







该博客是我对这篇论文的翻译,水平有限,其中有些名词术语可能有翻译不正确的地方,敬请谅解。
论文原文出处:
http://static.usenix.org/events/nsdi11/tech/full_papers/Hindman_new.pdf
摘要
本文介绍Mesos,一个实现了在多个不同的集群架构上(比如Hadoop、MPI)共享商品计算机集群(share commodity cluster)。这种共享提升了集群的利用率,并且防止了每个架构的数据的重复。Mesos通过一个细粒度的管理器(manager)共享资源,通过在每台机器上轮流读取数据语序不同架构的集群实现数据本地化。为了支持当下集群架构复杂的调度器,Mesos引入了一种分布式的两层的调度机制,被称作“资源提供”(resource offer)。Mesos决定对每个集群架构分配多少资源,而集群架构决定接受哪一种资源,何种计算任务要运行在它们上。我们的结果表明Mesos能够给实现近乎最优化的数据本地化,当在不同集群架构中共享集群时,能够扩展到50000个节点(模拟状态下),并且对故障是有弹性的。
1 导论
Commodity server集群已经成为一个主要的计算平台,在大型因特网服务和数量大量增长的数据密集型科学应用程序中发挥作用。由于这些应用程序的推动,调查者和实践者正在开发一个多样化的集群计算框架的阵列,用于简化对这些集群的编程。突出的例子包括Mapreduce、Dryad、Mapreduce Online(支持流水线作业),Pregel(一个专业的图形计算框架)等等。
很明显,新的集群计算框架仍然会继续出现,并且没有一个框架对于所有的应用程序都是最优化的。因此,许多组织将会希望在同一个计算集群中运行多种集群框架。对于每个应用程序选择最好的一个。在一个计算集群中复用多种集群框架能够提升使用率,并且能够允许应用程序共享访问大型的数据集,而这些数据在多个计算集群中的重复会导致昂贵的代价。
如今,共享一个集群的两个通用的办法是或者静态地划分集群,然后在每个分区中运行一个集群框架,或者给每种框架分配一系列的虚拟机。不幸的是,这些解决方案既不能实现高使用率又不能有效进行数据共享。其中最主要的问题是这些方案的分配粒度和集群框架的分配粒度的失配。许多集群框架,比如Hadoop、Dyad,采用细粒度的资源共享模型,这些模型中节点被划分为槽(slots),作业(jobs)由许多短小的任务(tasks),而这些任务被匹配到slot中。任务的短暂性,以及一个节点上能够运行多个任务的能力允许作业能够实现高的数据本地化,这是由于每个作业能够迅速得到机会运行到节点上,存储它的输入数据。短期的任务使得作业能够迅速扩大规模,这将允许这些集群框架实现高使用率。不幸的是,由于这些集群框架都是独立开发的,我们无法进行跨集群框架地共享粒度,这使得在不同集群框架中有效共享计算集群和数据变得困难。
在这篇论文中,我们展示Mesos,一个薄(thin)的资源共享层,通过对集群框架提供共有的访问集群资源的接口,使得在多样化的集群计算框架中实现细粒度共享成为可能。
Mesos的主要设计问题是如何构建一个可伸缩的、有效的能够支持目前和未来的框架的大规模阵列的系统。这是富有挑战性的问题,原因有以下几点。首先,每个框架由于有不同的编程模型、通信方案,任务依赖和数据存放,拥有不同的调度需求。其次,调度系统必须能够扩展到成百上千个节点,每个节点运行成百上千个作业,这些作业总共有百万个任务。最后,由于所有的在集群中的应用程序都依赖于Mesos,Mesos必须是可容错的和高可用的。
对于Mesos来说,一个方法是实现一个中央调度器,我们需要向这个调度器中输入框架要求、资源可用性和组织策略,然后对所有的任务计算出一个全局的调度。虽然这个方法能够在跨集群框架中能够优化调度,但是他面临一些挑战。首先是复杂性,调度需要提供一个能够充分表达集群框架需求的API,然后解决一个在线的百万个任务的优化问题。即使这样一个调度器是可行的,这种复杂程度也会对它的可扩展性和恢复能力上造成消极的影响。其次,新的框架和新的调度策略仍然在开发,我们甚至无法非常确切地指定一个足够具体的框架需求。第三,许多存在的框架实现了它们自己的非常复杂的调度,将这个功能移动到全局调度器中要求更加昂贵的重构过程。
Mesos使用了一个不同的方法:将调度的控制委托给这些框架。Mesos通过一个新的抽象(abstraction)实现了这个方法,这个抽象被称作资源提供(resource offer),这个抽象封装了一组资源,一个集群框架能够在一个集群节点上分配这些资源来运行任务。Mesos决定给每个集群框架提供多少资源,基于一个组织策略(比如公平共享fair sharing),而集群框架则决定接受哪些资源,以及哪些任务使用这些资源运行。这种非中心化的调度模型可能不能总是达到全局调度最优的目的,但是我们发现它在生产实践中运行得非常好,它能够允许集群框架实现目标(比如近乎完美的数据本地化)。并且,“资源提供”在实现上,是简单的和高效的,允许mesos更好的扩展,对故障更加鲁棒。
Mesos也对使用者提供了其他的好处。首先,即使许多组织知识使用一种集群框架也能使用Mesos在同一计算集群中运行多个集群框架实例,或者多个版本的集群框架。我们与Yahoo!、Facebook的接触显示,这是一种引人注目的实现隔离生产和实现环境的Hadoop工作负载和退出Hadoop新版本的方式。其次,Mesos使得开发和在新的框架上立刻进行实验变得简单。在多个框架中共享资源的能力,实现了一种通用的抽象,这使得开发者不必为了特定的问题域创建、运行专门的集群框架。集群框架因此能够发展速度更快,对每个问题域都能提供更好的支持。
我们使用10000行C++实现了Mesos。这个系统可以扩展50000(模拟)个节点,并且使用ZooKeeper来实现容错。为了评测Mesos,我们部署了3个集群计算系统来运行Mesos:Hadoop,MPI,以及Torque批处理调度器。为了证实我们对于专门集群计算框架与通用框架比较的假设,我们在Mesos之上创建了一个新的框架,叫做Spark,对于数据集在多次平行操作中重复使用的迭代的作业进行了优化,并且表明Spark能够在迭代的机器学习工作负载中相比Hadoop得到10X的性能提升。
这篇论文是这样安排的。第二部分阐述设计Mesos而服务的数据中心环境。第三部分展示Mesos的架构。第四部分分析我们的分布式调度模型(resource offers),并且描述它能够很好地工作的环境。我们在第五部分展示我们对Mesos的实现,在第6部分中评测它。我们在第七部分中展示我们调查到的相关工作。最后,我们在第八部分总结。
2 目标环境
