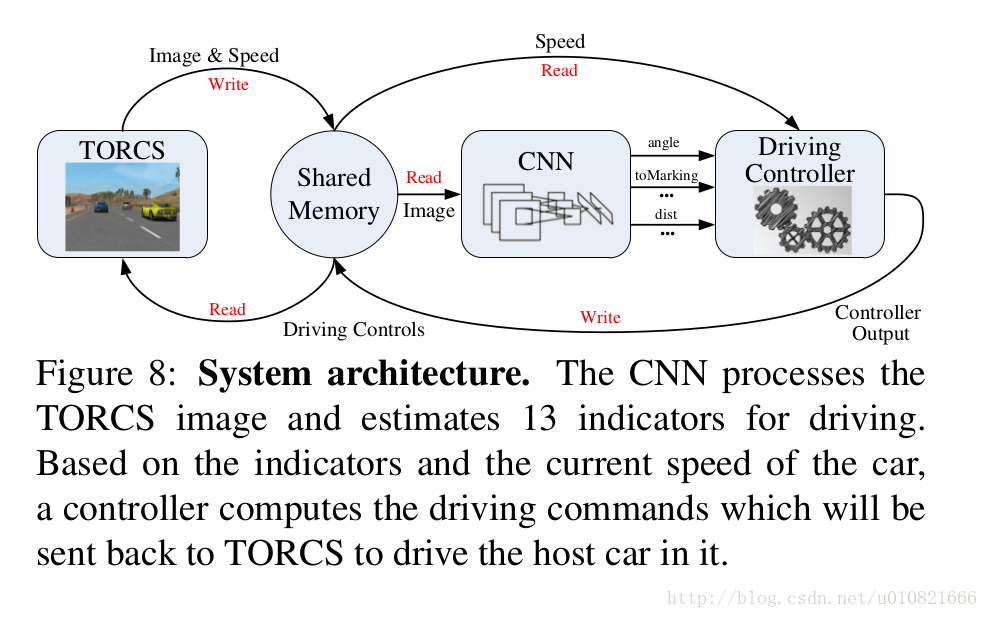
前期用CNN进行训练,CNN的输出与端到端的不同,并不是action而是affordance indicators(实在难以找到合适的中文表达),然后对这些affordance indicators以一些规则进行处理,用公式生成最后操作的行为。
关于affordance indicators:
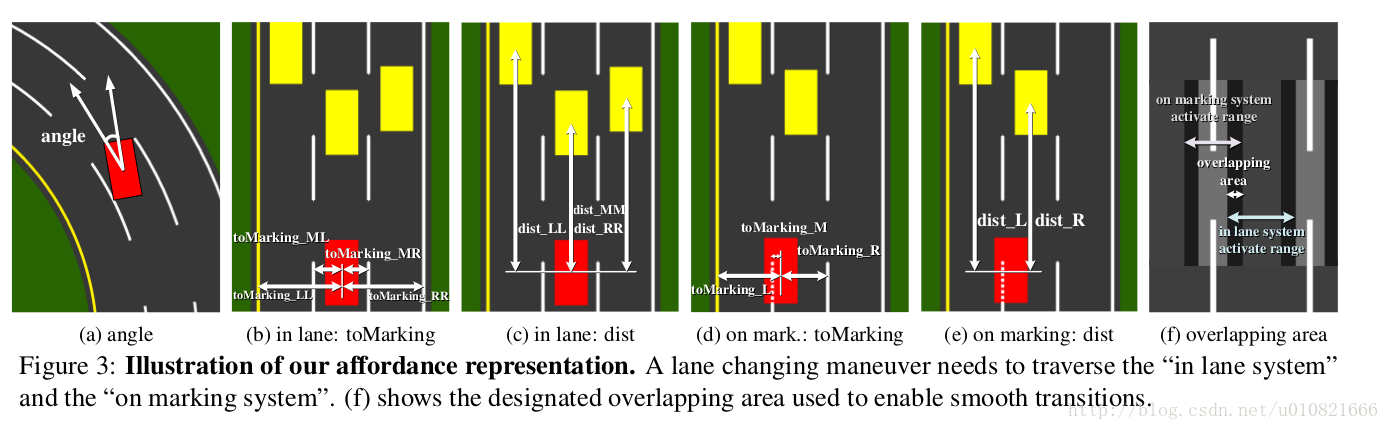
系统主要关心在高速路上的行驶情况,考虑邻近和自身的三个车道。
定义了13种affordance indicators,设车辆在中间车道,考虑左右两边各一车道的情况。

(车辆中心指车辆的长边的垂直平分线或短边的垂直平分线)
1)车头和道路切线之间的角度。
in lane system
2)车辆中心到左车道左边线的距离。
3) 车辆中心到自己车道左边线的距离。
4)车辆中心到自己车道右边线的距离。
5)车辆中心到右车道右边线的距离。
6)车辆中心到左车道前方车辆中心的距离。
7)车辆中心到前方车辆中心的距离。
8)车辆中心到右车道前方车辆中心的距离。
on marking system
9)车辆中心到左边车道线的距离。
10)车辆中心到车道中线的距离。
11)车辆中心到右边车道线的距离。
12)车辆中心到左车道前方车辆中心的距离。
13)车辆中心到右车道前方车辆中心的距离。
整体的逻辑伪代码:
注意CNN的输出

2.4 DAVE 2 2016 NVIDIA
论文:End to End Learning for Self-Driving Cars[4]
Abstact:
We trained a convolutional neural network (CNN) to map raw pixels from a single front-facing camera directly to steering commands. This end-to-end approach