







-
刘玉龙
-
原创作品转载请注明出处
《Linux内核分析》MOOC课程http://mooc.study.163.com/course/USTC-1000029000
刘玉龙
原创作品转载请注明出处
《Linux内核分析》MOOC课程http://mooc.study.163.com/course/USTC-1000029000
一、进程调度简析
我们知道现在的操作系统想要看起来很流程必须在后台进行快色的任务切换,才能达到表面上是哪个的多个进程同时执行的错觉。进程的切换我们实际上我之前的文章中已经有说过了,实际上进程的切换正式为了进程的调度做基础性的功能准备,这个不用说就能理解吧~调度自认就是要不停顿切换了。
在典型的Unix操作系统的调度算繁重必须实现几个相互冲突的目标:那就是不但进程的响应时间要很快的同时,我们又要保证后台进程或者说人物执行的吞吐量要高,不要出现进程的饥饿现象(就是有些进程总也不能被执行),这就需要保证进程的优先级无乱高低又要尽可能的被公平的执行,这就是调度要解决的一系列问题。也就是我们常常说的进程调度策略。
Linux的调度基于分时技术:所谓的分时就是指将时间划分成很小很小的片段,然后每个片段都相对公平的分给这一时刻需要执行的任务。这就我们所说的时间片调度。比如现在有是10个任务需要同时进行,每个任务都必须在1s内得到回馈,这样我么可以把1s分成10份,每过0.1s切换一个任务执行,这样宏观上看就是大家在同时的推进,当然实际上操作系统的时间片要小的多,比如1纳秒之类的。
进程的调度时机与进程的切换
操作系统原理中介绍了大量进程调度算法,这些算法从实现的角度看仅仅是从运行队列中选择一个新进程,选择的过程中运用了不同的策略而已。
对于理解操作系统的工作机制,反而是进程的调度时机与进程的切换机制更为关键。
进程调度的时机
·
·
·
进程的切换
·
·
·
·
包括程序代码,数据,用户堆栈等
·
:进程描述符,内核堆栈等
·
·
·next = pick_next_task(rq, prev);//进程调度算法都封装这个函数内部
·context_switch(rq, prev, next);//进程上下文切换
·
1.
2.
3.
10.40
11.41
12.42
13.43
14.44
15.45
16.46
17.47
18.48
19.49
20.50
21.51
22.52
23.53
24.54
25.55
26.56
27.57
28.58
29.59
30.60
31.61
32.62
33.63
34.64
35.65
36.66
37.67
38.68
39.69
40.70
41.71
42.72
43.73
44.74
45.75
46.76
47.77}
进程调度与进程调度的时机分析
=====================================
Linux系统的一般执行过程
最一般的情况:正在运行的用户态进程X切换到运行用户态进程Y的过程
1.
2.
3.
4.
5.
6.restore_all //恢复现场
7.
8.
几种特殊情况
·
·
·
·
1 #define switch_to(prev,next,last) do { \
2 asm volatile("pushl %%esi\n\t" \
3 "pushl %%edi\n\t" \
4 "pushl %%ebp\n\t" \
5 "movl %%esp,%0\n\t" /* save ESP */ \
6 "movl %3,%%esp\n\t" /* restore ESP */ \
7 "movl $1f,%1\n\t" /* save EIP */ \
8 "pushl %4\n\t" /* restore EIP */ \
9 "jmp __switch_to\n" \
10 "1:\t" \
11 "popl %%ebp\n\t" \
12 "popl %%edi\n\t" \
13 "popl %%esi\n\t" \
14 :"=m" (prev->thread.esp),"=m" (prev->thread.eip), \
15 "=b" (last) \
16 :"m" (next->thread.esp),"m" (next->thread.eip), \
17 "a" (prev), "d" (next), \
18 "b" (prev)); \
19 } while (0)
switch_to宏是用嵌入式汇编写成,比较难理解,为描述方便起见,我们给代码编了行号,在此我们给出具体的解释:
· thread的类型为前面介绍的thread_struct结构。
· 输出参数有三个,表示这段代码执行后有三项数据会有变化,它们与变量及寄存器的对应关系如下:
0%与prev->thread.esp对应,1%与prev->thread.eip对应,这两个参数都存放在内存,而2%与ebx寄存器对应,同时说明last参数存放在ebx寄存器中。
· 输入参数有五个,其对应关系如下:
3%与next->thread.esp对应,4%与next->thread.eip对应,这两个参数都存放在内存,而5%,6%和7%分别与eax,edx及ebx相对应,同时说明prev,next以及prev三个参数分别放在这三个寄存器中。表5.1列出了这几种对应关系:
表5.1
| 参数类型 | 参数名 | 内存变量 | 寄存器 | 函数参数 |
| 输出参数 | 0% | prev->thread.esp |
|
|
| 1% | prev->thread.eip |
|
| |
| 2% |
| ebx | last | |
| 输入参数 | 3% | next->thread.esp |
|
|