下面说明一个我们想要支持的工作负载的例子,考虑在Facebook上Hadoop架构的数据仓库。Facebook从它的web服务中加载日志到一个2000节点的Hadoop集群,这个集群被他们用来运行应用程序,比如商业智能、垃圾邮件检测以及广告优化。除了定期执行的生产环境的作业,集群也被用来运行许多实验性质的作业,范围包括多个小时的机器学习的运算到1-2分钟的通过一个SQL的接口进行的点对点的交互式查询提交,被称作Hive(释义是蜂巢)。大多数作业是短暂的(作业运行时间的中值是84s),作业都由细粒度的映射和被分解的任务组成(任务执行时间的中值是23s),如图1所示。
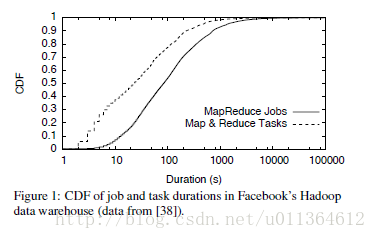
为了满足这些作业的性能需求,Facebook为Hadoop使用一个公平调度器,这个调度器利用工作负载细粒度的特性来分配资源,它工作在任务级别上,这样优化了数据本地化。不幸的是,这意味着集群只能运行hadoop工作。如果一个用户也许由于在作业的交流方案上更加有效,而希望能够写一个针对MPI而不是MapReduce的算法的广告(ad,不知道翻译的对不对),用户必须创建一个单独的MPI集群,并且向其中导入T级别的数据。这个问题是有可能的,我们与Yahoo!、Facebook的接触信息表明运行MPI和MapReduce Online(一种以流的工作模式运行的MapReduce)。Mesos旨在对多个集群计算框架提供细粒度的共享来保证这些使用场景。
体系架构
我们通过讨论我们的设计哲学开始描述Mesos。然后我们描述Mesos的部件,我们的资源分配机制,以及Mesos如何实现隔离、可扩展性和容错。
3.1 设计哲学
Mesos为使得多样化的集群框架能够有效共享计算集群而提供一个可扩展的和有弹力的core(核心)。由于集群框架是高度多样化和发展迅速的,我们最重要的设计哲学是定义一个最小的接口,这个接口使得跨集群框架的资源共享成为可能,另外,需要将任务的调度和执行的控制交给集群框架。将任务的调度和执行的控制交给集群框架有两个好处。首先,它允许集群框架在计算集群中针对多样化的问题实现多样化的方法。(比如,实现数据本地化,处理错误),以及独立地发展这些解决方案。第二,它保持了Mesos的简单,并且最小化了系统的变化率,这使得Mesos保持可扩展和鲁棒变得容易。
即使Mesos提供了一个底层的接口,我们仍然希望更高一层的实现共有功能的库(比如容错)创建在Mesos的顶层。这些库类似于在exokernel中的库操作系统。将这些功能放到库中而不是放到Mesos中保持了Mesos短小和灵活的特性,并且使得这些库能够独立发展。
3.2 综述
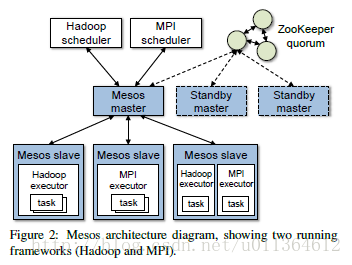
如图2所示,是Mesos的主要部件。Mesos包括一个master进程,它管理着在每个集群节点上运行的slave进程。而集群框架在这些slave节点上运行任务。
master进程使用resource offers实现跨集群框架的细粒度共享。每个resource offer是一个在多台slave节点上的空闲资源的列表。master进程根据一种组织策略决定给每一种集群框架提供多少资源,组织策略如公平共享或者按照优先级。为了支持多样化的一系列集群框架内部的分配策略,Mesos允许组织机构通过一个可安装和卸载的分配模块定义他们自己的策略。
每一种运行在Mesos的集群框架包含两部分:一个注册到master进程中的调度器(scheduler),用于提供资源;以及一个运行在slave节点上的执行(executor)进程,用于运行集群框架的任务。master进程决定给每个进程提供多少资源,集群框架的调度器选择使用哪一种被调度的资源。当一个集群框架接受了被提供的资源,集群框架会给Mesos传递一个它想要运行在这些资源之上的任务的描述。
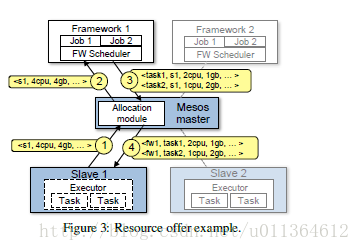
如图3所示,是一个集群框架如何得到调度而执行任务的例子。在第①步中,slave1 向master进程报告它有4个空闲的CPU和4GB的空闲的内存空间。然后master进程调用分配模块,然后这个分配模块会告诉scheduler进程需要为集群框架1分配全部的可用资源。在第②步,master进程向集群框架1发送描述这些资源的resource offer。在第③步,这个集群框架的scheduler向master进程回复两个要运行在slave节点上的任务的信息,对于第一个任务,使用<2CPUs, 1GB RAM>,对于第二个任务,使用<1CPUs, 2GB RAM>。最后,在第④步,master进程向slave节点发送这些任务,slave节点会分配合适的资源给集群框架的executor,executor会依次运行这两个任务。由于1个CPU和1GB RAM仍然是空闲的,分配模块现在可能将它们提供给集群框架2。并且,这个资源提供进程在任务s结束新资源空闲时会重新执行。
为了保持一个简单的(thin)接口,并且使集群框架能够独立发展,Mesos不要求集群框架指定它们的资源要求或者约束。取而代之的是,Mesos赋予了集群框架拒绝被提供的资源的能力。一个集群框架为了等待满足它约束的资源会拒绝不满足它约束的资源。因此,这个拒绝机制使得集群框架能够支持任意复杂的资源约束,同时能够保证Mesos的简单和可扩展。
使用一个单一的拒绝机制来满足所有的集群框架的约束的一个潜在的挑战是效率:一个集群框架在得到一个满足它的资源约束的“resource offer”之前可能需要等待很长的时间,而且Mesos可能不得不向许多的集群框架发送同一个resource offer,在这些集群框架之一接受它之前。为了防止这种情况,Mesos也允许集群框架设置filters(过滤器),这些过滤器是一些指定一个集群框架总是拒绝特定资源的布尔值。例如,一个集群框架可能指定一个它将运行的节点的白名单。
有两点需要提到。首先,filters仅仅是对资源提供模型的性能优化,集群框架有最终的决定权,来拒绝任何它们不能表达过滤的资源,以及选择哪个任务运行在哪一个节点上。第二,在本文中我们将要展现,当工作负载由细粒度的任务构成时(在MapReduce和Dyrad工作负载),资源提供模型在没有使用filters的情况下性能甚至非常好。尤其是,我们发现一个被称作延迟调度的简单策略,使用这种调度策略的集群框架等待有限的时间来获得存储它们的数据的节点,在1-5s的等待时间内得到一个近乎最优化的数据本地化。
在本节的其余部分,我们描述Mesos如何执行两个关键的功能:资源分配(3.3)和资源隔离(3.4)。然后我们描述filters和其他的一些使resource offers可扩展和鲁棒的机制。(3.5)最后,我们Mesos的容错性(3.6),以及总结Mesos的API(3.7)。
3.3资源分配
