










问题:
判断一个有左括号和右括号、以及其他ASCII字符组成的表达式是合法。 判断条件是左括号-右括号数目、次序配对,可多层嵌套。如果有*,则*可作为0个或者1个右括号,如果匹配则输出ok,不匹配则输出不匹配字符所在字符串中的具体位置
源码下载地址:http://download.csdn.net/download/u011128775/10167555#comment
示例:
((((***********))(((** 不匹配字符位置:18 结果:NOK
((((***********))(((**)) 结果:OK
(()())((()))(()***) 结果:OK
(()*) 结果:OK
*(()*()()*(((* 不匹配字符位置:12 结果:NOK
(((())))*()(*((** 结果:OK
((()(())* 不匹配字符位置:1 结果:NOK
((**)(*()))) 不匹配字符位置:12 结果:NOK
***(((()())** 结果:OK
(*)) 不匹配字符位置:4 结果:NOK
()(())*(*)( 不匹配字符位置:11 结果:NOK
((((******))(((** 不匹配字符位置:13 结果:NOK
分析:
在字符串中,如果有右括号,则优先匹配右括号,再考虑是否要进行通配符匹配。因此,可以先求出通配符*最少需要多少个才能满足字符串中所有的的左括号匹配,计算公式为:
if 左括号数量 <= 右括号数量: //右括号大于等于左括号,不用通配符*替换
max_replace_num=0
else: //右括号比左括号少,如果有*则需要用*进行替换右括号
max_replace_num=左括号数量-右括号数量
因括号匹配问题是优先最近原则,因此,可以将左括号入栈,如果遇到右括号,从栈中弹出一个与之匹配,如果遇到通配符*,如果 max_replace_num==0则直接跳过,否则先入队列,优先让右括号先进行匹配,等到再碰到下一个左括号时先让队列中的通配符*优先匹配完栈中的左括号,再让左括号入栈。
具体流程图:
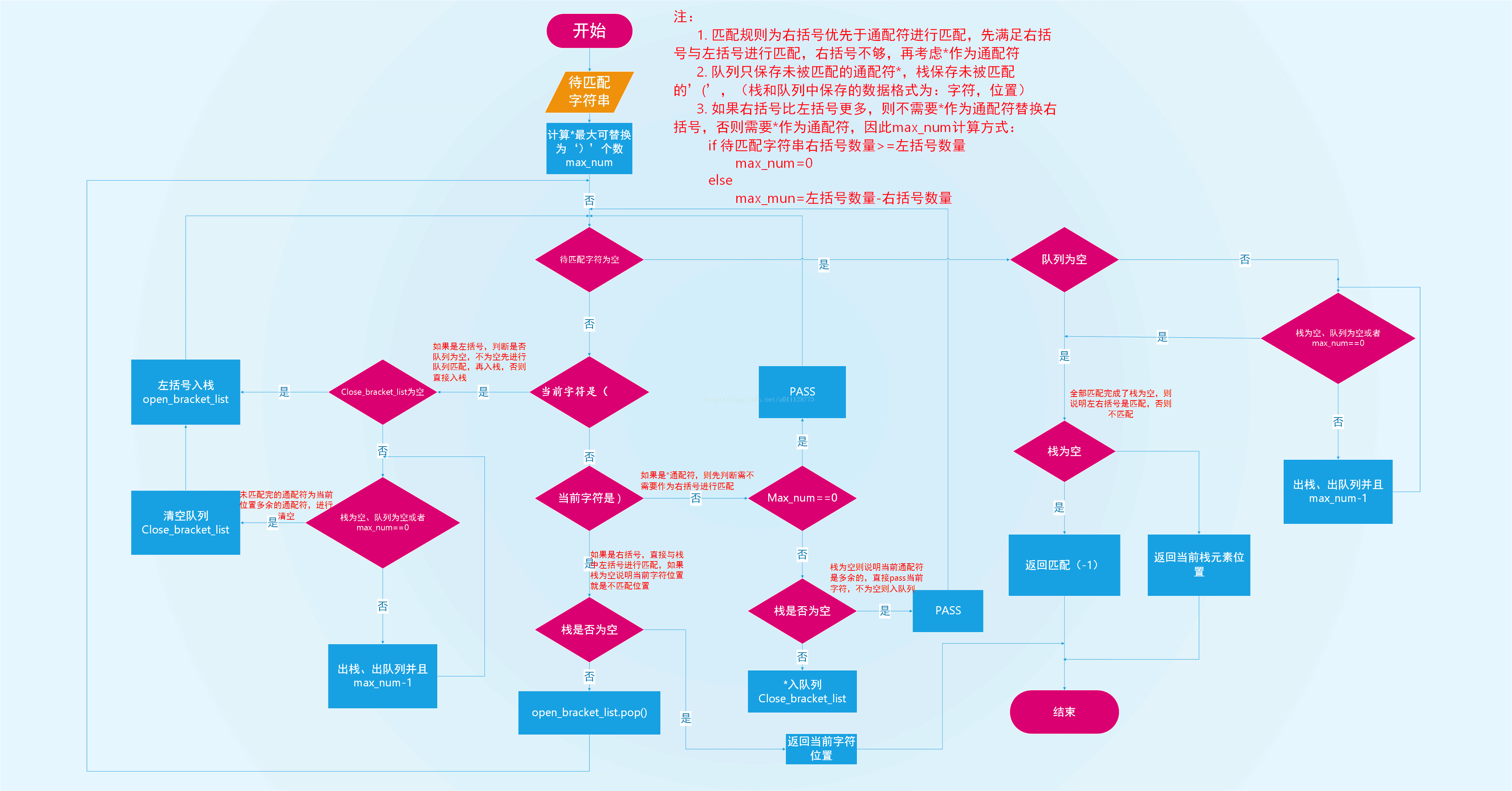
详细代码:
def append_list(i,ch):
ch_list = []
ch_list.append(i)
ch_list.append(ch)
return ch_list
def breaket_match(one_str):
'''
:param one_str: 需要匹配的字符串
:return: 返回-1则说明匹配,否则返回不匹配位置
'''
left_len = one_str.count('(') #左括号个数
left_list = [] # 临时存放左括号字符串列表
right_list=[] #保存*的队列
if left_len <= one_str.count(')'): #右括号大于等于左括号,不用*替换
max_replace_num=0
else: #右括号比左括号少,如果有*则需要用*进行替换右括号
max_replace_num=left_len-one_str.count(')') #替换个数为左括号减去右括号个数
for i in range(len(one_str)):
if one_str[i] == '(': #碰到第一个左括号,把标志位设置为false,说明从这里加上进行正式匹配
flag=False
if len(right_list)==0:
left_list.append(append_list(i=i,ch=one_str[i])) #当前左括号和左括号位置入栈
else: #*替换最大可替换个数
k=len(right_list)
tmp_replace = max_replace_num
for j in range(k):
if len(left_list)==0 or j >tmp_replace-1:
break
else:
left_list.pop()
max_replace_num -= 1
right_list.clear()
left_list.append(append_list(i=i, ch=one_str[i])) # 当前*和*位置入栈
elif one_str[i] == ')':#如果当前字符时右括号,出栈
