







 本文讨论了在面临高数据读写压力时,如何实施读写分离策略。介绍了利用数据库自身的数据复制功能,如MySQL的Master-Slave结构,以及数据复制可能带来的时延和不一致问题。此外,还探讨了缓存系统在加速数据读取中的作用,包括缓存填充策略和保持数据一致性的方法。
本文讨论了在面临高数据读写压力时,如何实施读写分离策略。介绍了利用数据库自身的数据复制功能,如MySQL的Master-Slave结构,以及数据复制可能带来的时延和不一致问题。此外,还探讨了缓存系统在加速数据读取中的作用,包括缓存填充策略和保持数据一致性的方法。
(1)采用数据库作为读库
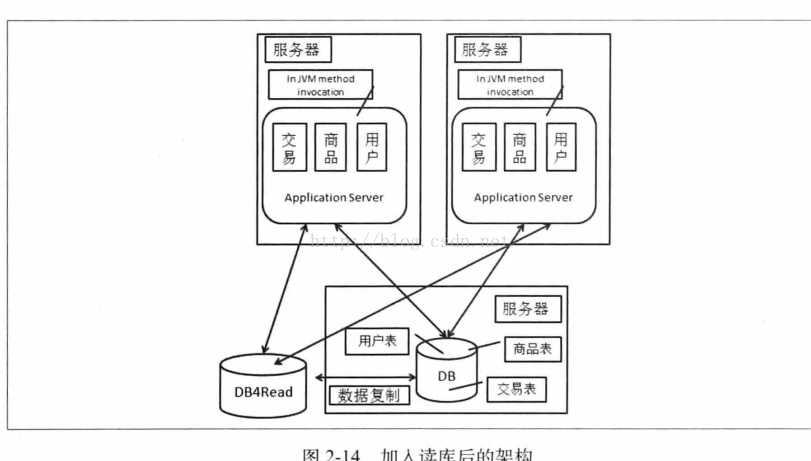
问题:数据复制问题。应用对于数据源的选择问题。
数据库系统一般都提供了数据复制的功能,我们可以直接使用数据库系统的自身机制,对于数据复制,我们还要考虑时延问题,以及复制中数据源和目标之间的映射关系和过滤条件的支持问题。数据复制延迟带来是短期数据不一致,例如修改了用户信息,但还没有复制到读库(因为时延),那么读出来的就不是最新的。
不同的数据库有不同的支持,MySQL支持Master(主库)+Slave(备库)的结构,提供了数据复制的机制,MySQl5.5之前支持的是异步的数据复制,主库执行完一些事务后,是不会管备库的进度的,若备库落后,主库有出现crash,这事备库的数据就是不完整的,我们无法使用备库来继续提供数据一致的服务了。会有延迟,并且提供的是完全镜像方式的复制,保证主库和备库数据一致性(不考虑时延),MySQL5.5
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2614
2614

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