Mesos将资源分配的决定权委派给一个可插拔的分配模块,因此组织机构可以更改分配模块以适应它们的需求。目前,我们已经实现了两个分配模块:一个基于多种资源的概括比较执行公平共享,另一种实现严格的优先级。相似的策略在Hadoop和Dryad中都被用到。
在正常的操作中,Mesos利用大多数任务都是短暂的事实,仅仅在任务结束时重新分配资源。这在通常情况下会频繁发生,因此新的集群框架能够快速得到他们的资源份额。例如,如果一个集群框架的份额是10%的集群,那么它需要等待任务平均时间长度的10%来获得它的份额。然而,如果一个集群充满了长期任务,比如由于一个爬虫的作业或者一个贪婪的集群框架,分配模块也会撤回(杀死)任务。在杀死一个任务之前,Mesos给这个任务的集群框架一个宽限期来清理。
我们将选择要清理的任务的策略交给分配模块,但是这里我们需要描述两个相关的机制。首先,虽然杀死一个任务对许多集群框架有较低的影响(比如MapReduce),它对一些拥有相互依赖的任务的框架是有害的(比如MPI)。我们通过让分配模块暴露一个“被保证的分配”(guaranteed allocation)给每一个集群框架,来允许这些集群框架阻止自身被杀死,“被保证的分配”指的是一定数量的资源,当集群框架持有的资源是这个数量时,集群框架不会丢失任务。集群框架通过调用一个API获取被保证的分配。分配模块有责任确定他们提供的“被保证的分配”能够同时得到满足。目前,我们对“被保证的分配”保持着简单的语义:如果一个集群框架得到的资源在它被保证的分配之下,那么它的所有任务不应该被杀死,如果它得到的资源在它被保证的分配之上,它所有的任务都可能被杀死。
3.4 隔离
Mesos利用现有的操作系统隔离机制,为运行在同一个slave节点上的集群框架executor之间提供了性能上的隔离。由于这些机制是依赖于平台的,我们通过可插拔的隔离模块支持多个隔离机制。
我们目前使用操作系统的容器技术实现资源的隔离,尤其是Linux Container和Solaris Projects。这些技术能够限制一个进程树对CPU、内存、网络带宽和IO的使用(在新的linux内核中)。这些隔离技术不是完美的,但是相比于那些来自不同的作业的任务s简单的运行在分开的进程中的集群框架,比如Hadoop,使用容器是Mesos的一大优势。
使Resource Offers可扩展和鲁棒
由于在Mesos中的任务调度是一个分布式的进程,它必须有效,并且对错误鲁棒。Mesos提供三种机制帮助实现这个目标。
首先,由于一些集群框架总是拒绝特定的资源,Mesos允许它们缩短拒绝的进程,通过给master进程提供过滤器(filters)来阻止交流。我们目前支持两种类型的过滤器:“只提供在列表L中的节点”和“只提供具有至少R空闲资源的节点”。然而,其他类型的判断也可以支持。注意,不同于通常情况下的约束语言,过滤器是一些布尔值,这些布尔值指定一个集群框架是否会拒绝一个节点上的一组资源,因此这些过滤器能够在master进程中进行快速的评测。任何没有通过一个集群框架过滤的资源都会被当做拒绝的资源处理。
第二,由于一个集群框架可能需要时间来响应一个resource offer, Mesos针对一个集群框架在计算集群中的份额来计算给这个集群框架提供的资源。这将强烈推动集群框架快速响应resource offer,以及过滤它们不使用的资源。
第三,如果一个集群框架已经很久没有对一个resource offer进行响应,Mesos将会撤回这个resource offer,并且重新将资源提供给其他的集群框架。
3.6 容错
由于所有的集群框架依赖于Mesos master进程,使master进程容错是非常重要的。为了实现这一点,我们将master设计为软状态(soft state),因此一个新的master进程能够从slave节点上和集群框架调度器上的信息中完整地重建它的内部状态。特别的,master进程仅有的状态是活动的slave节点的列表、活动的集群框架的列表和正在运行的任务列表。我们在一个双机热备的配置中使用Zookeeper运行多个master进程,用来进行首项选择。当活动的master进程出错,slave节点和调度器会关联下一个被选择的master节点,并且恢复它的状态。
除了处理master的错误,Mesos会将节点的错误和executor错误报告给集群架构的调度器。集群框架之后会使用它们选择的策略应对这些错误。
最后,为了处理调度器错误,Mesos允许一个集群框架注册多个调度器,这样,当一个调度器失败时,另一个被Mesos的master进程通知替代失败的调度器。集群框架必须使用它们自己的机制来在它们的调度器之间共享状态。
3.7 API总结
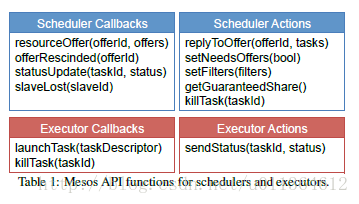
表1总结了Mesos的API。回调函数的1列罗列除了集群框架必须实现的函数,而行为是指它们能够调用的操作。
4 Mesos 表现
在这一节,我们学习在不同工作负载下Mesos的表现。我们的目标不是对这个系统描述一个具体的模型,而是为了描述Mesos分布式调度模型能够正常工作的环境,对Mesos的行为提供一个最粗糙的理解。
长话短说,我们发现当集群框架能够弹性地伸缩,任务的时间是均匀的,并且集群框架倾向于所有节点对等(4.2)时,Mesos运行得非常好。当不同的集群框架倾向于使用不同的节点时,我们会说明Mesos能够模拟出一个中心调度器,这个调度器跨集群框架执行公平共享(4.3)。并且,我们说明Mesos能够处理不同的任务运行时间而不会影响具有短期任务的集群框架的性能(4.4)。我们将会讨论在Mesos之下怎样推动集群框架提升它们的性能,并且认为这种推动措施,会提高集群的整体利用率(4.5)。我们在本节最后描述Mesos分布式调度模型的一些限制。
4.1 定义、度量和假设
在我们的讨论中,我们考虑三个度量:
* 集群框架的等待时间:对于一个新的集群框架得到它的分配的时间。
* 作业的完成时间:一个作业的完成时间,假设每一个集群框架一个作业。
* 系统的使用率:整个集群的使用率。
我们从两个维度上描述工作负载:弹性和任务的时间分布。一个弹性的集群框架,比如Hadoop和Dryad,能够伸缩它的资源,比如它在得到节点的资源时能够迅速使用节点,以及在它的任务结束之后能够迅速释放节点。相反的,一个死板的集群框架,比如MPI,只能在它得到一个固定数量的资源之后才能开始执行它的作业,并且不能进行动态增加以利用新的资源或者在对系统不产生大影响的情况下动态减少占用资源。对于任务执行时间,我们考虑同构的和异构的分布情况。