if len(left_list) != 0: # 如果栈中有元素与之匹配,没有元素,说明不匹配,返回位置
left_list.pop()
else:
return i + 1 # 不匹配,返回位置信息
else: #如果当前字符是*
if max_replace_num==0: #判断*是否需要进行右括号匹配,为0说明不需要进行替换
pass
else: #*需要替换为右括号
if len(left_list)!=0 : #如果栈中有元素与之匹配,没有元素,说明不匹配,返回位置,并且替*换个数-1
right_list.append(append_list(i=i, ch=one_str[i])) # 左括号和左括号位置入栈
else: #如果左括号个数为0,但是下一个与之匹配的为*,则跳过
pass
k = len(right_list)
tmp_replace=max_replace_num
for i in range(k):
if len(left_list) == 0 or i > tmp_replace-1:
break
else:
left_list.pop()
max_replace_num -= 1
if (len(left_list)!=0): #如果左括号栈中元素不为空,不匹配,返回位置信息
return left_list.pop()[0]+1
else:
return -1 #匹配,返回-1
def read_file(file_path):
'''
读取文件
:param file_path:
:return: 返回list集合,里面包含文件每一行的字符
'''
lines = []
try:
file = open(file_path) #打开文件
line = file.readline() #读取文件第一行
while 1:
line = line.strip('\n') #去掉换行符\n
lines.append(line) #把文件的每一行append到lines里面
line = file.readline()
if not line:
file.close()
break
except :
print("打开文件失败,请确认文件名和路径是否正确!")
return lines
def main():
# print("请输入文本文件路径:")
#读取文件
# filepath=input() #读取控制台谁的文件路径
lines=read_file("test.txt")
length_lines=len(lines)
#breaket_match(str)输入参数str为需要匹配的字符串,如果匹配成功,则返回true,如果匹配不成功,则返回false
file=open("result.txt","w")
for i in range(length_lines): #对读取出来的文件每一行进行匹配
result=breaket_match(one_str=lines[i])
if result==-1:
file.write("行号:第"+str(i+1)+"行; "+"源字符串:"+lines[i]+"; "+"结果:"+"OK"+"\n")
print("行号:第"+str(i+1)+"行; "+"源字符串:"+lines[i]+"; "+"结果:"+"OK")
else:
file.write("行号:第" + str(i+1) + "行; " + "源字符串:" + lines[i] + "; " +"不匹配字符位置:"+str(result)+ " 结果:" + "NOK"+"\n")
print("行号:第" + str(i+1) + "行; " + "源字符串:" + lines[i] + "; " +"不匹配字符位置:"+str(result)+ " 结果:" + "NOK")
file.close()
if __name__ == '__main__':
main()源码+visio流程图+测试用例下载地址:http://download.csdn.net/download/u011128775/10167555#comment














 1172
1172











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









