










Lucene 是一个高效的基于java的全文索引库。
全文检索的索引的创建过程一般有以下几步:
如何创建索引:
第一步:准备需要索引的原始文档数据集(Document)
文件格式有多种。本文以文本用一般的txt、word和excel文档作为示例数据集。
第二步:将原文档传给分词组件(Tokenizer)
- 将文档分成一个个单独的词
- 去除标点符号
- 去除停用词(stop word)
第三步:将得到的词元(Token)传给自然语言处理组件(Linguistic Processor)
比如对英文常见的一些操作:
4. 将大写变为小写(Lowercase)
5. 将单词缩减为词根形式,如”cars”到”car”等,这种操作叫做stemming词干提取
6. 将单词转变为词根形式,如”drove”到”drive”等,这种操作叫做lemmatization词形还原
第四步:将得到的词(Term)传给索引组件(Indexer)
- 利用得到的词(Term)创建一个字典
- 对字典按字母顺序进行排序
- 合并相同的词(Term)成为文档倒排(Posting List)链表
如何对索引进行搜索:
第一步:用户输入查询语句
可以直接进行查询,也可以根据field进行查询
第二步:对查询的语句进行词法分析、语法分析以及语言处理
- 词法分析,主要用来识别单词和关键字
- 语法分析,主要是根据查询语句的语法规则来形成一颗语法树,如 and、or等关系可以构成一个简单的语法树
- 语言处理,和索引过程中的语言处理几乎相同
第三步:搜索索引,得到符合语法树的文档
例如 对and 和or构成的语法树进行分析处理:
- 首先,我们要先在反向索引表中,分别找出这几个关键字对对应的文档链表
- 其次,要对包含关键字的链表进行合并操作,得到满足and条件的文档链表
- 然后,将上一步满足条件的链表进行or操作,从而得到最终满足条件的文档链表。
- 该文档链表就是满足我们查询条件的文档
第四步:根据得到的文档个查询语句的相关性,对结果进行排序
排序的算法比较多,一般会经历下面几个过程:
1. 计算权重(Term weight)的过程
2. 向量空间模型算法(VSM : Vector Space Model):判断Term之间的关系,从而得到文档相关性的过程
简单代码实现:
函数主入口:
package com.bubble.lucene.test;
import java.io.File;
import com.zte.lucene.IndexManager;
import com.zte.lucene.tools.Toolkits;
public class DemoTest {
public static void main(String[] args) {
File fileIndex = new File(IndexManager.INDEX_DIR);
if (Toolkits.deleteDir(fileIndex)) {
fileIndex.mkdir();
} else {
fileIndex.mkdir();
}
IndexManager.createIndex(IndexManager.DATA_DIR);
IndexManager.searchIndex("content", "hello");
}
}
主要方法:创建索引和查找索引过程
package com.bubble.lucene;
import java.io.File;
import java.io.IOException;
import java.util.Date;
import java.util.List;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.standard.StandardAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field.Store;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.ScoreDoc;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import com.zte.lucene.tools.Toolkits;
/**
*
* @author root
*
*/
public class IndexManager {
private IndexManager indexManager;
private static String content = "";
public static String INDEX_DIR = "/root/data/lucene/luceneIndex";
public static String DATA_DIR = "/root/data/lucene/luceneData";
private static Analyzer analyzer = null;
private static Directory directory = null;
private static IndexWriter indexWriter = null;
/**
* 创建索引管理器
* @return 返回索引管理器对象
*/
public IndexManager getManager() {
if (indexManager == null) {
this.indexManager = new IndexManager();
}
return indexManager;
}
/**
* 创建当前文件目录的索引
* @param path 当前文件目录
* @return 是否成功
*/
public static boolean createIndex(String path) {
Date startDate = new Date();
long startTime = startDate.getTime();
List<File> fileList = Toolkits.getFileLIst(path);
for (File file : fileList) {
content = "";
//获取文件后缀
String type = file.getName().substring(file.getName().lastIndexOf(".")+1);
if ("txt".equalsIgnoreCase(type)) {
content += Toolkits.txt2String(file);
} else if ("doc".equalsIgnoreCase(type)) {
content += Toolkits.doc2String(file);
} else if ("xls".equalsIgnoreCase(type)) {
content += Toolkits.xls2String(file);
}
System.out.println("path is : "+ file.getPath() + " ,file name is : " + file.getName());
System.out.println("-- content : " + content);
try {
analyzer = new StandardAnalyzer();
directory = FSDirectory.open(new File(INDEX_DIR).toPath());
File indexFile = new File(INDEX_DIR);
if (!indexFile.exists()) {
indexFile.mkdirs();
}
IndexWriterConfig config = new IndexWriterConfig(analyzer);
indexWriter = new IndexWriter(directory, config);
Document document = new Document();
document.add(new TextField("fileName", file.getName(), Store.YES));
document.add(new TextField("content", content, Store.YES));
document.add(new TextField("path", file.getPath(), Store.YES));
indexWriter.addDocument(document);
indexWriter.commit();
Toolkits.closeIndexWrite(null, indexWriter, null);
} catch (IOException e) {
e.printStackTrace();
}
content = "";
}
try {
analyzer = new StandardAnalyzer();
directory = FSDirectory.open(new File(INDEX_DIR).toPath());
File indexFile = new File(INDEX_DIR);
if (!indexFile.exists()) {
indexFile.mkdirs();
}
IndexWriterConfig config = new IndexWriterConfig(analyzer);
indexWriter = new IndexWriter(directory, config);
Document document = new Document();