我们也会区分两种类型的资源:强制性的和建议性的。一个资源是强制性的,如果一个集群框架为了运行必须得到它。例如,一个GPU是强制性的,如果一个集群框架在不能访问GPU时无法运行。相反的,一个资源是建议性的,如果一个集群架构在使用它后表现得更加出色,但是在使用等价的资源的情况下,也可以运行。比如,一个集群框架更希望运行在将它的数据存储在本地的节点,但是也可能必要时远程地读取它的数据。
我们假设被集群框架要求的强制性资源的数量永远不会超过它被保证的资源的份额,这将确保框架不会因为等待强制性的资源的空闲而导致死锁。为了简单,我们假设所有的任务有相同的资源需求,并且运行在相同的机器分片(被称作槽)上,并且每一种集群框架运行一个单独的作业。
4.2 同构的任务
我们假设一个集群中有n个槽和一个被分配了k个槽的集群框架,f。我们考虑任务执行时间的两种分布:常数(比如,所有的任务有相同的时间)和指数。设任务的平均执行时间是T,并且假设集群框架f运行一个总共要求βKT的计算时间的作业。也就是说,当一个集群框架有k个槽,完成一个作业需要βT的时间。
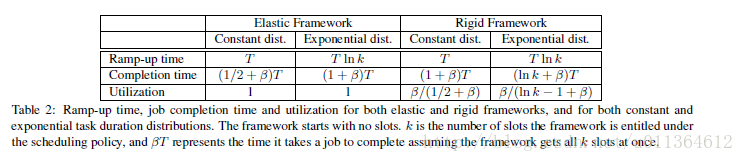
表2总结了对于两种类型的系统框架的作业完成时间和系统利用率,以及两种类型的任务长度分布。不出所料,弹性的并且拥有常量执行时间的任务的集群框架表现得最出色,而死板的并且拥有指数执行时间的任务的集群框架表现得最差。由于空间的限制,我们只将结果和推到展现在这里。
集群框架的等待时间: 如果一个任务的执行时常数的,那么它将在得到k个槽之后花费集群框架f最多T的时间。这是因为在T的时间内,每个槽都是可用的,这样使得Mesos能够给集群框架提供所有的k个它想要的槽。如果执行时间分布是指数型的,那么预测的分配时间将会和TlnK相当。
作业的完成时间:一个弹性的作业的预测的完成时间最多是(1+β)T,这是作业同时得到它的全部槽的完成时间即为T,任务的平均期限。死板的作业对于具有常量执行时间的任务具有相似的完成时间,但是对于指数型的作业会展现出更高的完成时间,即,(lnK + β)T。这是因为会花费平均TlnK长度的时间来得到它全部的槽,并且开始执行作业。
系统利用率: 弹性的作业能充分利用它们被分配到的槽,这是因为弹性作业能够在得到槽之后尽可能快地使用每个槽。结果是,假设有无限的需求,一个只运行弹性作业的系统是能够被充分利用的。死板的集群框架会得到一个略差的使用率,因为它们的作业在它们得到充分的资源之前不能开始,因此它们在这个等待过程中浪费了持有资源的时间。
4.3 位置的偏好
目前,我们已经假设集群框架没有对槽的偏好。在实践中,不同的框架倾向于不同的节点,它们的偏好可能随着时间会改变。在这一节,我们考虑集群框架有不同的偏好的槽的情况。
一个自然的问题是,相比于一个拥有全部集群偏好信息的中心调度器,Mesos如何正常工作。我们考虑两种情况:
(a)存在一种集群设置,在这个设置中,每种集群框架都能得到它偏好的槽,并且得到它全部的份额;(b)没有这样的设置,即,一些被偏好的槽不能被提供。
在第一种情况中,可以很轻易地看出,不管最初配置如何,系统在最多T的时间内都会收敛到一个状态,此时每个集群框架都得到了它偏好的槽。这是因为在T的时间内,所有的槽都是可用的,结果是每个集群框架都能获得它偏好的槽。
在第二种情况中,没有任何设置能够使得集群框架都能得到满足。这个情况的关键问题是应该如何在需要某些偏好的槽集群框架之间分配它们。特别的,假设有p个槽收到m个集群框架的偏好,集群框架i要求ri个这样的槽,\sigma(i=1, m)ri > x。有许多可能的分配策略,这里我们考虑加权公平分配策略,这里与集群框架i相关的权重是它想得到的全部的份额,si。换句话说,假设每一种集群架构有足够的需求,我们旨在提供(TODO)个偏好的槽给集群框架i。
Mesos的挑战是调度器不知道每种集群框架的偏好。幸运的是,被证明有一种简单的方式里实现上文描述的偏好的槽的权重分配:简易执行彩票调度,给每个集群架构提供给他们想要的分配成正比的槽。特别的,当一个槽可用时,Mesos能将这个槽提供给集群架构I的概率是si/(/sigma(i=1,n,si)),n是系统中集群框架的总数。此外由于每种集群框架i在每T个时间单元内都得到平均si个槽, 4.2节等待时间和完成时间的结果仍然是正确的。
4.4 同构的任务
目前,我们已经假设集群框架有同构的任务期限分布,即所有的集群框架有相同的任务期限分布。在这一节,我们讨论有同构ta任务分布的集群框架。特别的,我们考虑一个工作负载,其中任务任务,长任务的平均期限远远长过短任务的执行期限。这种同构的工作负载会损害具有短任务的集任务在最坏的情况中,所有的短任务要求的节任务充斥着长任务,因此这个作业为了得到资源可能需要等待很长的时间(相对于它自己的执行时间)。
我们首先注意到,如果长期作业所占的比例t不是特别接近于1并且每个节点支持多个槽时,任意的任务编排工作得非常好。例如,在每个节点有S个槽的集群中,一个节点被充斥了长期任务的概率是t 的S次方。当S很大时(比如在多核的计算机中),这个数字可能非常小,即使在t大于0.5时。例如,如果S=8并且t=0.5,一个节点充斥了长期任务的概率是0.4%。因此一个有短期任务的集群框架仍然能够在短期内得到大量的偏好的槽。并且,集群框架能够利用的槽越多,就越有可能是,这些槽当中至少有k个执行短期任务。
为了进一步减轻长期任务的影响,Mesos能够进行稍稍地扩展来允许分配策略为每个节点上运行短期任务保留一些资源。特别的,我们可以在每个节点上将一些资源和最大的任务运行期限联系起来,如果运行在这些资源上的任务的运行时间超过这个期限,它们就会被杀死。这些时间限制可以暴露给被提供了resource offer的集群框架,允许它们是否使用这些资源。这种方案与在HPC集群中为短期作业创建分离的队列是相似的。
4.5集群框架的建议性措施
Mesos实现了一个非中心调度模型,其中每一个集群框架都能决定是否接受被提供的资源。和任何一个非中心化的系统一样,在这个系统中理解实体的建议性措施是非常重要的。在这一节,我们讨论集群框架(以及它们的使用者)的建议性措施,从而提升它们的作业的响应时间。
短期任务:有两个原因建议集群框架使用短期任务。首先,这个集群框架将能够分配任何短期槽中保留的资源。其次,使用短期任务能在集群框架丢失任务之后,最小化减少不必要的工作,不管这种丢失是因为任务被撤回或者因为错误。
弹性地扩展:一个集群框架在得到资源后迅速使用资源而不是等待它得到的资源到达一个最小的额度才使用资源的能力将会允许集群框架更早地开始(或完成)它的作业。并且,伸缩能力能力能够允许集群架构随机抓取未使用的资源,因为它能在这之后以很小的消极的影响释放资源。
不要接受未知资源: 建议集群框架不要接受它们不能使用的资源,因为大多数分配策略会在提供资源时计算一个集群框架已经拥有的全部资源。
