







 本文探讨了如何利用动态规划和Cache优化计算Fibonacci数列,通过递归结合Cache避免重复计算,减少了计算量。文章通过代码示例展示了递归缓存方法,并指出虽然优化空间后单次计算更快,但不保存历史值,而数组缓存则能在O(1)时间内获取任意斐波那契数。
本文探讨了如何利用动态规划和Cache优化计算Fibonacci数列,通过递归结合Cache避免重复计算,减少了计算量。文章通过代码示例展示了递归缓存方法,并指出虽然优化空间后单次计算更快,但不保存历史值,而数组缓存则能在O(1)时间内获取任意斐波那契数。
这个数列在编写程序的过程中,应该被无数次提起,今天再次提起,作为动态规划的一个引入。
动态规划被人总结为:
递推 + Cache
而使用Cache方式的Fib数列计算也是很酷的。代码非常简洁,但是如果没有这种思想,就很难理解为什么这么写了。
另一种情况是,我们知道要用个数组去缓存,但是在具体实现的过程中,就很难翻译成代码,这里姑且当作一种反思吧。
OK,先看代码:
#define MAXN 45
#define UNKNOWN -1
#include<stdio.h>
long f[MAXN+1]; //用于缓存已经计算的数组
long fib_c(int n)
{
if(f[n] == UNKNOWN)
{
f[n] = fib_c(n-1) + fib_c(n-2);
}
return f[n];
}
long fib_c_driver(int n)
{
//初始化缓存数组
f[0] = 0;
f[1] = 1;
for(int i = 2; i <= n; i++)
{
f[i] = UNKNOWN;
}
return(fib_c(n)); //计算
}
int main(void)
{
printf("%d\n",fib_c_driver(3));
}
首先如果计算一个斐波那契数,我们调用fib_c_driver函数。这个函数将会把缓存数组初始化,前两个数是我们已知的0,1,第三个开始到以后都看作未知,初始化为-1,这个数字随便写,但是不要是一个可能的斐波那契数。
然后将调用fib_c函数去递归计算,这个过程稍微解释一下:
进来以后,先判断数组中是否已经缓存,如果没有缓存,就递归计算。
如果求的是fib_c(0), fib_c(1),直接返回已经有的数值。
如果求得是fib_c(2),一看,数组中没有缓存,于是计算f[2] = f[1] + f[0],但是这么写就不对,因为f[1],f[0]也是需要计算得来。因为0,1开始就知道,如果计算的是f[45], 直接返回了f[44] + f[43],那么得到的是-2,根本不是我们想要的数,所以,f[2] 后面写的是fib_c(1) + fib_c(0)。
广义一些即为:f[n] = fib_c(n-1) + fib_c(n-2);
那么这个与平常写的那个递归有何区别呢?
我们看f[4] = fib_c(3) + fib_c(2),转换成去求fib_c(3)和fib_c(2)。
fib_c(3)进来是判断f[3] == UNKNOWN,结果是f[3]已经缓存好了,不用再去计算。同样f[2]也是这样。
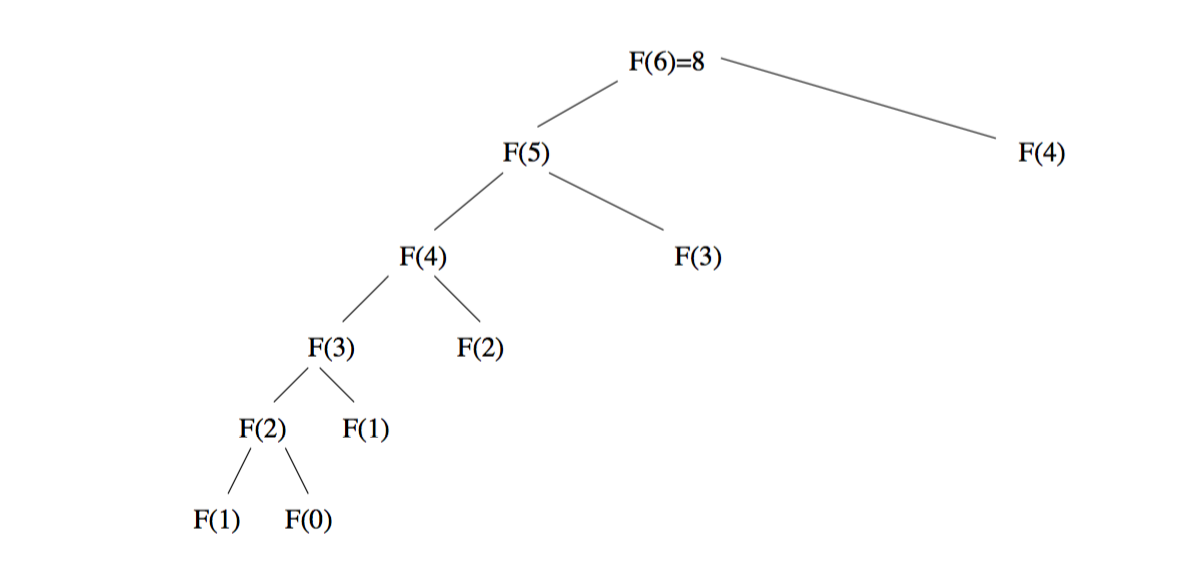
这里用树形图展开,如果未加缓存的计算,将是这棵树的深度优先遍历,每一个树枝都将被走一遍。而如果是缓存,则只需要走最左边的那个路径:F(6 ) –> F(5)–>F(4)–>F(3)–>F(2)–>F(1),F(0),然后整个数组就被写好了。这下减掉多少树枝!
当然,你能感受到,既然是简单的缓存数据,干嘛还要用递归的方式去缓存呢?直接来不就好~
以下:
//非递归调用版本
long fib_dp(int n)
{
f[0] = 0;
f[1] = 1;
for(int i = 2; i <= n; i++)
{
f[i] = f[i-1] + f[i-2];
}
return f[n];
}这个简洁到不用解释了。比上面递归的版本要优秀一些。但是上面的递归大概也可以看作走到这里的缓存吧!
到这里似乎可以结束了,但是我们看到,当我们计算时,需要开辟一个数组,存储了从0,1,1,2,3,5….所有的数据,这…是不是有点奢侈?
对的,虽然时间宝贵,空间也相当宝贵。
我们计算时,当前的状态仅仅与回退到之前的两个状态相关,那么是否可以只用一个变量解决这种问题呢?
答案是可以的。
long fib_ultimate(int n)
{
long back1 = 1, back2 = 0;
long next;
if(n == 0)
{
return 0;
}
for(int i = 2; i < n; i++)
{
next = back1 + back2;
back2 = back1;//先求得back2,再求得back1
back1 = next;
}
return back1 + back2;
}这就有了一些动态规划中,状态转移方程的意思了!
但是值得注意的是,优化了空间后,取得单个斐波那契数值加快了,但是并不存储过去的值。即,计算Fib(45),就是单纯的计算出这个值,这个过程中产生的其他值都被抛弃了。再需要Fib(45),或者Fib(30)等,需要重新计算。如果基于数组的缓存,计算Fib(45)后,从Fib(0)到Fib(45)的值,随用随取,可以做到在O(1)内得到结果。所以,具体问题具体分析。时间优化是必要之举,空间优化适当选择。















 1868
1868

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