proved surprisingly powerful. With minimum training data from humans the system learns to drive in traffic on local roads with or without lane markings and on highways. It also operates in areas with unclear visual guidance such as in parking lots and on unpaved roads.
The system automatically learns internal representations of the necessary processing steps such as detecting useful road features with only the human steering angle as the training signal. We never explicitly trained it to detect, for example, the outline of roads.
Compared to explicit decomposition of the problem, such as lane marking detection, path planning, and control, our end-to-end system optimizes all processing steps simultaneously. We argue that this will eventually lead to better performance and smaller systems. Better performance will result because the internal components self-optimize to maximize overall system performance, instead of optimizing human-selected intermediate criteria, e. g., lane detection. Such criteria understandably are selected for ease of human interpretation which doesn’t automatically guarantee maximum system performance. Smaller networks are possible because the system learns to solve the problem with the minimal number of processing steps.
We used an NVIDIA DevBox and Torch 7 for training and an NVIDIA DRIVETM PX self-driving car computer also running Torch 7 for determining where to drive. The system operates at 30 frames per second (FPS).
训练了卷积神经网络,单个前置摄像头的数据->驾驶命令,可以在有/无车道线的道路上,以及高速公路,停车场,未铺砌的路面等区域行驶。30帧/秒的处理速度。
NVIDIA DRIVE PX 有三个摄像头。
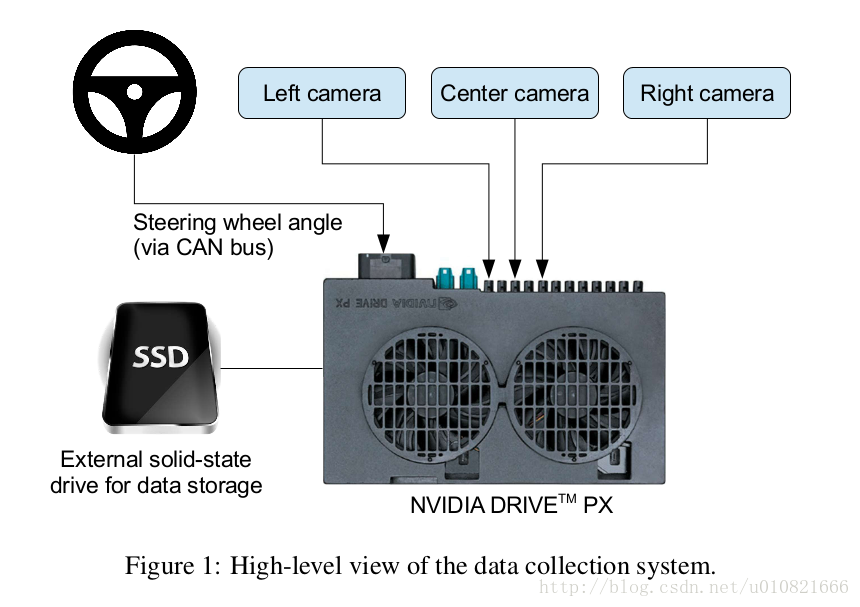
训练过程如下图:
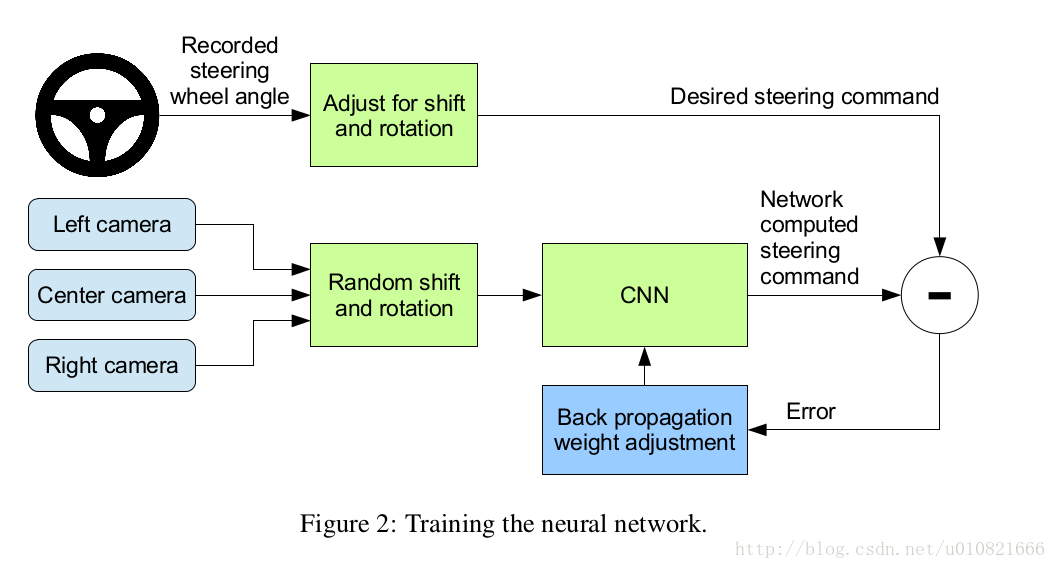
在训练之后,系统只需要center camera的数据就可以工作。
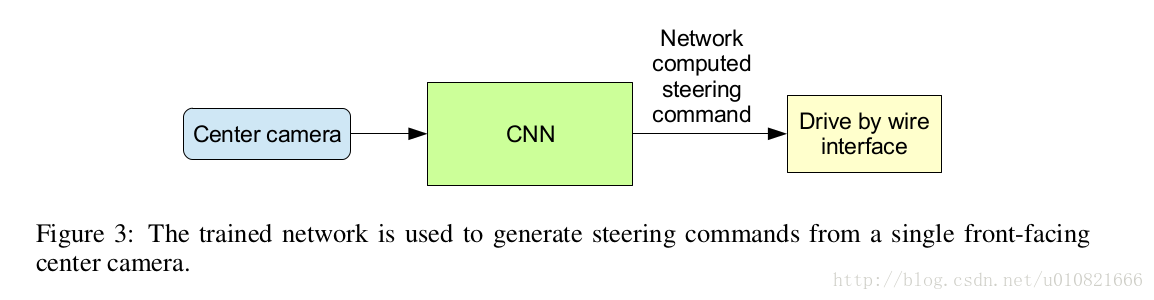
网络的结构,有点儿类似AlexNet?