我们注意到,这些建议与我们提高使用率的目标是一致的。如果集群框架使用短期任务,Mesos能够在集群架构之间快速地重新分配资源。减少新作业的延迟,当出现任务撤回时减少不必要的工作。如果集群框架是弹性的,它们将会随机地使用它们得到的全部资源。最后如果集群框架不接受它们不能理解的资源,这些资源就会被分配给需要的集群框架。
4.6 分布式调度的限制
尽管我们说明,在目前集群环境一定范围的负载下,分布式调度能像其他非中心化的方法一样,能工作得很好。我们对这个分布式模型定义了三个限制:
碎片化:当任务有异构的资源需求时,一个分布式的集群框架集合可能和中心调度器一样不能优化装箱问题。然而注意到由于局部优化装箱而导致浪费的空间被限制在最大的任务的数量和节点的数量的比率之下。因此,计算集群中运行更大的节点(比如,多核的节点)以及在这些节点中运行更小的任务,即使使用分布式调度也会得到更高的使用率。
如果调度模块以一种单纯的方式重新调度资源,可能会得到另一个坏的结果。这种单纯的方式是指当集群充满了有少量资源请求的任务,一个有大量资源请求的集群框架f可能会饥饿。因为无论何时一个小的任务结束,f都不能接受这个小任务释放的资源,但是其他的集群框架可以。为了满足对每个任务都有大量资源请求的集群框架,分配模块能够在每一个slave节点上提供一个最小的resource offer的大小,在slave节点上的空闲资源没有达到这个数量时,slave不会分配资源。
相互依赖的集群框架约束:我们可以创建一种场景,由于集群框架之间很深的依赖关系(比如,来自两个集群框架之间的任务不能共存),其中只有全局的单一的集群分配能够表现得很好。我们证明这样的场景在实践中是罕见的。在这一节讨论的模型中,集群框架仅仅在它们使用的节点上有偏好,我们已经证明分配程序接近那些最优化的调度器。
集群复杂性:使用resource offer可能使得集群调度更加复杂。然而,我们证明这种复杂度不是繁重的。首先,无论使用Mesos还是一个中心调度器,集群框架需要知道它们的偏好;在一个中心调度器中,集群框架需要向调度器传达它的需要,而在Mesos中,Mesos必须使用集群框架来决定哪一种提供的资源被接受。第二,许多存在的调度策略是在线算法,因为集群框架不能预测任务的时间,必须能处理错误和幽灵问题。这些策略使用resource offer能够简单地实现。
5 实现
我们已经使用10000行的C++代码实现了Mesos。这个系统运行在Linux、Solaris和OS X,并且支持使用C++、Java、Python写的集群框架。
为了减少我们实现的复杂性,我们使用C++的libprocess库,这个库使用有效的异步IO机制(epoll,kqueue等等)提供了一个基于角色的编程模型。我们也使用ZooKeeper来进行首项选择。
Mesos能使用Linux Container或者Solaris Projects来分离任务。我们目前能够分离CPU核和内存。我们计划在不远的未来在Linux中增加对网络和IO的隔离。
我们已经实现了我们的四个在Mesos之上的集群框架。首先,我们已经移植了3个已经存在的集群计算系统:Hadoop、Torque资源调度器、 MPICH2实现的MPI,这些移植中没有一个要求改变这些框架的API。因此,它们上面运行的用户程序不需要改变。并且,我们专门创建了一个交互式的作业集群框架,叫做Spark,我们将会在5.3节中讨论。
5.1Hadoop移植
将Hadoop移植到Mesos上运行要求相对较少的改变。因为Hadoop中的细粒度的Map和Reduce的任务与Mesos的任务形成了清晰的映射。并且Hadoop的master进程,被称为TaskTracker,与Mesos模型中的集群框架调度器和executor天然契合。
为了增加在Mesos上运行Hadoop的支持,我们利用了Hadoop已经有了一个可插拔的用于写作业调度器的API。我们写了一个Hadoop的调度器来连接Mesos,并启动TskTrackers作为Mesos的executor,并且将每个Hadoop的任务映射到Mesos的任务。当Hadoop中存在没有运行的任务时,我们的调度器会在调度器想要使用的集群的节点上开始Mesos的任务。然后使Hadoop已经存在的内部的借口来发送Hadoop的任务到这些节点上。当任务结束时,我们的executor通过使用Tasktracker中的一个API 来监听任务结束事件来通知Mesos。
我们使用延迟调度算法,通过等待存有任务输入数据的节点的槽来实现数据的本地化。并且,我们的方法允许我们重用Hadoop已经存在的逻辑来实现重新调度失败的任务以及推测执行(缓解了某些任务始终无法得到处理的问题)。
我们也需要改变Map输出数据的交给Reduce任务。Hadoop正常情况下会将Map的输出文件写到本地的文件系统,然后使用包含在TaskTracker中的一个HTTP server将这些文件发送给Reduce任务。然而,在Mesos中,TaskTracker被当作一个executor运行,当它没有运行任务的时候可能会被终止。这可能会使Reduce任务无法得到Map的输出文件。我们通过在集群中的每个节点提供一个输出本地文件的共享文件服务器来解决这个问题。这样的服务不仅仅对Hadoop有用,对其他的将数据存在在每个节点本地的集群框架同样有用。
我们的Hadoop移植代码总共有1500行。
5.2Torque和MPI移植
我们已经将Torque集群资源管理器作为一个集群框架运行在Mesos上。这个集群框架包含了一个Mesos的调度器和executor来启动和管理Torque的不同组件,使用了360行的Python代码。并且我们修改了3行Torque的源代码来允许它能够在Mesos上依靠它队列中的作业弹性地伸缩。
在注册到Mesos的master进程后,集群框架的调度器设置和启动一个Torque的服务器,然后阶段性地监控server的作业队列。当队列为空时,调度器会释放所有的任务(下降到一个选项的值,这里我们设置为0),然后拒绝从Mesos得到的所有的resource offer。一旦一个作业呗加入到Torque的队列中(使用标准的qsub命令),调度器开始接受新的resource offer。只要Torque的队列中有作业,调度器会接受被提供的资源,用来尽可能满足 尽可能多的作业的必要的约束。在 每个资源提供被接受的节点上,Mesos启动我们的executor,这个executor会依次地开启Torque的后台进程,然后将它注册到Torque的服务器。当有足够数量的后台进程被注册时,Torque的服务器将会在它的队列中启动下一个作业。
由于运行在Torque(比如MPI)的作业可能不是容错的,Torque通过不接受超过它 的被保证的分配的资源,阻止任务被撤回。
