










在机器学习中,通常我们感兴趣的是在给定训练数据D时,确定假设空间H中的最佳假设。
所谓最佳假设,一种办法是把它定义为在给定数据D以及H中不同假设的先验概率的有关知识条件下的最可能(most probable)假设。
贝叶斯理论提供了计算这种可能性的一种直接的方法。更精确地讲,贝叶斯法则提供了一种计算假设概率的方法,它基于假设的先验概率、给定假设下观察到不同数据的概率、以及观察的数据本身。
要精确地定义贝叶斯理论,先引入一些记号。
1、P(h)来代表还没有训练数据前,假设h拥有的初始概率。P(h)常被称为h的先验概率(prior probability ),它反映了我们所拥有的关于h是一正确假设的机会的背景知识。如果没有这一先验知识,那么可以简单地将每一候选假设赋予相同的先验概率。
2、P(D)代表将要观察的训练数据D的先验概率(换言之,在没有确定某一假设成立时,D的概率)。
3、P(D|h)代表假设h成立的情形下观察到数据D的概率。更一般地,我们使用P(x|y)代表给定y时x的概率。
在机器学习中,我们感兴趣的是P(h|D),即给定训练数据D时h成立的概率。
P(h|D)被称为h的后验概率(posteriorprobability),因为它反映了在看到训练数据D后h成立的置信度。
应注意,后验概率P(h|D)反映了训练数据D的影响;相反,先验概率P(h)是独立于D的。
贝叶斯法则是贝叶斯学习方法的基础,因为它提供了从先验概率P(h)以及P(D)和P(D|h)计算后验概率P(h|D)的方法。
贝叶斯公式
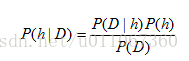
直观可看出,P(h|D)随着P(h)和P(D|h)的增长而增长。同时也可看出P(h|D)随P(D)的增加而减少,这是很合理的,因为如果D独立于h被观察到的可能性越大,那么D对h的支持度越小。
极大后验(maximum a posteriori, MAP)假设:学习器考虑候选假设集合H并在其中寻找给定数据D时可能性最大的假设h∈H(或者存在多个这样的假设时选择其中之一)这样的具有最大可能性的假设被称为极大后验(maximum a posteriori, MAP)假设。确定MAP假设的方法是用贝叶斯公式计算每个候选假设的后验概率。
更精确地说当下式成立时,称hMAP为—MAP假设:
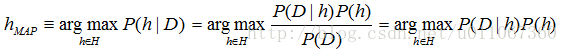
(在最后一步我们去掉了P(D),因为它是不依赖于h的常量)
极大似然(maximum likelihood,ML)假设
在某些情况下,可假定H中每个假设有相同的先验概率(即对H中任意hi和hj,P(hi)=P(hj))。这时可把上式进一步简化,只需考虑P(D|h)来寻找极大可能假设。P(D|h)常称为给定h时数据D的似然度(likelihood),而使P(D|h)最大的假设被称为极大似然(maximum likelihood,ML)假设hML。
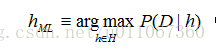
为了使上面的讨论与机器学习问题相联系,我们把数据D称作某目标函数的训练样例,而把H称为候选目标函数空间。
实际上,贝叶斯公式有着更为普遍的意义。它同样可以很好地用于任意互斥命题的集合H,只要这些命题的概率之和为1(例如:“天空是兰色的”和“天空不是兰色的”)。有时将H作为包含目标函数的假设空间,而D作为训练例集合。其他一些时候考虑将H看作一些互斥命题的集合,而D为某种数据。
贝叶斯推理的结果很大地依赖于先验概率,要直接应用方法必须先获取该值。














 2367
2367











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









