







前言
图的遍历与前面文章中的二叉树遍历还是存在很大区别的。所谓图的遍历指的是从图中的某一个顶点出发访问图中的其余顶点,并且需要保证每个顶点只被访问一次。由于图比二叉树复杂得多,所以前面二叉树的遍历算法在图中是行不通的。因为对于任意一个顶点来讲,都可能与其余的顶点发生连接。如果不对访问的顶点做一些处理,出发重复访问的几率是很高的。因此,一个基本思想是设置一个标记数组,主要用于标记已经被访问过的顶点。图的遍历算法主要有两种:深度优先遍历和广度优先遍历。本篇文章主要介绍的是深度优先遍历算法。
深度优先遍历的具体过程
深度优先遍历,简称DFS。具体思想是不放过任何一个死角。在图的遍历中就是从图的某个顶点v出发,访问此顶点,然后从v的未被访问过的邻接点出发深度优先遍历图,直至图中的所有和v有路径相通的顶点都被访问到(对于连通图来讲)。
为了更好说明深度优先遍历的过程,以下面的图为例:
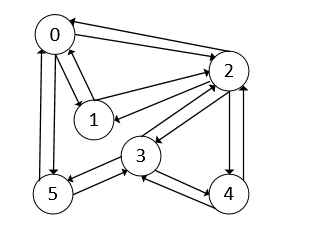
上图的邻接表定义如下:
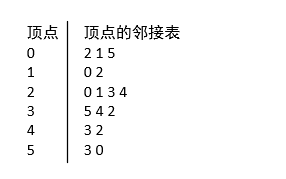
注意:顶点0的第一个元素是2而不是5,其顶点类似。
- 起点是顶点0,后面的遍历过程从顶点0开始,把顶点0标记为已访问
- 因为顶点2是顶点0的邻接表的第一个元素,所以下一次递归从顶点2开始,同时把顶点2标记为已访问
- 顶点2的递归遍历开始,由于顶点2的邻接表的第一个元素是0,但是0已经被访问过了,所以访问顶点1,1没有被访问,于是将1标记为已访问,递归继续从顶点1开始
- 查找上表中顶点1的第一个元素,是顶点0,由于已经被访问过,所以访问顶点2,2也被访问过了,于是从顶点1的递归遍历结束,返回到顶点2继续递归。
- 查找顶点2的下一个元素,顶点3,没有被访问,于是将顶点3标记为已访问,递归于是从顶点3开始
- 查找顶点3邻接表的第一个元素,是顶点5,没有被访问,于是将顶点5标记为已访问,递归从顶点5开始
- 顶点5从其邻接表查找第一个元素,是顶点3,已被访问过,继续查找顶点0,也被访问,于是递归从5结束,返回到顶点3继续递归
- 查找顶点3邻接表的下一个元素,是顶点4,没有被访问过,于是将顶点4标记为已访问,递归从顶点4继续开始
- 顶点4查找其邻接表的第一个元素,发现顶点3已被访问过,继续查找其下一个元素,发现顶点2也被访问过,于是递归从顶点4结束,返回到顶点3继续递归
- 顶点查找下一个元素是顶点2了,也是顶点3邻接表的最后一个元素,发现顶点2已经被访问过了,所以递归从顶点3结束,返回到顶点2继续递归
- 顶点查找其邻接表的下一个元素,是顶点4,也是其邻接表最后一个元素,发现顶点已被访问过,所以递归从顶点2结束,返回到顶点0继续递归
- 顶点0继续查找其邻接表的下一个元素,发现顶点1余顶点5都被访问过了,所以递归结束。总的遍历结束。
从以上过程来看,上图的顶点访问次序依次是:0,2,1,3,5,4。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