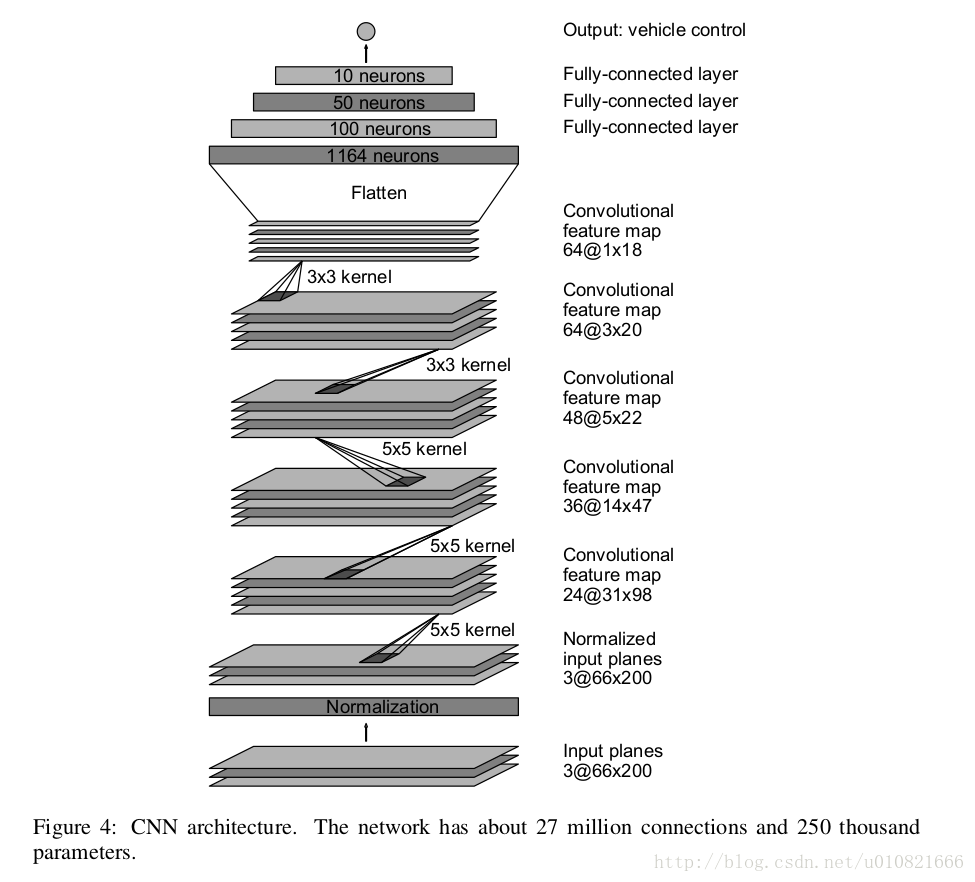
结果:
NVIDIA直接开的真车……
评价指标是自动化持续驾驶的时间占总时间的比例。
认为车辆偏离车道中心线大于1米时需要人工干预,每次人工干预需要6秒(人取回车辆控制权,人工回正,重新回到自动驾驶模式)。
目前的测试结果是,600秒内需要人工干预10次。但也因路况不同而有所不同,也有连续自动驾驶10英里不需要人工干预的情况。
另外,NVIDIA认为,使用他们的方法并不需要特别大量的数据,使用小于100小时但包含各种情况(路况,天气)的数据就足够了。
相关视频链接 DAVE 2 driving a lincoln
2.5 BDDV dataset 2017 Berkeley
论文:End-to-end Learning of Driving Models from Large-scale Video Datasets.[5]