除了Torque框架,我们还创建了有个Mesos的MPI“装饰”框架,使用了200行Python代码,从而能够在Mesos上运行MPI作业。
5.3 Spark集群框架
Mesos允许创建专门的集群框架,用于对更多执行层可能不优化的工作负载进行优化。为了测试简单的专门的集群框架是有价值的这个假设,我们通过机器学习的学者,在我们的实验中定义了一类作业,它们在Hadoop上运行的结果很差,被称作“迭代的作业”,在这些作业中,数据集在大量的迭代中重用。我们创建了一个专门的集群框架被称作Spark来优化这些工作负载。
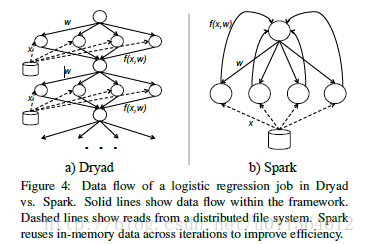
在机器学习中一个使用迭代的算法的例子是逻辑回归。这个算法目的是寻找一条直线,来分离两个被标记的数据点的集合。这个算法开始于一个任意的直线w。然后在每一次迭代中,它会计算一个对象函数的梯度,这个函数用于评测直线分开点的好与坏,并且w沿着这个梯度变化。这种梯度计算相当于计算对于每一个数据点x,一个函数f(x, w)的值,以及这些结果的总和。在Hadoop中逻辑回归的一个实现在运行每次迭代时,必须将每次迭代当做一次独立的MapReduce作业。因为每次迭代都依赖于上一次迭代计算出的w的值。这会增大开销因为每次迭代都必须重新将输入文件读入内存中。在Dryad中全部的作业能够被表达为一个数据流DAG,如图4a所示,但是在每次迭代中数据仍然必须从磁盘中重新加载。在Dryad中,重用相邻两次迭代中内存中的数据会要求数据流的循环。
Spark的执行如图4b中所示。Spark使用Mesos的executor长期运行的特性,来在每个executor中缓存内存中的一片数据集,然后在之后的多次迭代中使用缓存的数据。这种缓存是使用一种可容错的方式实现的:如果一个节点丢失,Spark能够记住如何重新计算在这个节点上的数据。
通过在Mesos的顶层创建Spark,我们能够保持Spark较小的实现代码量(大约1300行代码),然而仍然有能力在迭代的作业上得到比Hadoop高出10倍的效率。特别是,使用Mesos的API节省了我们需要专门为Spark写一个master后台进程、slave后台进程和它们之间的通信协议的时间。我们代码的主要部分是一个集群框架调度器(为实现本地化使用延迟调度)以及用户API。
6 评测
我们通过在Amazon Elastic Compute Cloud(EC2)上一系列的实验来评测Mesos。我们开始于大量的benchmark工具来评测这个系统在四个工作负载中如何共享资源,并且继续展示一系列设计的小的实验来评测开销,非中心化调度和我们的专门的集群框架Spark,可扩展性以及容错能力。
6.1Macrobenchmark
为了评测Mesos的主要实现目的,也就是使得多个集群框架能够高效地共享集群,我们运行了一个包括4种负载混合的macrobenchmark。
* 一个Hadoop实例,混合运行着基于Facebook上的工作负载的小作业和大作业。
* 一个Hadoop实例,运行着一系列大的批处理作业。
* Spark,运行着一系列机器学习作业。
* Torque,运行着一系列MPI作业。
我们对在96节点的Mesos集群上使用公平共享运行4个集群框架作为工作负载的应用场景与对每个框架进行静态分配的应用场景进行对比(一个集群框架24个节点),并且对两个测试用例测试了作业的响应时间和资源利用率。我们使用EC2的节点,每个节点有4个CPU核和15GB 的RAM。
我们从更仔细地描述4个工作负载开始,然后展示我们的结果。
6.1.1 Macrobenchmark的工作负载
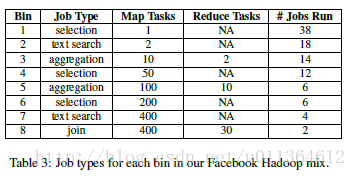
Facebook Hadoop 混合 文献38提到,我们的Hadoop混合作业是基于在Facebook上作业大小和间隔时间的分布。工作负载包括在25分钟内特定的时刻提交的100个作业,平均的间隔时间是14s。大多数作业是小的(1-12个任务),也有达到400个任务的大作业。作业来自Hive benchmark,其中包括四种类型的查询:文本搜索、一个简单的选择、一个聚合和连接被转换成多个MapReduce的步骤。我们将这些作业按照作业的类型和大小分为了8组(在表3中列出),从而我们能够在每一组中比较性能。由于Facebook中在使用公平共享,我们也会在它的作业之间设置集群框架的调度器来运行公平共享。
大型Hadoop混合 为了评估需要连续运行的批处理的工作负载,比如网络爬虫,我们有第二种Hadoop的实例运行一系列含有2400个任务的IO密集型文本搜索作业。在这些作业上运行着一个脚本,每一个在前一个完成之后会被提交。
Spark 我们在Spark上运行五个迭代的机器学习作业的实例。在每次作业结束的2分钟后,一个脚本会启动提交下一个作业。我们使用的作业是交替最小二乘法(ALS),一种协同过滤算法。这个作业是CPU密集型的,但是能够通过在每个节点缓存它的输入数据提高性能,并且需要在每次迭代中运行它的任务的所有节点广播更新的参数。
Torque/MPI 我们的Torque集群框架运行了8个tachyon涉嫌跟踪作业的实例,这个作业是SPEC MPI2007 benchmark的一部分。其中6个作业运行小问题,而2个作业运行大问题。两种类型的作业都是用24个并行的任务。我们在特定的时刻提交这两个任务到两个集群。tachyon作业是CPU密集的。
6.1.2 Macrobenchmark的结果
Mesos的成功的结果表明两件事情:Mesos比静态分区得到了更高的使用率,并且昨晚完成至少比静态分区共享集群快,并且可能由于其他集群框架的需求的差异而变得更快。我们的结果表明了这两个影响,在下面具体说明。
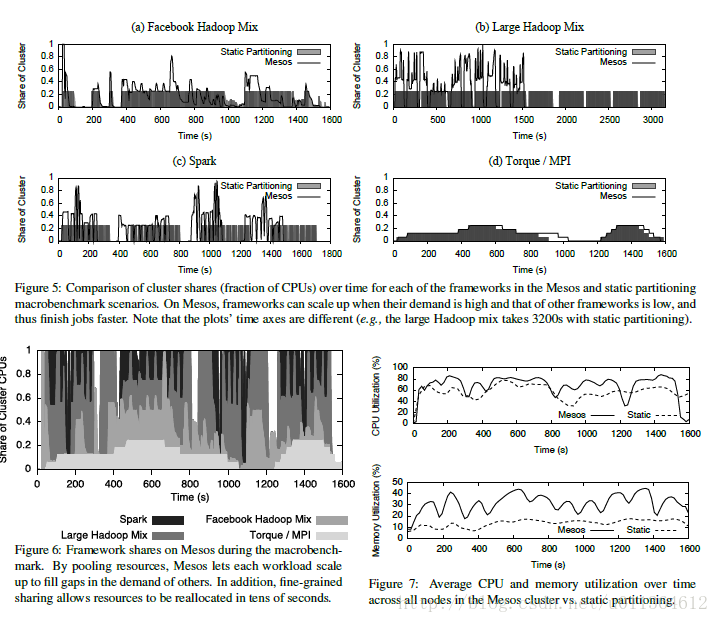
我们在图6中说明Mesos在一段时间内分配给每个集群框架的CPU 核的比率。我们看到Mesos使得每个集群框架在其他集群框架有低需求的时候能够扩展,并且因此使得集群节点更忙。例如,在350时刻,当Spark和Facebook Hadoop集群框架没有运行作业时,Torque正在使用集群1/8的资源,而大作业Hadoop集群框架扩展到了集群的7/8。并且我们看到由于任务的细粒度特性,资源被重新分配得很快。(在大概360时刻,当Facebook Hadoop作业开始)。最后,更高的节点资源的分配被转换为更高的CPU和内存的使用率。(CPU提高了10%,内存提高了17%),如图7所示。