document.add(new TextField("fileName", "test fileName", Store.YES));
document.add(new TextField("content", "hello world", Store.YES));
document.add(new TextField("path", "hello path", Store.YES));
indexWriter.addDocument(document);
indexWriter.commit();
Document document2 = new Document();
document2.add(new TextField("fileName", "test fileName2", Store.YES));
document2.add(new TextField("content", "hello world 2", Store.YES));
document2.add(new TextField("path", "hello path2", Store.YES));
indexWriter.addDocument(document2);
indexWriter.commit();
Toolkits.closeIndexWrite(null, indexWriter, null);
} catch (IOException e) {
e.printStackTrace();
}
content = "";
Date endDate = new Date();
long endTime = endDate.getTime();
System.out.println("START : 创建索引-----耗时:" + (endTime - startTime) + "ms\n");
return true;
}
/**
* 查找索引,返回符合条件的文件
* @param field 要查找的域名
* @param text 查找的字符串
* @return 符合条件的文件List
*/
public static void searchIndex(String field, String text) {
Date date = new Date();
long startTime = date.getTime();
try {
directory = FSDirectory.open(new File(INDEX_DIR).toPath());
analyzer = new StandardAnalyzer();
DirectoryReader iReader = DirectoryReader.open(directory);
IndexSearcher indexSearcher = new IndexSearcher(iReader);
QueryParser parser = new QueryParser(field, analyzer);
Query query = parser.parse(text);
ScoreDoc[] hits = indexSearcher.search(query, 10).scoreDocs;
for (int i = 0; i < hits.length; i++) {
Document hitDoc = indexSearcher.doc(hits[i].doc);
System.out.println(hitDoc.get("fileName") + " content = " + hitDoc.get("content"));
}
Toolkits.closeIndexWrite(directory, null, iReader);
} catch (Exception e) {
e.printStackTrace();
}
long endTime = date.getTime();
System.out.println("END : 查看索引-----耗时:" + (endTime - startTime) + "ms\n");
}
}
Maven的pom.xml配置文件:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.zte</groupId>
<artifactId>lucenedemo</artifactId>
<packaging>war</packaging>
<version>0.0.1-SNAPSHOT</version>
<name>lucenedemo Maven Webapp</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<lucene.version>6.5.0</lucene.version>
<poi.version>3.15</poi.version>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<!--加入lucene -->
<!-- https://mvnrepository.com/artifact/org.apache.lucene/lucene-core -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-core</artifactId>
<version>${lucene.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.lucene/lucene-queryparser -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-queryparser</artifactId>
<version>${lucene.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.lucene/lucene-analyzers-common -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-common</artifactId>
<version>${lucene.version}</version>
</dependency>
<!--lucene中文分词 -->
<!-- https://mvnrepository.com/artifact/org.apache.lucene/lucene-analyzers-smartcn -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-analyzers-smartcn</artifactId>
<version>${lucene.version}</version>
</dependency>
<!--lucene高亮 -->
<!-- https://mvnrepository.com/artifact/org.apache.lucene/lucene-highlighter -->
<dependency>
<groupId>org.apache.lucene</groupId>
<artifactId>lucene-highlighter</artifactId>
<version>${lucene.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.poi/poi -->
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi</artifactId>
<version>${poi.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.poi/poi-ooxml -->
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml</artifactId>
<version>${poi.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.poi/poi-scratchpad -->
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-scratchpad</artifactId>
<version>${poi.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.poi/poi-ooxml-schemas -->
<dependency>
<groupId>org.apache.poi</groupId>
<artifactId>poi-ooxml-schemas</artifactId>
<version>${poi.version}</version>
</dependency>
<dependency>
<groupId>net.sourceforge.jexcelapi</groupId>
<artifactId>jxl</artifactId>
<version>2.6.12</version>
</dependency>
</dependencies>
<build>
<finalName>lucenedemo</finalName>
</build>
</project>
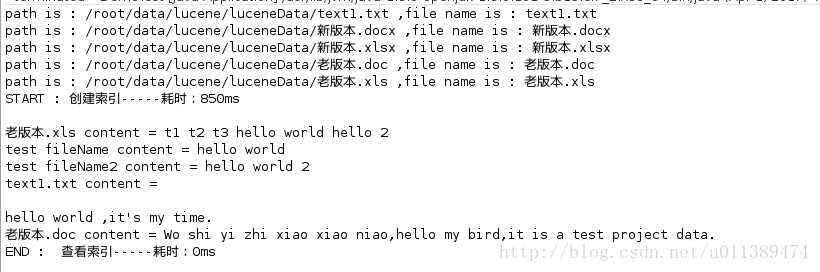
测试结果:















 2783
2783

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