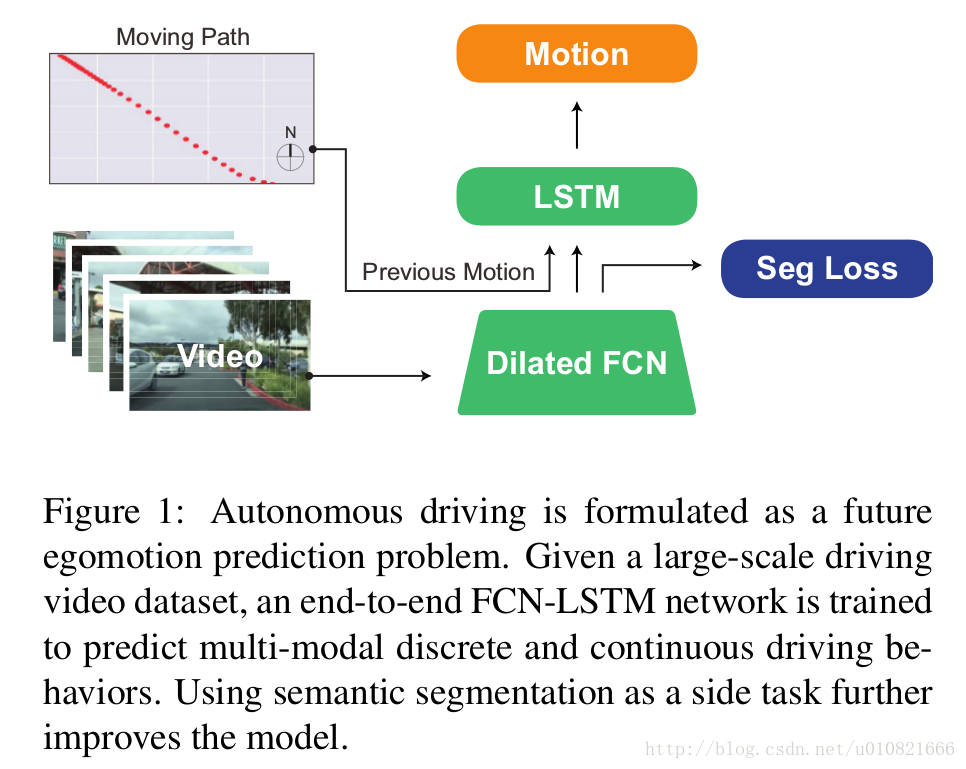
使用FCN-LSTM全卷积-长短期记忆网络的架构,FCN略作改动->使用了空洞卷积/扩张卷积的FCN,将大规模视频数据集输入到网络中去,预测多模态的离散或连续的驾驶行为,离散指停止,前进,左转,右转这样比较明确的行为,连续指得到可以前进方向的概率。
FCN-LSTM架构
- 视觉编码器 基于AlexNet,移除了pool2和pool5,使用dilated FCN 提取视觉信息。
- 时间融合 使用LSTM融合所有过去和现在的状态以得到现在的状态。
数据集
BDDV数据集包含了驾驶视频和GPS/IMU数据,包括城市道路,高速路,郊区道路,白天/夜间多种场景,共计10000小时以上。
实验
使用了BDDV数据集中的一个子集,21808段视频作为训练数据,1470段作为验证,3561作为测试,但是每段视频大概只有40秒?为什么每一段都这么短?