第二个问题是,作业在Mesos下运行比静态分配集群的情况下运行得有多好。我们使用两种方式表明这个数据。首先,图5比较了在共享和静态分配集群中,每个集群框架在一段时间内资源分配情况。阴影部分表示静态分配集群中的资源分配,实线区域表示在Mesos上共享的资源。我们看到当整体需求允许的情况下,细粒度的集群框架(Hadoop和Spark)利用Mesos扩展到了超过集群的1/4,结果是在Mesos上,结果是在Mesos上更快地提交了作业。同时,Torque在Mesos下完成了相似的资源分配以及作业运行期限。(有一些不同之处,下面详细说明)
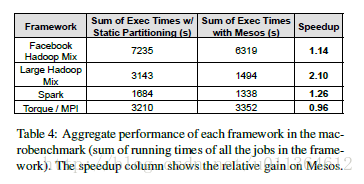
第二,表4和表5说明了每个集群框架的作业运行效率的变化。在表4中,我们比较了每个集群框架的整体性能,这被定义为在静态分配集群和Mesos场景中作业运行时间的总和。我们看到Hadoop和Spark作业在Mesos上整体运行得较快,而Torque轻微地变慢。获得最大提升的集群框架是大作业混合Hadoop,它总是有任务运行,并且会将其他集群框架需求的间隙填满,这个集群框架在Mesos上表现出2倍的效率提升。
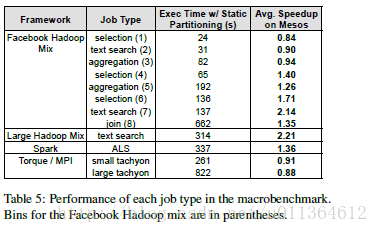
表5在类型上更具体地比较了结果。我们观察到两个值得注意的趋势。首先在Facebook Hadoop混合测试中,小作业在Mesos上运行得更差。这是因为在Hadoop上的公平共享(在它的作业之间)和Mesos上的公平共享(在不同集群框架之间)之间的相互作用:在Hadoop拥有集群1/4的资源期间,Hadoop在得到新的resource offer时会有延迟(因为任何被清空的资源都会被分配到与它共享的最远的集群框架)。所以在这段时间内,任何提交的小作业都会相比于它的运行期限延迟较长的时间。相反的,当单独运行时,Hadoop能够在任何任务结束的时候尽快给新的作业提供资源。这个层次性的公平共享问题在网络[34]也会出现,能够通过在一个独立的集群框架中运行小作业或者使用不同的分配策略来缓解这个问题。(比如,使用彩票调度而不是将所有的被清理的资源提供给得到最小共享的集群框架)
最后,Torque是在Mesos上平均情况下,仅有表现更差的集群框架。大型的tachyon作业花费平均2分钟的时间,而小型的作业平均花费20s的时间。这种延迟是因为在开始每一个作业之前,在Mesos上必须等待启动24个任务,但是这平均花费的时间是12s。我们相信剩下的延迟是因为“落伍的节点”。(慢的节点)。在我们单独运行Torque时,我们看到有两个作业比其他的作业多花费了60s的时间。我们发现这两个作业使用了一个运行单节点benchmark较慢的节点(事实上,Linux报告40%低的bogomips)。因为tachyon在每个节点上提交相等数量的工作,它会和最慢的节点的速度相同
6.2 开销
为了评估当一个单一的集群框架在使用集群时,Mesos带来的开销,我们在一个有50个节点的EC2集群上使用MPI和Hadoop运行两个benchmark,每个节点上有2个CPU核和6.5GB RAM。我们在MPI中使用High-Performance LINPACK的benchmark,在Hadoop中使用WordCount作业,并且每个作业运行3次。没有Mesos,MPI作业平均消耗50.9s,有Mesos时,消耗51.8s。没有Mesos,Hadoop作业消耗160s,有Mesos,消耗166s。在两个测试实例中,Mesos的消耗都低于4%。
6.3 通过延迟调度实现数据本地化
在本次实验中,我们评测Mesos的资源提供机制是如何使得集群框架能够控制它们的位置的,特别是数据本地性。我们使用93个EC2节点运行了Hadoop的16个实例。每个节点有4个CPU核和15GB RAM。 每个节点运行了一个仅仅扫描map的作业,这个作业要查找分散在集群中的共享的HDFS文件系统上的100GB的文件,并且输出1%的记录。我们测试4中场景:给每个Hadoop对集群进行静态划分的5-6个节点(为了模拟组织使用粗粒度的集群共享系统),并且在Mesos运行所有的实例,使用没有延迟的调度、1s延迟的调度或者5s延迟的调度。
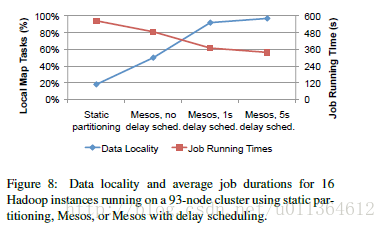
如图8所示,是16个Hadoop实例在每种场景的三次运行的平均测量结果。使用静态分区会产生非常低的数据本地性(18%)因为Hadoop实例会被迫从它们分区之外的节点上获取数据。相反的,在Mesos上运行Hadoop实例,即使没有延迟调度,仍然提高了数据本地性,因为每个Hadoop实例会在更多的节点上运行任务(每个节点上有4个任务),因此能够在本地访问更多的数据块。增加1s的延迟,使得数据本地化达到了90%,而5s的延迟则达到了95%的数据本地化,这是与将Hadoop实例单独运行在整个集群上是相当的。正如我们所期待的,使用数据本地化,作业运行效率提高了:在5s的延迟调度的场景中比静态分区场景作业运行速度提升了1.7倍。
6.4 Spark集群框架
我们通过通用目标的Hadoop集群框架评测我们开发在Mesos顶层的专门运行迭代作业的集群框架Spark的优势。我们在我们的实验中使用由机器学习学者完成的在Hadoop中实现的一个逻辑回归作业,然后使用Spark写作业的第二个版本。我们在20个EC2节点上分开地运行每一个版本,每个节点有4个CPU核和15GB RAM。每个实验都是用29GB的数据文件,并且从1到30变化逻辑回归的迭代的次数。(查看图9)
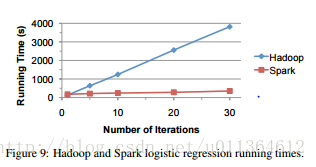
使用Hadoop,每次迭代平均花费127s,这是因为每次迭代都被当做一个分离的MapReduce作业。相反的,使用Spark,第一个迭代花费174s,但是后面的迭代仅仅花费6s,这导致在30次迭代的情况下10倍速度的提升。这是因为从磁盘上读取数据并且分析数据的代价远高于每次迭代中作业计算梯度函数的代价。Hadoop在每次迭代都会引发读取和分析的代价,而Spark会重用被分析的数据的缓存块,并且仅仅会承受一次这样的代价。Spark在第一次迭代运行了更长的时间是因为使用了较短的文本分析过程。
6.5 Mesos可扩展性
为了评测Mesos的可扩展性,我们通过使用99个Amazon EC2的节点上运行高达50000个slave后台进程来进行模拟,每个节点上有8个CPU核和6GB的RAM。我们使用1个EC2节点当作主节点,而其他的节点则会运行slave后台进程。在实验中,全部集群的200个集群框架中每一个都连续地运行任务,在每一个节点上开启一个已经得到resource offer的任务。每个任务会休眠一段时间,这个时间会基于一个均值为30s、标准差为10s的正态分布,然后结束。每个slave节点至多同时运行两个任务。