| 4% | next->thread.eip |
|
| |
| 5% |
| eax | prev | |
| 6% |
| edx | next | |
| 7% |
| ebx | prev |
· 第2~4行就是在当前进程prev的内核栈中保存esi,edi及ebp寄存器的内容。
· 第5行将prev的内核堆栈指针ebp存入prev->thread.esp中。
· 第6行把将要运行进程next的内核栈指针next->thread.esp置入esp寄存器中。从现在开始,内核对next的内核栈进行操作,因此,这条指令执行从prev到next真正的上下文切换,因为进程描述符的地址与其内核栈的地址紧紧地联系在一起(参见第四章),因此,改变内核栈就意味着改变当前进程。如果此处引用current的话,那就已经指向next的task_struct结构了。从这个意义上说,进程的切换在这一行指令执行完以后就已经完成。但是,构成一个进程的另一个要素是程序的执行,这方面的切换尚未完成。
· 第7行将标号“1”所在的地址,也就是第一条popl指令(第11行)所在的地址保存在prev->thread.eip中,这个地址就是prev下一次被调度运行而切入时的“返回”地址。
· 第8行将next->thread.eip压入next的内核栈。那么,next->thread.eip究竟指向那个地址?实际上,它就是 next上一次被调离时通过第7行保存的地址,也就是第11行popl指令的地址。因为,每个进程被调离时都要执行这里的第7行,这就决定了每个进程(除了新创建的进程)在受到调度而恢复执行时都从这里的第11行开始。
· 第9行通过jump指令(而不是 call指令)转入一个函数__switch_to()。这个函数的具体实现将在下面介绍。当CPU执行到__switch_to()函数的ret指令时,最后进入堆栈的next->thread.eip就变成了返回地址,这就是标号“1”的地址。
· 第11~13行恢复next上次被调离时推进堆栈的内容。从现在开始,next进程就成为当前进程而真正开始执行。
=======================1.1进程调度相关的数据结构
task_struct
task_struct是进程在内核中对应的数据结构,它标识了进程的状态等各项信息。其中有一项thread_struct结构的变量thread,记录了CPU相关的进程状态信息,如内核控制的断点和栈指针等。在内核中获得当前进程task_struct结构使用宏current,该宏读取变量current_task得到指针。
thread_union thread_info
thread_union用于表示一个进程的内核态堆栈,当进程进入内核态时就会使用该进程对应的内核态堆栈。thread_union是一个联合体,由stack和thread_info两项组成。其中的stack用于直接访问内核态堆栈的各项,而thread_info表示了堆栈顶部(低地址部分)用于特殊用途的部分。thread_info结构定义在include/asm-x86/thread_info_32.h,定义了本进程task_struct结构的指针等在进入内核初期马上要访问的辅助数据。在内核中得到当前thread_info用current_thread_info函数得到,它通过对当前栈指针进行计算得到thread_info的指针。
sched_class
sched_class是Linux2.6中调度算法对外的统一界面。Linux使用这个概念将进程调度的具体策略和进程切换的过程隔离开,使得组织有序且可以实现对不同类进程采用不同的调度策略。在Linux-2.6.26中sched_class有fair_sched_class,rt_sched_class和idle_sched_class三个实例,分别组织在kernel下的sched_fair.c、sched_rt.c、sched_idletask.c中。这三个实例在初始化时被串成了一个链表,依次为:rt,fair,idle
sched_entity sched_rt_entity
内核中对sched_entity的解释为“CFS stats for a schedulable entity (task, task-group etc)”,sched_rt_entity可类似解释。从这里可以看出这个结构的作用是存储一些调度算法相关的进程的状态。
rq
rq是当前CPU上就绪进程所组织成的队列。这个结构体记录了每个队列的状态。rq结构体中有cfs_rq和rt_rq两个子结构,分别描述了该CPU上fair类型和rt类型进程的信息。
1.2 关于schedule函数的简析
(其实应该放在实验里说的呢~强迫症犯了于是就放在1.2吧,看起来结构上好一些)schedule函数是进程调度的入口,在kernel/sched.c中。除去繁琐的检查、统计、上锁等操作,仔细观察,其主流如下:
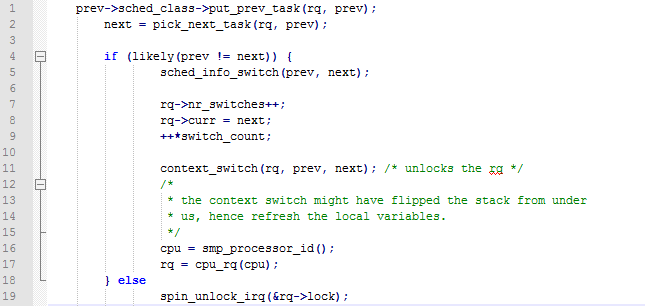
第一句中的prev在之前被赋值为rq->curr,因此是当前运行队列正在运行的进程。从字面看是将当前进程放回队列。第二句是从队列中取出下一个可运行的进程,叫next。接下来是进程的上下文切换工作。首先判断prev和next是否是同一个进程,若是,则不必切换。否则统计信息,接着设置rq->curr为next,然后调用context_switch来进行实际的上下文切换。schedule函数的简要分析结束。可见,理解进程的调度,核心是put_prev_task和pick _next_ task ;而理解进程的切换,核心是context_switch。下面就分两条线索,分别说明进程的切换和调度的流程。
二、实验过程