准确率为84.1%(离散)和72.4%(连续),后者复杂度会高一些。
2.6 End-to-end Driving via Conditional Imitation Learning 2017 Intel Lab
论文:End-to-end Driving via Conditional Imitation Learning 2017 Intel Lab[6]
3. 端到端机器人导航
3.1 使用DRL实现机器人自主导航 Stanford 2017
论文:Target-driven Visual Navigation in Indoor Scenes using Deep Reinforcement Learning[7]
使用DRL深度加强学习实现机器人自主导航
摘要:
深度强化学习中有两个较少被提及的问题:1. 对于新的目标泛化能力不足,2. 数据低效,比如说,模型需要几个(通常开销较大)试验和误差集合,使得其应用于真实世界场景时并不实用。 在这篇文章中,我们解决了这两个问题,并将我们的模型应用于目标驱动的视觉导航中。为了解决第一个问题,我们提出了一个actor-critic演员评论家模型,它的策略使目标函数以及当前状态,能够更好地泛化。为了解决第二个问题,我们提出了 AI2-THOR框架,它提供了一个有高质量的3D场景和物理引擎的环境。我们的框架使得agent智能体能够采取行动并和对象之间进行交互。因此,我们可以高效地收集大量训练样本。我们提出的方法 1)比state-of-the-art的深度强化学习方法收敛地更快,2)可以跨目标跨场景泛化,3)通过少许微调就可以泛化到真实机器人场景中(尽管模型是在仿真中训练的)4)不需要特征工程,帧间的特征匹配和对于环境的特征重建,是可以端到端训练的。
视频链接
https://youtu.be/SmBxMDiOrvs
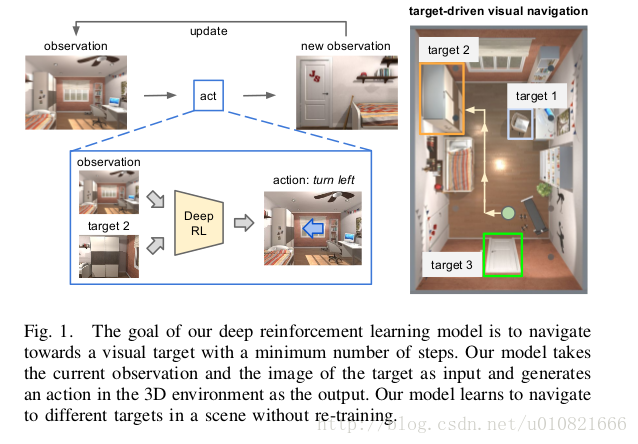
提出了一个框架AI2-THOR来生成仿真数据,室内场景,厨房,起居室,卧室,浴室。将开放此框架的Python API,文中有跟其他仿真数据集的比较。
将整个空间划分成二维的网格,0.5米走一步,机器人可以有四种动作:前进,后退,左转,右转。
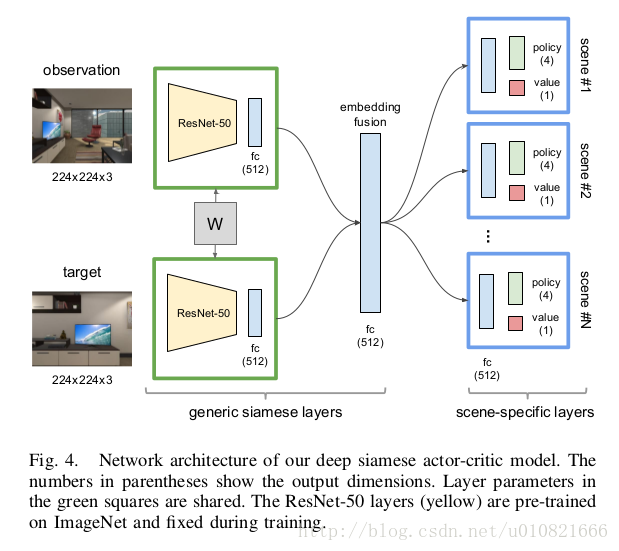
采用了孪生网络,deep siamese actor-critic network,observation和target都作为ResNet-50网络(已经训练好的模型,训练过程中此模型不变)。训练增强学习模型的方法类似于A3C。