一旦集群达到稳态(即,200个集群框架达到了公平共享,而且所有的资源被分配),我们启动了一个测试的集群框架来启动一个单一的10s的任务,然后测试这个任务需要多长时间完成。这允许我们能够计算由于必须要注册到master进程、等待一个resource offer、接受resource offer、等待一个master进程来处理响应以及在一个节点上运行任务,以及等待mesos报告任务作为结束,这些过程所消耗的10s以外的延迟时间。
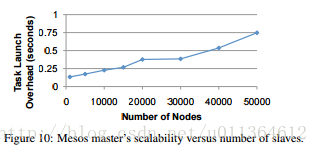
在图10中,我们将这个延迟时间绘制了一条曲线,图中所示是5个运行的平均时间。我们观察到即使到50000个节点,开销也保持得很少(小于1s)。特别是,这个开销远小于数据中心工作负载下任务和作业完成的平均时间(参见第二部分)。由于Mesos也会保持集群全部被分配,这意味着集群必须跟踪Mesos上面的负载。不幸的是,EC2的虚拟化环境限制了slave节点的数量,必须在50000节点以下。这是因为当有50000个slave节点时,master进程每秒需要处理100000个数据包(进出),这是EC2能够达到的极限值。
6.6 错误恢复
为了评测从master进程故障恢复的能力,我们展开了一个实验,实验中使用62个EC2的节点,共有200到4000个slave后台进程,每个节点上有4个核和15GB的RAM。我们运行200个每次都运行20s长的任务的集群框架,以及连接了规定含有5个节点的Zookeeper的两个Mesos主节点。我们使用NTP同步两个主节点的时钟,并且在杀死活
动的主节点之后计算恢复的平均时间(MTTR)。MTTR是所有的slave节点和集群框架连接到第二个主节点的时间。在所有的测试用例中,MTTR在4-8s之间,而其中3s的置信区间达到95%。
6.7 性能隔离
正如我们在3.4中讨论的那样,Mesos在相同的slave节点上运行的不同的集群框架之间利用已经存在的操作系统隔离机制提供性能的隔离。尽管这些机制不是完美的,一份关于Linux Container的性能评测显示出希望之中的结果。特别是,使用容器来隔离MediaWiki网络服务(包含大量运行PHP的Apache进程)和一个“hog”应用程序(包含256个无限循环轮转的进程)的CPU的使用只表现出30%的请求延迟的增加,而不用容器运行这两个程序会导致550%的请求延迟的增加。我们建议读者阅读[29],获取更加详细的操作系统隔离机制的评测。
7 相关工作
HPC和网格调度器。高性能计算(HPC)社区长时间得管理着集群。然而它们典型的目标环境包括专门的硬件,比如无线带宽技术和SANs,使用这些技术,作业不必调度到存储数据的本地计算机。此外,通过使用barriers技术和消息传送技术,每项作业都能紧密地结合。因此每项作业都是整体的,而不是被分割成细粒度的任务,并且在它的生命周期中不能改变它的资源需求。由于这些原因,HPC的调度器使用中心调度,并且要求用户在在提交作业时声明要求的资源。作业之后会被赋予集群的粗粒度的分配。此外,作业不能动态地增长和伸缩。相反,Mesos支持在任务的级别支持细粒度的共享,并且集群框架控制它们的位置。
网格计算大部分关注使得多样化的虚拟组织能够使用一种安全和共同操作的方式共享地理位置上分布式的和分开管理的资源。
公有云和私有云。虚拟化云比如Amazon EC2和Eucalyptus与Mesos有着相同的目标,比如隔离进程的同时提供一个底层的抽象(虚拟机)。然而它们和Mesos在许多重要的方面是不同的。首先,相比于Mesos,它们相关的粗粒度的虚拟机的分配模型会导致更少的有效的资源利用率和数据的共享。其次,这些系统不能让应用程序指定位置的需求超过它们要求的虚拟机的大小。相反的,Mesos允许集群框架对于任务有较高的选择权。
**Quincy。**Quincy是一个Dryad的公平调度器,使用了Dryad的基于DAG的编程模型的中心调度算法。相反的,Mesos提供了一个提供模型的底层的抽象来支持多集群计算框架。
**Condor。**Condor集群管理器使用了ClassAds语言来讲作业匹配到节点上。使用资源的规范性语言不会比使用resource offer的集群框架更灵活,因为不是所有的要求都是可以表达的。而且,移植已经存在的有自己的调度器的集群框架,到Condor是比移植到Mesos更困难的,在Mesos中已经存在的调度器能够很自然地契合Msos的两级调度模型。
下一代Hadooop。最近,Yahoo!宣布要重新设计Hadoop,这一代Hadoop将使用两级调度模型,并且每个应用程序的管理器从中心管理器中请求资源。其设计的目的旨在支持非MapReduce的应用程序。这个系统的调度模型的细节现在不能得到,我们相信新的应用程序管理者会自然得运行在Mesos的集群框架中。
8 结论和未来的工作
我们已经展示了Mesos,一个轻薄的,允许多样化集群框架有效共享资源的管理层。Mesos围绕着两个设计元素:一个在task级别的细粒度的共享模型和一个被称作resource offers分布式调度机制。这两个元素使得Mesos能够获得高的使用率,对工作负载的改变响应快速,并且满足了对多个集群框架保持可扩展性和鲁棒的需要。我们已经说明使用Mesos,已经存在的集群框架能够有效地共享资源,Mesos能够支持开发专业的集群框架来提供主要的性能收益,比如Spark,并且Mesos的简单的设计允许系统容错,可以扩展到50000个节点。
在未来的工作中,我们计划分析resource offer模型,并且决定使用哪个插件来提升它的有效性同时保持它的灵活性。特别的,它可能加入对资源提供表达更丰富的资源需求的集群框架,并且选择哪个任务使用哪一类资源运行,从而使得它们的发展不会受到系统提供的语言的约束。
我们目前正在使用Mesos在我们的实验室中管理40个节点的集群以及Twitter的测试部署中。并且我们计划在未来的工作中报告这些部署的经验和教训。
9 鸣谢
我们感谢在Google、Twitter、Facebook、Yahoo!和Cloudera的行业同事,感谢他们对Mesos的大量反馈。这一片调研得到了来自California MICRO, California Discovery、the Natural Sciences以及加拿大的Engineering Research Council,一个国家的教育科学基金会研究奖学金,瑞典研究理事会,和下面的伯克利RAD实验室赞助商:Google、Microsoft、Orcacle、Amazon、Cisco、Cloudera、eBay、Facebook、Fujitsu、HP、Intel、NetApp、SAP、VMware和Yahoo!。














 1212
1212











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