上面就是这几周一直在做的大小S啦,大家都懂的吧~调试跟踪内核启动么~。然后我们在进入一个新的终端控制台输入gdb开始调试啊,设置监视,加载文件符号表啊什么的,这都很简单的吧。

按照惯例我们开始设置断点了当然就是要设置到那个schedule函数上了刚才分析过了。然后我们开到程序只想到可2866之后停了下来。然后我们看到在2867的地方有一个赋值过程就是讲当前的任务信息拷贝到任务结构体中,继续输入list我们就可以看到更多的代码了。

继续向下我们看到有一个设置当先进程状态的语句在499那个地方。就是调度之后将进程状态设置为正在运行。

然后我们又看到了自旋锁这个东西,这个不用说了吧,为什么要有呢。实际上在调度的过程中很多和上下文保存和切换的时候是不能被打断的,这个行为是非抢占的所以要有一些机制保证他不会被打断,同时这个过程有经常发生,所以我们不能用过于复杂的同步技术,自旋锁作为轻量级的同步工具这里就比较合适了(那位说了上次在之前的切换的文章里面你不就说要单说说自旋锁的咩,啃啃笔者是个说话算数的人,当时说的时候也强调了有机会~好么)

其实在2831之后也是这种赋值的语句用于给当前的任务做切换用,然后就有又会进入下一次的schedule了。
三、总结
进程的调度少不了进程的切换,中做的关键操作是:切换地址空间、切换内核堆栈、切换内核控制流程,加上一些必要的寄存器保存和恢复。这里,除去地址空间的切换,其他操作要强调“内核”一词。这是因为,这些操作并非针对用户代码,切换完成后,也没有立即跑到next的用户空间中执行。用户上下文的保存和恢复是通过中断和异常机制,在内核态和用户态相互切换时才发生的。从这个意义上讲,切换地址空间才是本质上想要达到的“用户代码和数据的切换”,其余的切换不过是内核中不同的控制流程在“交接棒”而已。进程切换这里当初领会起来比较难,但是一旦理解,就会深深佩服这一系列过程的巧妙。特别是switch_to宏,几乎就是多一句嫌多,少一句嫌少。
看源代码我们知道schedule这个函数的中心环节是一个for循环,它遍历sched_class的每一个实例,并依次调用各个实例的pick_next_task函数。若返回非空,则将下一个进程设为它。由此可见,Linux调度系统采用的是操作系统理论中的多级队列调度,且上一个队列中进程的优先级恒比下一个队列中进程高。本文第一部分已述,sched_ class 链表依次为rt、fair、idle。因此,只要有rt类型进程就绪,调度时就一定会被选择,从而保证了rt类型进程的实时性。注释中还提到一点,idle队列中一定非空,因此在前两个类型的进程都没有就绪时,idle中的idle进程一定会被选中并调度,这保证了循环一定能终止。这里可以看到系统idle进程的重要性。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