a
~
π(St,g|u)
a:action, π:policy, S:state(observation), g:target, u:model parameters
3.2 视觉导航感知建图与规划 Berkeley Google 2017
论文:Cognitive Mapping and Planning for Visual Navigation[8]
用于视觉导航的感知建图和规划
摘要:
我们提出了一个用于在陌生环境中导航的神经网络结构。我们提出的这个结构以第一视角进行建图,并面向环境中的目标进行路径规划。 The Cognitive Mapper
and Planner (CMP)主要依托于两个观点:1.一个用于建图和规划的统一的联合架构中,建图由规划的需求所驱动的。2. 引入空间记忆,使得能够在一个并不完整的观察集合的基础之上进行规划。CMP构建了一个自上而下的belief map置信地图,并且应用了一个可微的神经网络规划器,在每一个时间步骤中决策下一步的行动。对环境积累的置信度使得可以追踪已被观察到的区域。我们的实验表明CMP的性能优于reactive strategies反应性策略 和standard memory-based architectures 标准的基于记忆的体系结构 两种方法,并且在陌生环境中表现良好。另外,CMP也可以完成特定的语义目标,比如说“go to a chair”到椅子那儿去。
使用的是S3DIS仿真数据集,是斯坦福的一栋楼的室内建模数据。
这一篇与上一篇属于会被拿来相互比较的文章,问题的描述和建模都比上一篇感觉要复杂一些。上一篇在RL部分使用的是actor-critic的模型,这一篇使用的是值迭代的方法,当然是改进版,因为值迭代是上帝视角的。
分为mapper和planner两部分,mapper的架构:
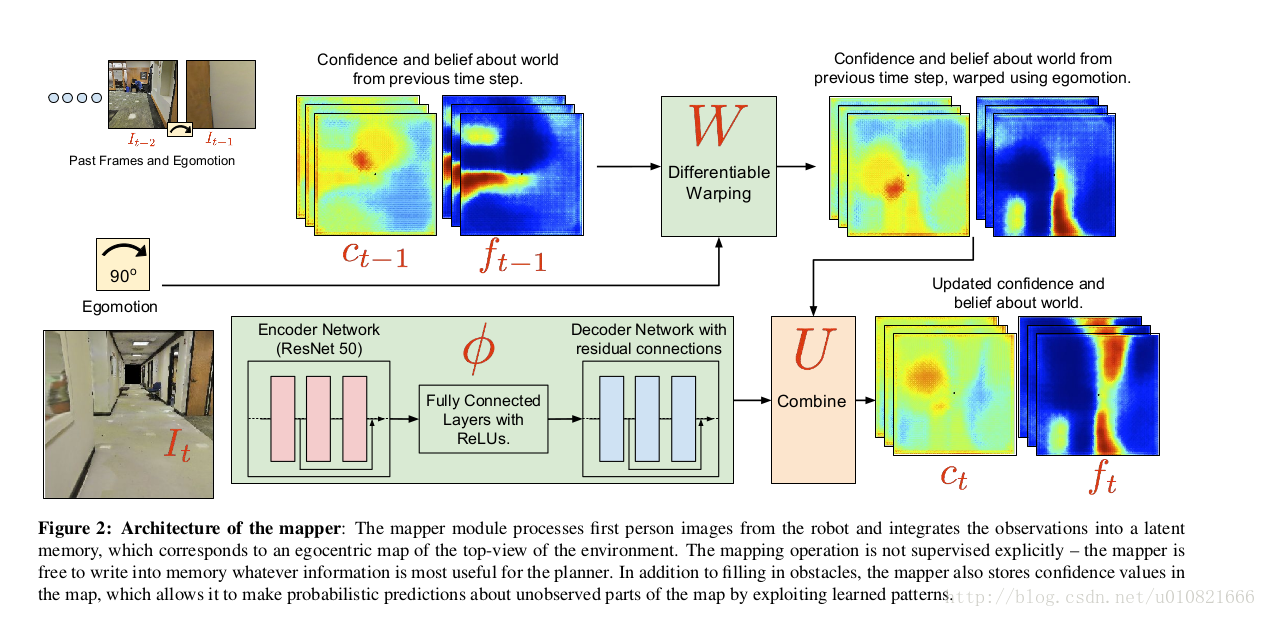
对应于问题的描述:
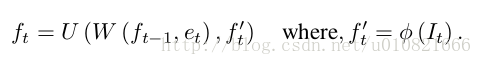
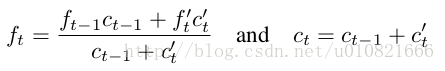
ft: t 时刻,我觉得可以理解为RL问题中的状态,俯视视角下机器人的空间位置,表现为一个多通道的2D特征图,由It估计而来。
It: t时刻,机器人第一视角观察到的图像。
et: 是t-1时刻到t时刻的机器人自运动。
如何得到U,W和
ϕ
?
ϕ
用CNN学习而得,W使用双线性插值而得,U即以上第二个公式。
planner的架构,分级架构(降低复杂度)
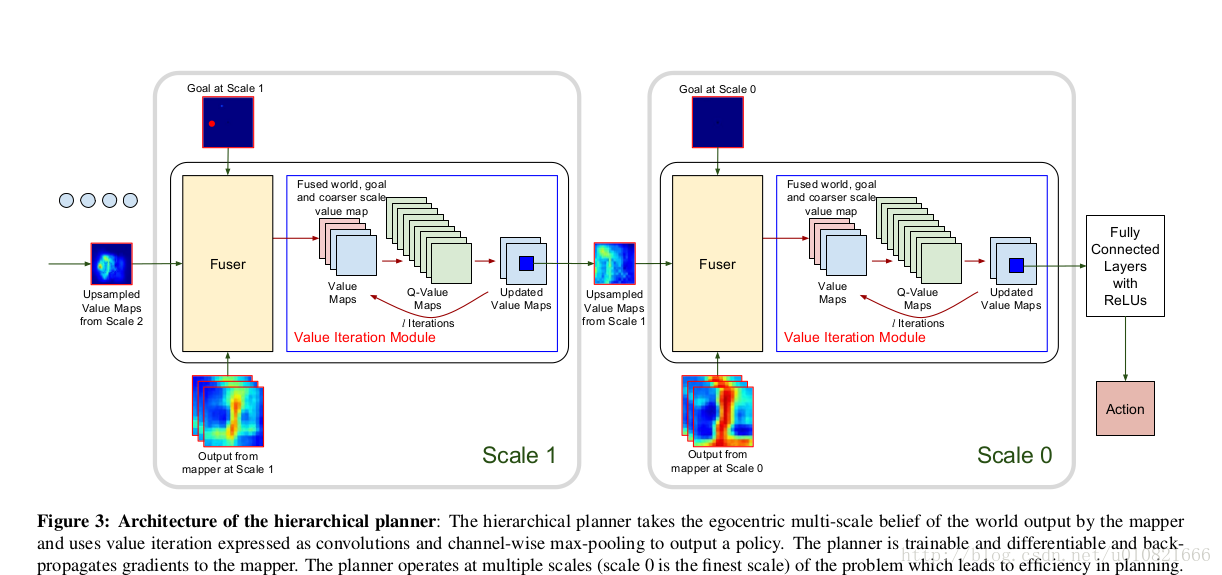
使用mapper的输出作为输入,使用值迭代的方法生成policy,可训练,可微,多级,梯度反向传播给mapper。
参考文献:
[1] Pomerleau D A. ALVINN: an autonomous land vehicle in a neural network[M]// Advances in neural information processing systems 1. Morgan Kaufmann Publishers Inc. 1989:305-313.
[2] Lecun Y, Muller U, Ben J, et al. Off-road obstacle avoidance through end-to-end learning[C]// International Conference on Neural Information Processing Systems. MIT Press, 2005:739-746.
[3] Chen C, Seff A, Kornhauser A, et al. DeepDriving: Learning Affordance for Direct Perception in Autonomous Driving[C]// IEEE International Conference on Computer Vision. IEEE Computer Society, 2015:2722-2730.
[4] Mariusz Bojarski, Davide Del Testa, Daniel Dworakowski, et al. End to End Learning for Self-Driving Cars[J]. 2016.
[5] Xu H, Gao Y, Yu F, et al. End-to-end Learning of Driving Models from Large-scale Video Datasets[J]. 2016.
[6] Codevilla F, Müller M, Dosovitskiy A, et al. End-to-end Driving via Conditional Imitation Learning[J]. 2017.
[7] Zhu Y, Mottaghi R, Kolve E, et al. Target-driven Visual Navigation in Indoor Scenes using Deep Reinforcement Learning[J]. 2016.
[8] Gupta S, Davidson J, Levine S, et al. Cognitive Mapping and Planning for Visual Navigation[J]. 2017.














 282
282











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









